

The theoretical bases for Machine Learning have existed for decades yet it wasn’t until the early 2000’s that the last AI winter came to an end.
Since then, interest in and use of machine learning has exploded and its development has been largely democratized, all of this fed by the widespread availability of:
- cheap, abundant computing power that’s able to tackle the calculation-hungry statistical approaches of ML in a “reasonable” time frame
- large corpora of data made easily accessible (Yeah Open Data / Big Data!)
- and easy to use, open source, frameworks such as Scikit-learn (released in 2007) – for Python- / Mlr (released 2013) or Caret for R, that have made the use of complex statistical analytical approaches available in just a few lines of code.
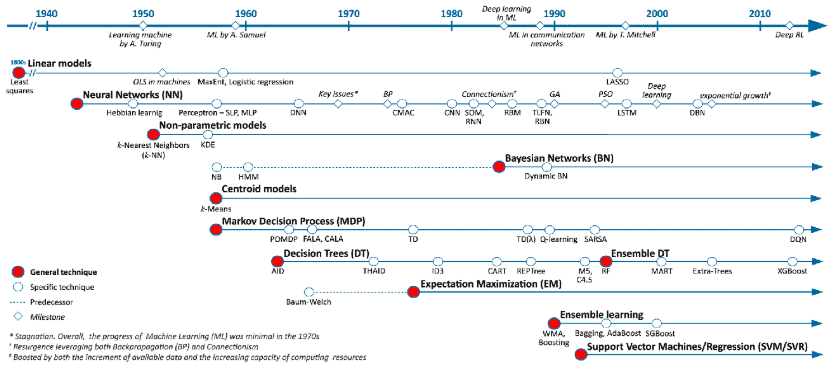
Photo Source: Semanticscholar.org
Perhaps not so coincidentally, the same period saw the rise of Big Data, carrying with it increased distributed data storage and distributed computing capabilities made popular by the Hadoop ecosystem. That said, and with a few exceptions (ex:Spark), machine learning and Big Data have largely evolved independently, despite that…
Machine Learning works best at scale
Which (arguably) intuitively makes sense, given that machine learning (at least in the context of classification) is essentially the process of:
- using machines to extract patterns from past data
- to create a representation (model) that is sufficiently accurate to be able to predict future data**
- using machines to extract patterns from past data
- to create a representation (model) that is sufficiently accurate to be able to predict future data**
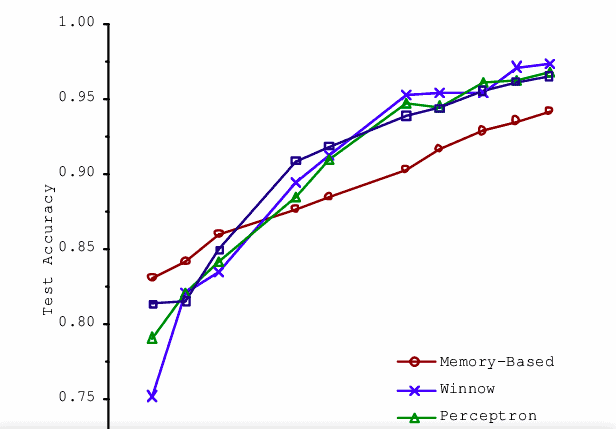
Photo Source:
[Banko and Brill, 2001]
Scaling to Very Very Large Corpora for Natural Language Disambiguation
Research and practical experience have shown for machine learning that this postulate holds true: machine learning simply works better at scale.
Distributed Computing to the rescue?
On paper distributed computing offers many compelling arguments for Machine Learning:
- The ability to speed up computationally intensive workflow phases such as training, cross-validation or multi-label predictions
- The ability to work from larger datasets, hence improving the performance and resilience of models
That said, distributed computing creates its own set of problems, most notably in terms of dependency management (ie. how to coordinate dependent tasks in a system that runs in parallel).
There are 2 major facets to this issue:
1. Task Parallelism, or the ability to run many tasks simultaneously (note: some may be potentially dependent):
This problem is often approached in distributed computing frameworks by accumulating task descriptions then calculating their dependencies, a process called Lazy execution.
(https://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-operations)
(https://examples.dask.org/applications/embarrassingly-parallel.html#Use-Dask-Delayed-to-make-our-function-lazy)
In certain circumstances, dependencies only appear at execution time, requiring extra sets of coordination. This is often called a “Barrier execution problem“.
Deep learning algorithms are especially impacted as there are often interdependencies between different layers. While able to run in parallel, they require high levels of coordination to pass different values.
Note: many distributed frameworks such as Spark and Horovod are making major headway in facilitating distributed deep learning.
2. Data Parallelism, or the ability to cut up a large dataset into smaller pieces while maintaining the overall consistency and the ability to handle it as a single unit:
This can prove challenging for many algorithms that either requires knowledge of the entire data distribution (ex. SVM ) or require extensive coordination (ex. deep learning ).
Most ML algorithms are optimization problems; and if they are not, they can often be cast as such. Therein lies the challenge: optimization problems are hard to distribute; they are often np-complex.
