

Introduction:
System maintenance operations such as updating operating systems, and applying security patches or hotfixes are routine operations in any data center. DataNodes undergoing such maintenance operations can go offline for anywhere from a few minutes to several hours. By design, Apache Hadoop HDFS can handle DataNodes going down. However, any uncoordinated maintenance operations on several DataNodes at the same time could lead to temporary data availability issues. HDFS currently supports the following features for performing planned maintenance activity:
- Rolling Upgrade
- Decommission
- HDFS supports using Maintenance State (Starting with CDH 5.11)
The rolling upgrade process helps to upgrade the cluster software without taking the cluster offline. When many DataNodes from the same or different racks go down for upgrades, it is preferable to choose the DataNodes in such a way that the replica availability for blocks and files is not compromised. However, there is no easy way to achieve that.
HDFS supports the Decommission feature to alleviate the data availability problems encountered during rolling upgrade scenarios. When decommissioning is requested for DataNodes, the NameNode transitions them to the decommission in-progress state where all of their blocks are replicated onto other live DataNodes in order to satisfy the global block replication configured with the dfs.replication property or the file-specific replication configuration. When all these replicas are sufficiently replicated to other DataNodes, the NameNode transitions DataNodes in the decommission in-progress state to the final decommissioned state.
Decommission, when run for several DataNodes at the same time, can be time consuming because it has to complete sufficient replication for all blocks on all of the DataNodes. An example of this would be performing maintenance operations across an entire rack. Decommissioning could also increase network usage in the cluster and could affect performance SLAs.
Maintenance State:
Upstream Jira: HDFS-7877
Design: Doc
The new feature, HDFS Maintenance State, aims to overcome the drawbacks of Rolling Upgrade and Decommission features and make the planned maintenance activity much more seamless. The Maintenance State feature applies only to HDFS DataNode roles.
The Maintenance State feature avoids unnecessary replication of blocks by allowing the block replication factor to be less than the configured level for a temporary period of time. That is, it doesn’t schedule replication right away for blocks on DataNodes requesting maintenance activity. Even when these DataNodes are down for maintenance, the cluster continues to run using the minimum replication limit (configurable and discussed later) for replicas instead of the desired level set by the global block replication factor or the file-specific replication factor.
A short duration maintenance activity such as batch rolling upgrades or repairing a top of rack switch are among the best fit use cases for this feature.
Let’s first take a look at the configuration before diving more deeply into the feature.
Configuration:
dfs.namenode.maintenance.replication.min:
This NameNode configuration defines the minimal number of live replicas that all blocks of DataNodes undergoing maintenance need to satisfy. For DataNodes in maintenance state, when all of their blocks have at least this minimum replicas on other live DataNodes, then no replications are triggered. Otherwise, replications will be triggered to satisfy this criteria. The allowed range for this configuration is [0 to dfs.replication].
Maintenance State minimum replication factor of 1 means a cluster can function with just 1 live replica for the configured duration for blocks belonging to DataNodes under maintenance. If a block’s only replica exists on the DataNode that is about to go into maintenance State, the feature makes sure the replica is sufficiently replicated to another DataNode first to ensure better data availability.
When the Maintenance State minimum replication factor equals the global replication factor, the cluster needs at least dfs.replication replica blocks even when the DataNodes are under maintenance, which causes the Maintenance state feature to behave like the Decommission feature when it triggers re-replication.
A Maintenance State minimum replication factor of 0 means the NameNode does not verify any minimum replication factor for the blocks on the DataNodes undergoing maintenance. An administrator might prefer setting this value for maintenance minimum replication factor in order to speed up the maintenance operation by avoiding the replica scan, but this raises the risk of data becoming unreachable.
dfs.namenode.hosts.provider.classname:
This NameNode configuration specifies the class that provides access for hosts files. Prior to the Maintenance State feature, DataNodes are (re)commissioned using the include hosts file specified using the dfs.hosts configuration property and DataNodes are decommissioned using an exclude file specified using the dfs.hosts.exclude configuration property. These files have a simple format using comma-separated node names or IP addresses as values. org.apache.hadoop.hdfs.server.blockmanagement.HostFileManager is used by default which loads files specified by dfs.hosts and dfs.hosts.exclude.
These older file formats are not extendable for backwards compatibility reasons. The new Maintenance State feature uses a new combined hosts file in JSON format,which can be used to both include and exclude (Decommission or Maintenance State) DataNodes. The Maintenance State feature is supported only with this newer combined hosts file. The provider class name must be org.apache.hadoop.hdfs.server.blockmanagement.CombinedHostFileManager to load the JSON file defined in dfs.hosts.
