

Since 2015, the Cloudera DataFlow team has been helping the largest enterprise organizations in the world adopt Apache NiFi as their enterprise standard data movement tool. Over the last few years, we have had a front-row seat in our customers’ hybrid cloud journey as they expand their data estate across the edge, on-premise, and multiple cloud providers. This unique perspective of helping customers move data as they traverse the hybrid cloud path has afforded Cloudera a clear line of sight to the critical requirements that are emerging as customers adopt a modern hybrid data stack.
One of the critical requirements that has materialized is the need for companies to take control of their data flows from origination through all points of consumption both on-premise and in the cloud in a simple, secure, universal, scalable, and cost-effective way. This need has generated a market opportunity for a universal data distribution service.
Over the last two years, the Cloudera DataFlow team has been hard at work building Cloudera DataFlow for the Public Cloud (CDF-PC). CDF-PC is a cloud native universal data distribution service powered by Apache NiFi on Kubernetes, allowing developers to connect to any data source anywhere with any structure, process it, and deliver to any destination.
This blog aims to answer two questions:
- What is a universal data distribution service?
- Why does every organization need it when using a modern data stack?
In a recent customer workshop with a large retail data science media company, one of the attendees, an engineering leader, made the following observation:
“Everytime I go to your competitor website, they only care about their system. How to onboard data into their system? I don’t care about their system. I want integration between all my systems. Each system is just one of many that I’m using. That’s why we love that Cloudera uses NiFi and the way it integrates between all systems. It’s one tool looking out for the community and we really appreciate that.”
The above sentiment has been a recurring theme from many of the enterprise organizations the Cloudera DataFlow team has worked with, especially those who are adopting a modern data stack in the cloud.
What is the modern data stack? Some of the more popular viral blogs and LinkedIn posts describe it as the following:
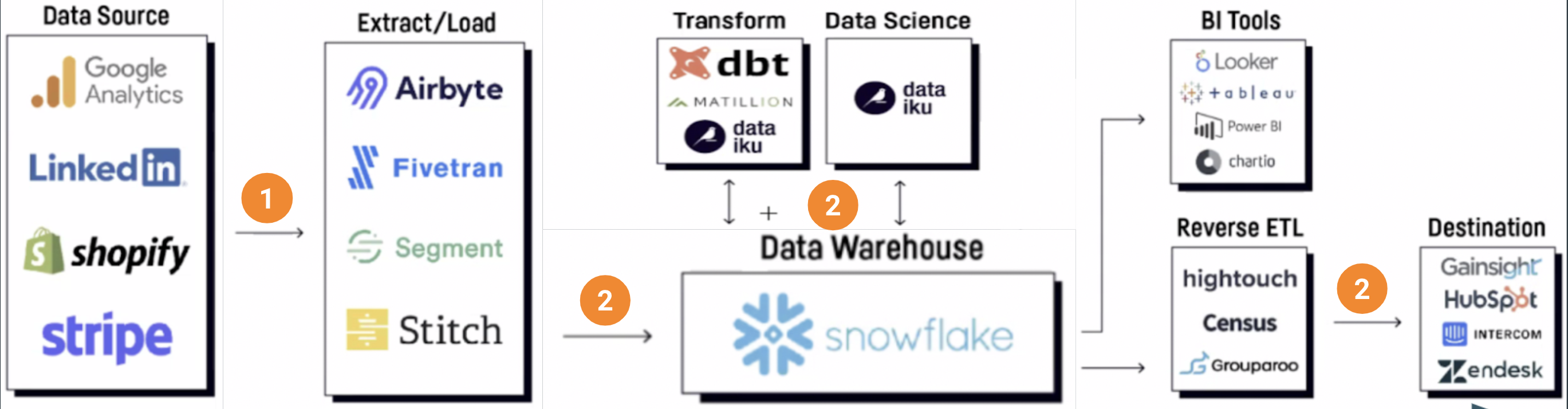
A few observations on the modern stack diagram:
- Note the number of different boxes that are present. In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
- The newer “extract/load” tools seem to focus primarily on cloud data sources with schemas. However, based on the 2000+ enterprise customers that Cloudera works with, more than half the data they need to source from is born outside the cloud (on-prem, edge, etc.) and don’t necessarily have schemas.
- Numerous “extract/load” tools need to be used to move data across the ecosystem of cloud services.
We’ll drill into these points further.
