


This post was authored by guest author Cheng Xu, Senior Architect (Intel), as well as Adar Lieber-Dembo, Principal Engineer (Cloudera) and Greg Solovyev, Engineering Manager (Cloudera)
Overview
Intel Optane DC persistent memory (Optane DCPMM) has higher bandwidth and lower latency than SSD and HDD storage drives. These characteristics of Optane DCPMM provide a significant performance boost to big data storage platforms that can utilize it for caching. One of such platforms is Apache Kudu that can utilize DCPMM for its internal block cache. To test this assumption, we used YCSB benchmark to compare how Apache Kudu performs with block cache in DRAM to how it performs when using Optane DCPMM for block cache. In order to get maximum performance for Kudu block cache implementation we used the Persistent Memory Development Kit (PMDK).
Kudu Block Cache
Apache Kudu is an open source columnar storage engine, which enables fast analytics on fast data. Kudu Tablet Servers store and deliver data to clients. Each Tablet Server has a dedicated LRU block cache, which maps keys to values. Kudu block cache uses internal synchronization and may be safely accessed concurrently from multiple threads. It may automatically evict entries to make room for new entries. If the data is not found in the block cache, it will read from the disk and insert into block cache. For the persistent memory block cache, we allocated space for the data from persistent memory instead of DRAM.
Some benefits from persistent memory block cache:
- Reduce DRAM footprint required for Apache Kudu
- Keep performance as close to DRAM speed as possible
- Take advantage of larger cache capacity to cache more data and improve the entire system’s performance
Intel Optane DC Persistent Memory
Intel Optane DC persistent memory (Optane DCPMM) breaks the traditional memory/storage hierarchy and scales up the compute server with higher capacity persistent memory. It has higher bandwidth & lower latency than storage like SSD or HDD and performs comparably with DRAM. DCPMM provides two operating modes: Memory and App Direct.
Memory mode is volatile and is all about providing a large main memory at a cost lower than DRAM without any changes to the application, which usually results in cost savings.
App Direct mode allows an operating system to mount DCPMM drive as a block device. This is the mode we used for testing throughput and latency of Apache Kudu block cache.
PMDK
The Persistent Memory Development Kit (PMDK), formerly known as NVML, is a growing collection of libraries and tools. Tuned and validated on both Linux and Windows, the libraries build on the DAX feature of those operating systems (short for Direct Access) which allows applications to access persistent memory as memory-mapped files. More detail is available at https://pmem.io/pmdk/. Memkind combines support for multiple types of volatile memory into a single, convenient API. Since support for persistent memory has been integrated into memkind, we used it in the Kudu block cache persistent memory implementation.
YCSB
The Yahoo! Cloud Serving Benchmark (YCSB) is an open-source test framework that is often used to compare relative performance of NoSQL databases.
Performance Analysis
To evaluate the performance of Apache Kudu, we ran YCSB read workloads on two machines. One machine had DRAM and no DCPMM. The other machine had both DRAM and DCPMM. Below is the summary of hardware and software configurations of the two machines:
| Config1 – DRAM | Config2 – DCPMM | |
| OS | Fedora | Fedora |
| Kernel | 4.20.6-200.fc29.x86_64 | 4.20.6-200.fc29.x86_64 |
| Software versions | Apache Kudu 1.11.0 | Apache Kudu 1.11.0 |
| ycsb 0.16.0 | ycsb 0.16.0 | |
| Storage – application drivers | 8x 1.1TB Intel SSDSC2BB01 | 8x 1.1TB Intel SSDSC2BB01 |
Kudu-specific flag values
| Config1 – DRAM | Config2 – DCPMM | |
| maintenance_manager_num_threads | 4 | 4 |
| block_cache_type | DRAM | NVM |
| block_cache_capacity_mb | 550000 | 920000 |
YCSB configuration
We tested two datasets: Small (100GB) and large (700GB). Below is the YCSB workload properties for these two datasets. The small dataset is designed to fit entirely inside Kudu block cache on both machines. The large dataset is designed to exceed the capacity of Kudu block cache on DRAM, while fitting entirely inside the block cache on DCPMM.
| Small (100GB) | Large (700GB) | |
| readallfields | TRUE | TRUE |
| readproportion | 1 | 1 |
| updateproportion | 0 | 0 |
| scanproportion | 0 | 0 |
| insertproportion | 0 | 0 |
| fieldlength | 10000 | 30000 |
| fieldcount | 100 | 200 |
(Test executed in Nov 2019)
Results
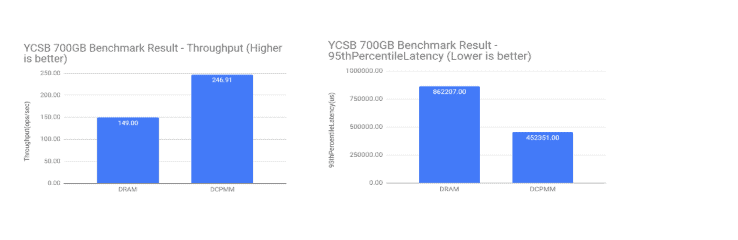
For large (700GB) test (dataset larger than DRAM capacity but smaller than DCPMM capacity), DCPMM-based configuration showed about 1.66X gain in throughput over DRAM-based configuration. When measuring latency of reads at the 95th percentile (reads with observed latency higher than 95% all other latencies) we have observed 1.9x gain in DCPMM-based configuration compared to DRAM-based configuration.
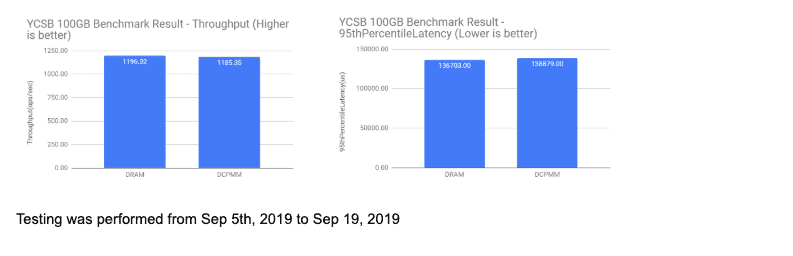
For small (100GB) test (dataset smaller than DRAM capacity), we have observed similar performance in DCPMM and DRAM-based configurations.
Misc
Currently the Kudu block cache does not support multiple nvm cache paths in one tablet server. So we need to bind two DCPMM sockets together to maximize the block cache capacity. Refer to https://pmem.io/2018/05/15/using_persistent_memory_devices_with_the_linux_device_mapper.html
Conclusion
DCPMM modules offer larger capacity for lower cost than DRAM. This allows Apache Kudu to reduce the overhead by reading data from low bandwidth disk, by keeping more data in block cache. YCSB workload shows that DCPMM will yield about a 1.66x performance improvement in throughput and 1.9x improvement in read latency (measured at 95%) over DRAM. Kudu is a powerful tool for analytical workloads over time series data. Adding DCPMM modules for Kudu block cache could significantly speed up queries that repeatedly request data from the same time window. You can find more information about Time Series Analytics with Kudu on Cloudera Data Platform at https://www.cloudera.com/campaign/time-series.html.
Notices & Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice Revision #20110804
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available security updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Editor's Choice

