

Editor’s Note, August 2020: CDP Data Center is now called CDP Private Cloud Base. You can learn more about it here.
Introduction
Motivation
Bringing your own libraries to run a Spark job on a shared YARN cluster can be a huge pain. In the past, you had to install the dependencies independently on each host or use different Python package management softwares. Nowadays Docker provides a much simpler way of packaging and managing dependencies so users can easily share a cluster without running into each other, or waiting for central IT to install packages on every node. Today, we are excited to announce the preview of Spark on Docker on YARN available on CDP DataCenter 1.0 release.
In this blog post we will:
- Show some use cases how users can vary Python versions and libraries for Spark applications.
- Demonstrate the capabilities of the Docker on YARN feature by using Spark shells and Spark submit job.
- Peek into the architecture of Spark and how YARN can run parts of Spark in Docker containers in an effective and flexible way.
- Guide to show how to use this feature with CDP Data Center release.
Potential benefits
The benefits from Docker are well known: it is lightweight, portable, flexible and fast. On top of that using Docker containers one can manage all the Python and R libraries (getting rid of the dependency burden), so that the Spark Executor will always have access to the same set of dependencies as the Spark Driver for instance.
Configurations to run Spark-on-Docker-on-YARN
YARN
Marking nodes supporting Docker containers
For bigger clusters it may be a real challenge to install, upgrade and manage Docker binaries and daemons. For a large scale one can benefit from the NodeLabels feature of YARN.
Labelling the nodes that are supporting Docker enables the user to enforce that Docker containers will only be attempted to be scheduled in hosts where Docker daemon is running. In this way Docker can be installed to the hosts in a rolling fashion making easier to benefit sooner from this feature.
Environment variables
The runtime that will be used to launch the container is specified via an environment variable at application submission time. As you can see later YARN_CONTAINER_RUNTIME_TYPE will be set to “docker” – in this case, the container will be started as a Docker container instead of a regular process.
Note that this environment variable only needs to be present during container start, so we can even set this through the SparkContext object in a Python script for instance (see “When to provide configurations?” below) – which is runtime. This provides much more flexibility for the user.
Significant environment variables:
- YARN_CONTAINER_RUNTIME_TYPE: responsible for selecting the runtime of the container – to run a regular container, set this to “default”.
- YARN_CONTAINER_RUNTIME_DOCKER_IMAGE: you need a docker image on which you run your container. Using YARN_CONTAINER_RUNTIME_DOCKER_RUN_OVERRIDE_DISABLE you can override the Docker image’s default command.
- YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS: specifying the mounts for the application.
Users can provide multiple mounts, separated by a comma. Also each mount should have the “source path:destination path in the Docker container:type”, where type should be either ro or rw representing the read-only and read-write mounts.
- As a best practice you may want to separate your running Spark Docker containers from the host network by specifying the YARN_CONTAINER_RUNTIME_DOCKER_CONTAINER_NETWORK environment variable.
More properties like privileged mode, ports mapping, delayed removal can be found in the upstream documentation [1].
Spark configurations
There are multiple ways to add these environment variables available at container start time. Using YARN master you can add environment variables for the Spark Application Master by specifying it like this:
spark.yarn.appMasterEnv.<variable>=<value>
and also to the containers of the Spark Executors:
spark.executorEnv.<variable>=value
Note that you can specify a different container for the executors than the one that the Driver runs in. Thus you can also play with the dependencies just like in Demo I. (where we didn’t have numpy locally installed).
When to provide configurations?
Just as a Spark shell is started or a Spark job is submitted the client can specify extra configuration options with the –conf option (see Demo I., II., III.).
After a Spark job (e.g a Python script) has been submitted to the cluster, the client cannot change the environment variables of the container of the Application Master. The Spark Driver in this case runs in the same container as the Application Master, therefore providing the appropriate environment option is only possible at submission time.