Companies have not treated the collection and distribution of data as a first-class problem
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created. What is less frequently mentioned is that during this same time we have also seen a rapid increase of cloud services where data needs to be delivered (data lakes, lakehouses, cloud warehouses, cloud streaming systems, cloud business processes, etc.). Use cases demand that data no longer be distributed to just a data warehouse or subset of data sources, but to a diverse set of hybrid services across cloud providers and on-prem.
Companies have not treated the collection, distribution, and tracking of data throughout their data estate as a first-class problem requiring a first-class solution. Instead they built or purchased tools for data collection that are confined with a class of sources and destinations. If you take into account the first observation above—that customer source systems are never just limited to cloud structured sources—the problem is further compounded as described in the below diagram:
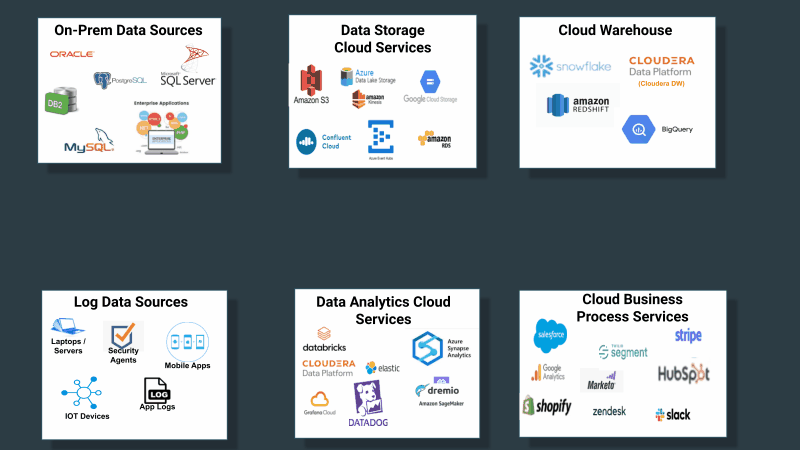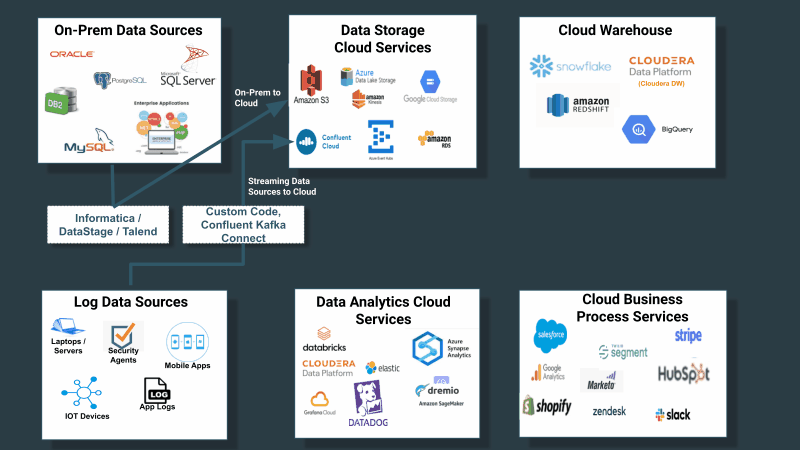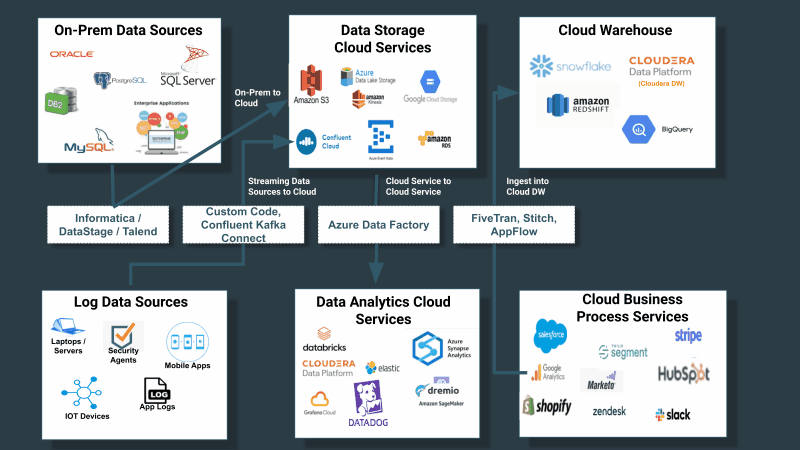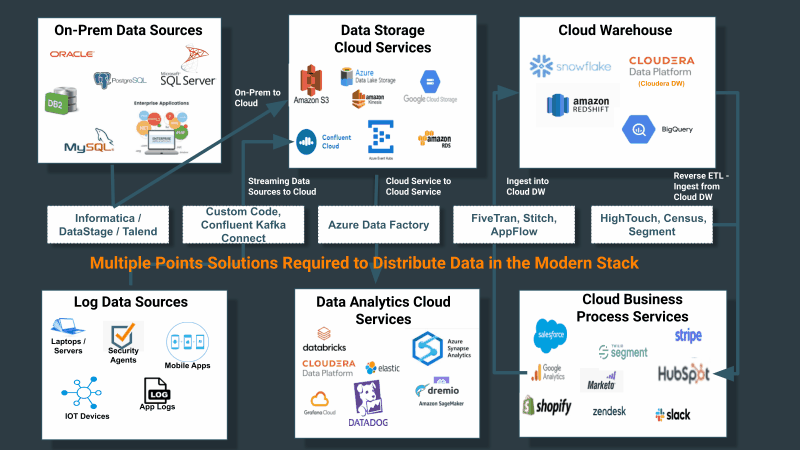
The need for a universal data distribution service
As cloud services continue to proliferate, the current approach of using multiple point solutions becomes intractable.
A large oil and gas company, who needed to move streaming cyber logs from over 100,000 edge devices to multiple cloud services including Splunk, Microsoft Sentinel, Snowflake, and a data lake, described this need perfectly:
“Controlling the data distribution is critical to providing the freedom and flexibility to deliver the data to different services.”
Every organization on the hybrid cloud journey needs the ability to take control of their data flows from origination through all points of consumption. As I stated in the start of the blog, this need has generated a market opportunity for a universal data distribution service.