Here is the format of the combined hosts file:
{
"hostName": <DataNode hostname>,
"port": <DataNode port>,
"upgradeDomain": <upgrade domain>,
"adminState": <DataNode admin state>,
"maintenanceExpireTimeInMS": <timeout in epoch millis>
}
“adminState” indicates the state the DataNode “hostName” wants to transition to. The allowed states are:
NORMAL
DECOMMISSIONED
IN_MAINTENANCE
“maintenanceExpireTimeInMS” is the maintenance expiry time and when reached, the corresponding DataNodes’ internal state reverts to NORMAL in the NameNode, which may cause replication because the maintenance minimum would no longer be in effect. This maintenance expiry time configuration is DataNode-specific and can vary from one DataNode to another. Those DataNodes needing a full operating system update might need a longer expiry time compared to DataNodes needing a quick restart for a hotfix. The maintenance expiry time is expressed in milliseconds since the epoch.
Operation:
Identify the optimal value for Maintenance State minimum replication based on the use cases, reliability and performance requirements. dfs.namenode.maintenance.replication.min needs to be configured as in the following example:
<property> <name>dfs.namenode.maintenance.replication.min</name> <value>1</value> </property>
The Maintenance State feature is supported only with the new combined hosts file format. Configure the hosts file provider:
<property> <name>dfs.namenode.hosts.provider.classname</name> <value>org.apache.hadoop.hdfs.server.blockmanagement.CombinedHostFileManager </value> </property>
Specify the combined hosts file location using the dfs.hosts property.
<property> <name>dfs.hosts</name> <value>/etc/hadoop/conf/maintenance</value> </property>
NameNode restart is required for any changes in all above values to be effective. Cloudera recommends that you decide on the above parameters well before the maintenance window. Update the combined hosts file /etc/hadoop/conf/maintenance for the DataNodes needing a maintenance operation as described below.
For a one hour maintenance window for datanode-100, datanode-101, and datanode-102 the maintenance expiry time is calculated as follows.
namenode-host# echo $((`date +%s` * 1000 + 60 * 60 * 1000))
1492543534000
namenode-host# cat /etc/hadoop/conf/maintenance
{
"hostName": "datanode-100",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
{
"hostName": "datanode-101",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
{
"hostName": "datanode-102",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
After updating the combined hosts file, run the following command to trigger the NameNode to refresh the node list and start the maintenance state transition for the specified DataNodes.
namenode-host$ hdfs dfsadmin -refreshNodes
The status of DataNodes state transitioning to the maintenance states can be monitored in NameNode WebUI on the summary page. Once DataNodes transition to IN_MAINTENANCE state, they can be safely removed from the cluster for maintenance operation.
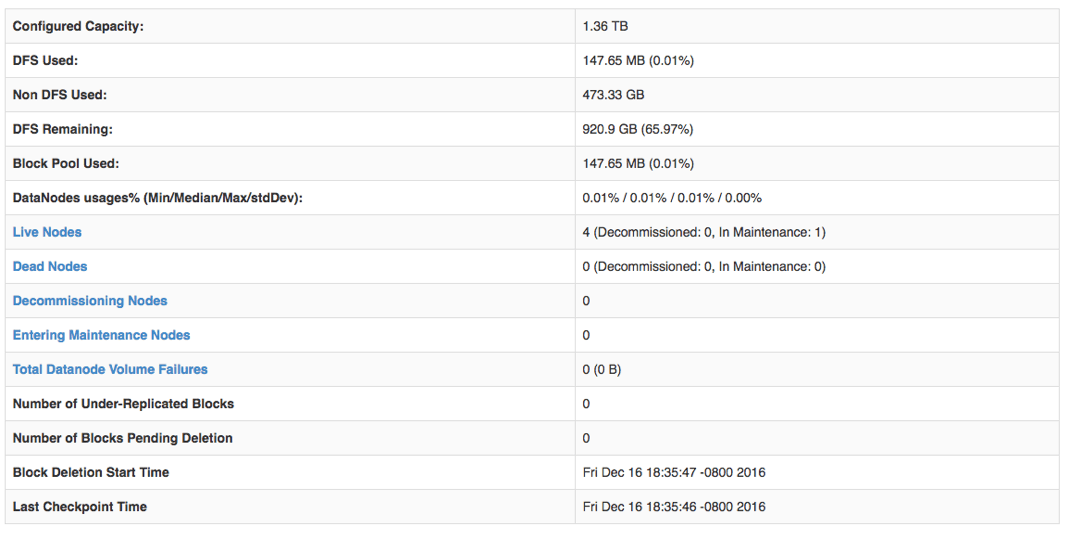 To let DataNodes that completed their maintenance operation rejoin the cluster, the refreshNodes admin operation is repeated with the same combined hosts file but with the DataNodes’
To let DataNodes that completed their maintenance operation rejoin the cluster, the refreshNodes admin operation is repeated with the same combined hosts file but with the DataNodes’ adminState updated to NORMAL like below.
{
"hostName": "datanode-100",
"port": 50010,
"adminState": "NORMAL"
}
...
Upon receiving the refreshNodes request, the NameNode transitions the DataNode from IN_MAINTENANCE state to NORMAL state and may send subsequent read and write requests from clients to use this DataNode.