In spite of the above, the spawning of Spark Executors can be modified at runtime. After initializing the SparkContext object one can change the spark.executorEnv configuration option to add the Docker related ones (see version.py or ols.py).
Timeout
Due to Docker image localization overhead you may have to increase the Spark network timeout:
spark.network.timeout=3000
We have experienced some extra latency while the Docker container got ready mainly due to the Docker image pull operation. The timeout needed to be increased so that we wait long enough to the AM and the executors to come alive and start communicating with each other.
Mount points
The NodeManager’s local directory is mounted to the Docker container by default. It is particularly important for the Spark shuffle service to leverage multiple disks (if configured) for performance.
You should probably need the /etc/passwd mount points for the Application Master to access the UNIX user and group permissions. Be careful to only do that in Read-Only mode!
Another mounting point is /opt/cloudera/parcels that enables access to the host machine’s jars so that the Spark jars don’t have to be built into the Docker image. While it is possible to replace, Cloudera recommends to mount these tested jars from the hosts, and not to include custom Spark jars with different versions in the Docker images that may be unsupported or can potentially have integration problems.
In a kerberized cluster the container should access the kerberos configuration file, usually stored in /etc/krb5.conf.
Spark architecture
Before we turn to the demos, let’s dig into the Spark architecture by examining the differences between Client and Cluster mode. We’re doing that by using YARN master, so we do not concern local mode. You can use local mode as well by simply starting a PySpark session in a Docker image, but this part will not be covered in this article as that is unrelated to the Docker on YARN feature.
Client mode
In YARN client mode, the driver runs in the submission client’s JVM on the gateway machine. A typical usage of Spark client mode is Spark-shell.
The YARN application is submitted as part of the initialization of the SparkContext object by the driver. In YARN Client mode the ApplicationMaster is a proxy for forwarding YARN allocation requests, container status, etc., from and to the driver.
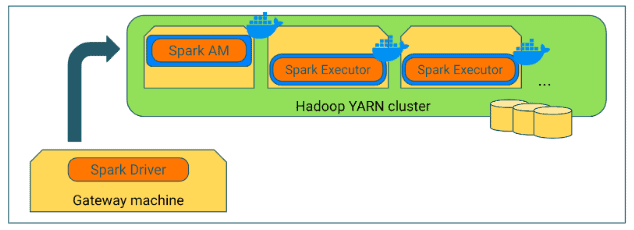
In this mode, the Spark driver runs on the gateway machine as a Java process, and not in a YARN container. Hence, specifying any driver-specific YARN configuration to use Docker or Docker images will not take effect. Only Spark executors will run in Docker containers.
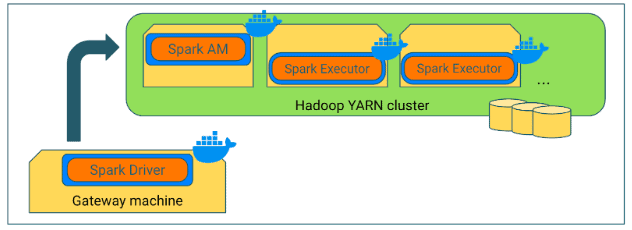
However, it is possible to run the Spark Driver on the gateway machine inside a Docker container – which may even be the same Docker image as the Drivers. The flaw of this method is that users should have direct access to Docker on the gateway machine, which is usually not the case.
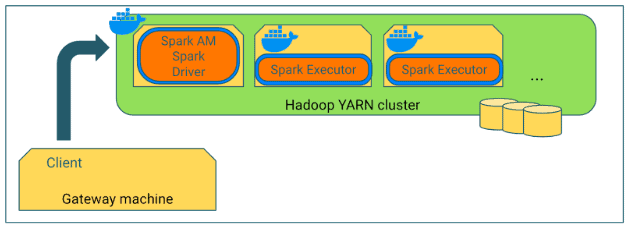
Cluster mode
In YARN cluster mode a user submits a Spark job to be executed, which is scheduled and executed by YARN. The ApplicationMaster hosts the Spark driver, which is launched on the cluster in a Docker container.