What are the key capabilities that a data distribution service has to have?
- Universal Data Connectivity and Application Accessibility: In other words, the service needs to support ingestion in a hybrid world, connecting to any data source anywhere in any cloud with any structure. Hybrid also means supporting ingestion from any data source born outside of the cloud and enabling these applications to easily send data to the distribution service.
- Universal Indiscriminate Data Delivery: The service should not discriminate where it distributes data, supporting delivery to any destination including data lakes, lakehouses, data meshes, and cloud services.
- Universal Data Movement Use Cases with Streaming as First-Class Citizen: The service needs to address the entire diversity of data movement use cases: continuous/streaming, batch, event-driven, edge, and microservices. Within this spectrum of use cases, streaming has to be treated as a first-class citizen with the service able to turn any data source into streaming mode and support streaming scale, reinforcing hundreds of thousands of data-generating clients.
- Universal Developer Accessibility: Data distribution is a data integration problem and all the complexities that come with it. Dumbed down connector wizard–based solutions cannot address the common data integration challenges (e.g: bridging protocols, data formats, routing, filtering, error handling, retries). At the same time, today’s developers demand low-code tooling with extensibility to build these data distribution pipelines.
Cloudera DataFlow for the Public Cloud, a universal data distribution service powered by Apache NiFi
Cloudera DataFlow for the Public Cloud (CDF-PC), a cloud native universal data distribution service powered by Apache NiFi, was built to solve the data collection and distribution problem with the four key capabilities: connectivity and application accessibility, indiscriminate data delivery, streaming data pipelines as a first class citizen, and developer accessibility.