Internals:
The NameNode makes sure that blocks located on the DataNodes that are requesting maintenance operations are sufficiently replicated as per the maintenance state minimum replication configuration dfs.namenode.maintenance.replication.min. This transient waiting period is referred to as ENTERING_MAINTENANCE state. When the blocks are sufficiently replicated, DataNodes move to the final safe state where they are ready to be removed from the cluster. This final safe state is referred to as IN_MAINTENANCE state.
If the Maintenance State minimum replication factor is set to 0, DataNodes transition directly to IN_MAINTENANCE. From state transition’s point of view, ENTERING_MAINTENANCE => IN_MAINTENANCE is similar to DECOMMISSION_INPROGRESS => DECOMMISSIONED. For the Maintenance State case, to verify sufficient replication, the dfs.namenode.replication.maintenance.min property is used and for the decommission case, the file replication factor is used.
A very simplified state transition is shown in the picture below. For a more detailed diagram of state transition and events, please refer to the design doc
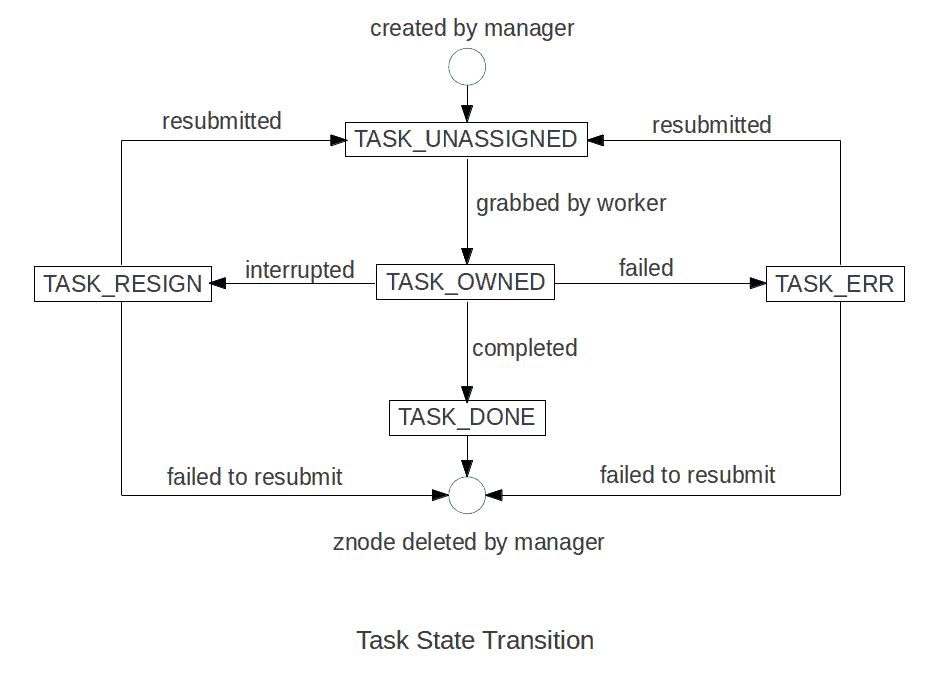 DataNodes in any of four states
DataNodes in any of four states ENTERING_MAINTENANCE, IN_MAINTENANCE, DECOMMISSION_INPROGRESS, or DECOMMISSIONED are referred to as out of service nodes.
- For write requests, out of service nodes are totally fenced off. The default block placement policy skips all out of service DataNodes as replica candidates. For read requests, out of service nodes are partially fenced. For a given block read request, BlockManager returns a
LocatedBlockwithIN_MAINTENANCEnodes excluded, but liveENTERING_MAINTENANCEnodes could still be included.ENTERING_MAINTENANCEDataNodes will continue to serve the ongoing read and write requests.
- NameNode
BlockMapcontinues to hold all blocks fromENTERING_MAINTENANCEandIN_MAINTENANCEDataNodes and thus are considered valid replicas from a block replication point of view. NameNode doesn’t invalidate any blocks from these DataNodes before the maintenance state expiry time, irrespective of whether these nodes are dead or alive.
- Disk Balancer and Mover avoids out of service DataNodes for any block movement.
Drawbacks:
When the Maintenance State minimum replication factor is 1, if the DataNode that hosts the only replica goes down momentarily, this could lead to data availability issues. Also, a single DataNode serving all read requests for a replica could cause performance issues. So, when doing maintenance operations on many DataNodes simultaneously, Cloudera recommends that you set the maintenance minimum replication factor to 2 to guard against above issues.
Conclusion:
Maintenance State feature HDFS-7877 overcomes the complexities and performance penalties with Rolling Upgrade and Decommission features when doing any quick maintenance operations for DataNodes. The version of HDFS shipping in CDH5.11 has the full support for this Maintenance State feature.
Acknowledgements
HDFS-7877 was collaboratively developed by Ming Ma from Twitter and Manoj Govindasamy, Lei (Eddy) Xu from Cloudera.
Editor's Choice