Along with the executor’s Docker container configurations, the Driver/AppMaster’s Docker configurations can be set through environment variables during submission. Note that the driver’s Docker image can be customized with settings that are different than the executor’s image.
One can also set the name of the Docker image of the Spark Executor during runtime by initializing the SparkContext object appropriately. This can be used, for instance, to write a script that can handle its own dependencies by specifying the image during runtime depending on the executors’ needs. If the script is going to run workloads involving a specific dependency but not using another one, it’s sufficient to specify a Docker image for the Spark Executors that only contains that specific library and does not contain the other one.
Demos
A data scientist can benefit from this feature during every step of the development lifecycle of a certain model: during experimentation (see Demo I.), preparing for official runs (see Demo II.) and deploying to production (see Demo III.).
About requirements including supported OSes and Docker version, visit the Cloudera docs.
Prerequisites
- Ensure Docker is installed on all hosts and the Docker daemon is running.
- Enable the Docker on YARN feature in Cloudera Manager.
- Use Linux Container Executor.
- Add Docker to the Allowed Runtimes.
- Enable Docker Containers.
- Save changes and restart YARN.
Demo I.
Running PySpark on the gateway machine with Dockerized Executors in a Kerberized cluster.
Steps
- Prepare Docker image (python2:v1) with the dependencies installed.
- Save python2:v1 to a file named Dockerfile and build it with the “docker build” command in a command line.
- Publish the built Docker image to a registry. If the Docker image is public (these are) login into your Docker Hub account, and use the “docker push” command to upload to Docker Hub.
- Open the Cloudera Manager UI and navigate to YARN->Configuration.
- Add the registry of your image (name of your Docker Hub account) to the list of trusted registries.
- Add mounts /etc/passwd, /etc/krb5.conf and /opt/cloudera/parcels to the List of Allowed Read-Only Mounts.
- Save changes and restart YARN.
- Initialize kerberos credentials. Typically by typing the following command to a command line in one of the cluster’s hosts.
sudo -u user kinit -kt /keytabs/user.keytab -l 30d -r 30d user
- Start PySpark session using the command below in a command line.
- Type in the Python commands from dependencies.py.
Command
sudo -u user pyspark \ --master yarn \ --executor-memory 4G \ --num-executors 2 \ --conf spark.network.timeout=3000 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python2:v1 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro,/etc/krb5.conf:/etc/krb5.conf:ro" \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python2:v1 \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro,/etc/krb5.conf:/etc/krb5.conf:ro"
Output
Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.0.7.0.3 /_/ Using Python version 2.7.5 (default, Jul 13 2018 13:06:57) SparkSession available as 'spark'. >>> def inside(p): ... import numpy as np ... return np.cos(np.pi * p / 2) > 0.5 ... >>> inside(0) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in inside ImportError: No module named numpy >>> num_samples = 100000 >>> count = sc.parallelize(range(0, num_samples)).filter(inside).count() [Stage 0:> (0 + 0) / 2] >>> print(count) 25000
Demo II.
Running Dockerized PySpark on the gateway machine with Dockerized Executors in a non-kerberized cluster.
Steps
- Prepare Docker image (python2:v2) with the dependencies installed.
- Save python2:v2 to a file named Dockerfile and build it with the “docker build” command in a command line.
- Publish the built Docker image to a registry. If the Docker image is public (these are) login into your Docker Hub account, and use the “docker push” command to upload to Docker Hub.
- Open the Cloudera Manager UI and navigate to YARN->Configurations.
- Add the registry of your image (name of your Docker Hub account) to the list of trusted registries.
- Add mounts /etc/passwd and /opt/cloudera/parcels to the List of Allowed Read-Only Mounts.
- Save changes and restart YARN.