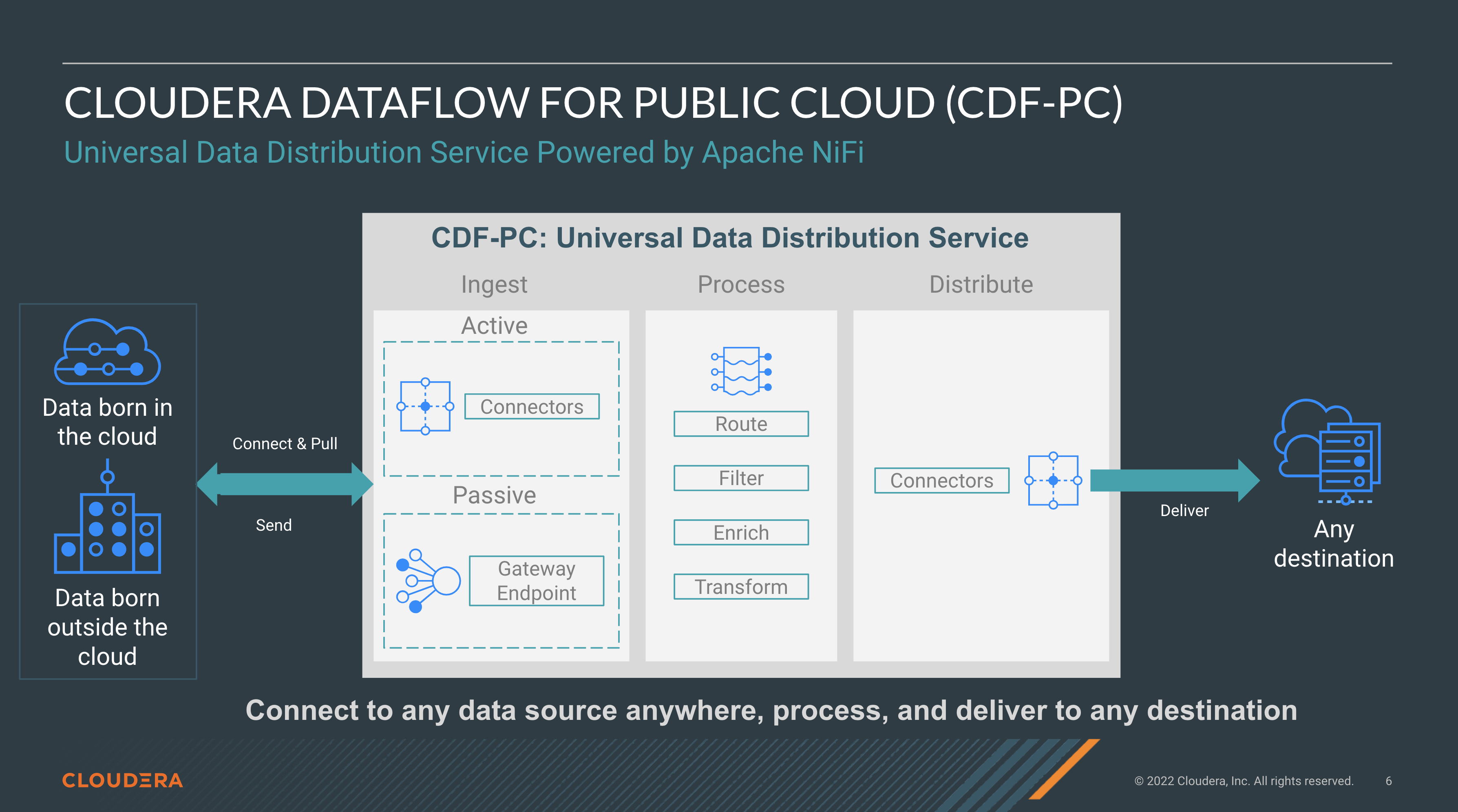
CDF-PC offers a flow-based low-code development paradigm that provides the best impedance match with how developers design, develop, and test data distribution pipelines. With over 400+ connectors and processors across the ecosystem of hybrid cloud services including data lakes, lakehouses, cloud warehouses, and sources born outside the cloud, CDF-PC provides indiscriminate data distribution. These data distribution flows can then be version controlled into a catalog where operators can self-serve deployments to different runtimes including cloud providers’ kubernetes services or function services (FaaS).
Organizations use CDF-PC for diverse data distribution use cases ranging from cyber security analytics and SIEM optimization via streaming data collection from hundreds of thousands of edge devices, to self-service analytics workspace provisioning and hydrating data into lakehouses (e.g: Databricks, Dremio), to ingesting data into cloud providers’ data lakes backed by their cloud object storage (AWS, Azure, Google Cloud) and cloud warehouses (Snowflake, Redshift, Google BigQuery).
In subsequent blogs, we’ll deep dive into some of these use cases and discuss how they are implemented using CDF-PC.
Get Started Today
Wherever you are on your hybrid cloud journey, a first class data distribution service is critical for successfully adopting a modern hybrid data stack. Cloudera DataFlow for the Public Cloud (CDF-PC) provides a universal, hybrid, and streaming first data distribution service that enables customers to gain control of their data flows.
Take our interactive product tour to get an impression of CDF-PC in action or sign up for a free trial.
Editor's Choice