- Start PySpark session using the command below in a command line.
Command
docker run \ -v /etc/spark:/etc/spark:ro \ -v /etc/alternatives:/etc/alternatives:ro \ -v /etc/hadoop:/etc/hadoop:ro \ -v /opt/cloudera/parcels/<parcel_directory>:/opt/cloudera/parcels/<parcel_directory>/:ro \ --network host \ -a stdin -a stdout -a stderr -i -t \ antaladam/python2:v2 \ /opt/cloudera/parcels/<parcel_directory>/bin/pyspark \ --master yarn \ --executor-memory 4G \ --num-executors 4 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python2:v2 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro" \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python2:v2 \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro"
Mounts
In the command above multiple mounts were specified – /etc/spark is needed to pick up the YARN related configurations, /etc/hadoop contains the topology script that Spark uses and /etc/alternatives contains the symlinks to the other two folders.
Demo III.
Submitting Spark application with different Python version using Docker containers.
Steps
- Prepare Docker image (python3:v1) with the dependencies installed.
- Save python3:v1 to a file named Dockerfile and build it with the “docker build” command in a command line.
- Publish the built Docker image to a registry. If the Docker image is public (these are) login into your Docker Hub account, and use the “docker push” command to upload to Docker Hub.
- Open the Cloudera Manager UI and navigate to YARN->Configurations.
- Add the registry of your image (name of your Docker Hub account) to the list of trusted registries.
- Add /etc/passwd, /etc/hadoop and /opt/cloudera/parcels to the Allowed Read-Only Mounts for Docker Containers.
- Save changes and restart YARN.
- Select an arbitrary Python 3 application (example: ols.py).
- Submit the script as a Spark application using the command below in a command line.
- Check the output of the application in the Spark History Server UI.
Command
spark-submit \ --master yarn \ --deploy-mode cluster \ --executor-memory 4G \ --num-executors 4 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python3:v1 \ --conf spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/etc/hadoop:/etc/hadoop:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro" \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=antaladam/python3:v1 \ --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS="/etc/passwd:/etc/passwd:ro,/etc/hadoop:/etc/hadoop:ro,/opt/cloudera/parcels/:/opt/cloudera/parcels/:ro" \ ols.py
Resources
Dockerfiles
Choosing the base image
Spark only contains jars, but no native code pieces. On the other hand, Hadoop has native libraries: HDFS native client and the Container Executor code of YARN are two significant ones. The former has major importance and is recommended due to performance reasons, the latter is only required by the NodeManager to start containers (Docker containers too). Other storages like HBase or Kudu may also have native code pieces.
Mounting does not take into account the fact that we can link some potentially incompatible binaries from another OS, therefore it’s the application developer’s responsibility to pay attention to this potential error. Mounting incompatible binaries can be catastrophous and may potentially corrupt the application.
As an example, the CDP’s parcel folder contains a /jar directory which is safe to mount since it contains only jars, but the /bin containing binaries is dangerous if another OS is used as a base image. For this reason Cloudera recommends to use the same OS but perhaps in a different version (preferred) OR include the binaries with the image and limit mounting binaries from the host.
python2:v1
FROM centos RUN yum -y install python27 RUN yum -y install wget ENV PYSPARK_PYTHON python2.7 ENV PYSPARK_DRIVER_PYTHON python2.7 RUN ln -s /usr/bin/python2.7 /usr/local/bin/python RUN wget https://bootstrap.pypa.io/get-pip.py RUN python get-pip.py RUN pip2.7 install numpy RUN yum -y install java-1.8.0-openjdk ENV JAVA_HOME /usr/lib/jvm/jre
Some things to add here:
- We needed to add the environment variable PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON for the Spark to pick it up.
python2:v2
FROM centos RUN yum -y install python27 RUN yum -y install wget ENV PYSPARK_PYTHON python2.7 ENV PYSPARK_DRIVER_PYTHON python2.7 RUN ln -s /usr/bin/python2.7 /usr/local/bin/python RUN wget https://bootstrap.pypa.io/get-pip.py RUN python get-pip.py RUN pip2.7 install numpy RUN yum -y install java-1.8.0-openjdk ENV JAVA_HOME /usr/lib/jvm/jre-<openJDK version>
Some things to add here:
- We needed to add the environment variable PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON for the Spark to pick it up.
- We also had to explicitly define the JAVA_HOME binary, due to the collision of the PATH environment variable (can conflict in the host and in the Docker image).
python3:v1
FROM centos RUN yum -y install python36 RUN yum -y install wget ENV PYSPARK_PYTHON python3.6 ENV PYSPARK_DRIVER_PYTHON python3.6 RUN ln -s /usr/bin/python3.6 /usr/local/bin/python RUN wget https://bootstrap.pypa.io/get-pip.py RUN python get-pip.py RUN pip3.6 install numpy RUN pip3.6 install pandas RUN pip3.6 install --upgrade statsmodels RUN yum -y install java-1.8.0-openjdk ENV JAVA_HOME /usr/lib/jvm/jre
Scripts
dependencies.py
def inside(p): # Function that uses numpy internally import numpy as np return np.cos(np.pi * p / 2) > 0.5 inside(0) # Expected to fail num_samples = 100000 count = sc.parallelize(range(0, num_samples)).filter(inside).count() # Works without problem print(count) # 25000 is expected
version.py
# Imports import sys from pyspark import SparkConf, SparkContext # Establishing connection to Spark conf = SparkConf().setAppName("Version app").setMaster("yarn") sc = SparkContext(conf=conf) # Printing to python if sys.version_info[0] == 3: print("Python 3") elif sys.version_info[0] == 2: print("Python 2")
ols.py
# Imports from pyspark import SparkConf, SparkContext import pandas as pd import statsmodels.formula.api as sm # Establishing connection to Spark conf = SparkConf().setAppName("OLS app").setMaster("yarn") sc = SparkContext(conf=conf) # Example dataframe where A ~ 2 * B - A + 1 df = pd.DataFrame({"A": [20, 7.2, 9.8, 7, 10.2], "B": [10, 4, 6, 5, 7], "C": [1, 2, 3, 4, 5]}) # Fitting a linear regression model on the data result = sm.ols(formula="A ~ B + C", data=df).fit() # Displaying results print(result.params) # Displaying metrics of the fit print(result.summary())
Availability
Note that this feature is in beta stage in CDP Data Center 7.0 and will be GA in the near future.
Future improvements
Supporting Dockerization in a bit more user friendly way: https://issues.apache.org/jira/browse/SPARK-29474
Using Docker images has lots of benefits, but on the other hand one potential drawback is the overhead of managing them. Users must make these images available at runtime, so a secure publishing method must be established. Also a user must choose between a publicly available or a private Docker repository to share these images.
We’re currently working on supporting canonical Cloudera-created base Docker images for Spark. Using these images one would not have to mount the Cloudera parcel folder to the Docker image. Utilizing base images with the necessary dependencies also installed in the image, the parcel mount point is no longer needed. In short, it increases encapsulation.
Improve the health diagnostics of a node by detecting not running Docker daemon: https://issues.apache.org/jira/browse/YARN-9923
Further reading
[1] Apache Hadoop Document: “Launching Applications Using Docker Containers”
[2] HDP Document about Spark on Docker on YARN[3] Check out our brand new CDP documentation!
- How to configure Docker on YARN using Cloudera Manager
- Check out our Troubleshooting Catalog for common errors
Authors note: I would like to thank for the meaningful reviews and conversations to: Liliana Kadar, Imran Rashid, Tom Deane, Wangda Tan, Shane Kumpf, Marcelo Vanzin, Attila Zsolt Piros, Szilard Nemeth, Peter Bacsko.
Editor's Choice