Taking a page out of Scikit-learn’s (impeccable) documentation for its Support Vector Machine implementation:
“The implementation is based on libsvm. The fit time scales at least quadratically with the number of samples and maybe impractical beyond tens of thousands of samples.”
Ok, making Big Data and machine learning work together is hard.
But not everything is a Big Data problem
In many cases, especially when working with medium to large-ish datasets, data parallelization can be removed from the equation (by distributing the entire dataset), thereby reducing many tasks to embarrassingly parallel workloads, for example:
- Cross-validation: Testing the results of a machine learning hypothesis using different training and testing data
- Grid-searching: Systematically changing the hyper-parameters of a machine learning hypothesis and testing the consequent results
- Multilabel prediction: Running an algorithm multiple times against multiple targets when there are many different target outcomes to predict at the same time
- Ensemble machine-learning: Modeling a large host of classifiers, each one independent from the other.
This approach significantly reduces the optimisation phase of ML training, usually the most time-consuming element of the process.
Dask and Scikit-learn: a parallel computing and a machine learning framework that work nicely together
Dask is an open-source parallel computing framework written natively in Python (initially released 2014). It has a significant following and support largely due to its good integration with the popular Python ML ecosystem triumvirate that is NumPy, Pandas, and Scikit-learn.
Why Dask over other distributed machine learning frameworks?
In the context of this article, it’s about Dask’s tight integration with Sckit-learn’s JobLib parallel computing library that allows us to distribute Scikit-learn code with (almost) no code change, making it a very interesting framework to accelerate ML training.
As outlined in its documentation :
Alternatively, Scikit-Learn can use Dask for parallelism. This lets you train those estimators using all the cores of your cluster without significantly changing your code.
This is most useful for training large models on medium-sized datasets. You may have a large model when searching over many hyper-parameters, or when using an ensemble method with many individual estimators. For too small datasets, training times will typically be small enough that cluster-wide parallelism isn’t helpful. For too large datasets (larger than a single machine’s memory), the scikit-learn estimators may not be able to cope (see below).
Essentially, you can use Dask whenever you see Scikit-learn use the n_jobs parameter.
Parallel training using Dask and Scikit-learn on the Cloudera Machine Learning (CML) Platform
CML, Cloudera’s machine learning service for Cloudera Data Platform, and Cloudera Data Science Workbench (CDSW), it’s predecessor supporting Cloudera EDH and HDP, have been developed to work as generic code execution engines, allowing data scientists to work with any machine learning or data science frameworks they choose.
CML is built on top of Kubernetes with all containers, also known as engines, running in individual pods. This provides full isolation and encapsulation of code running in each container, allowing data scientists to use different versions of software packages and/or different languages across projects.
CML Workers
To work with Dask we will be leveraging CML’s “workers” function:
Essentially, the ability to launch, within the context of a user session, computing clusters running on top of Kubernetes. The worker’s function allows users to run Python or R code on an arbitrary number of workers.
Code (git available here ):
import cdsw worker_code = ''' import os engine_id = os.environ.get('CDSW_ENGINE_ID') print('executing a whole bunch of code inside worker: {}'.format(engine_id)) ''' workers = cdsw.launch_workers(n=2, cpu=1, memory=1, code=worker_code)
Result:

Dask helper library
To facilitate the work with other distributed frameworks, we have created helper libraries that automatically install the clients and the required dependencies and then deploy the cluster.
The software architecture is presented in the diagram below:
CML essentially launches a Kubernetes container-based cluster on-demand. Once the work is completed, the cluster is shut down and the resources are released.
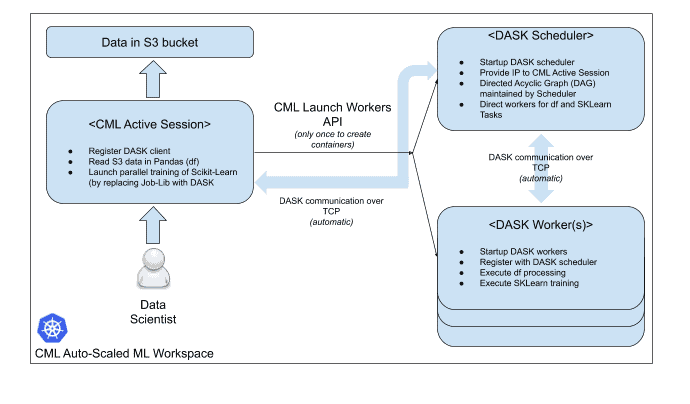
How to use a Dask Back-end for Scikit-learn
The below example is based on the Airline on Time dataset, for which I have built a predictive model using Scikit Learn and DASK as a training backend.
The elements below focus on the specificity required for:
- Creating a DASK cluster on CML
- Modify the SKLearn pipeline to use DASK as a back-end
The code can be downloaded at: https://github.com/frenchlam/dask_CDSW
- Launch the Dask Cluster :
1.1 Launch the cluster using the “cdsw_dask_utils” helper library
Code available here ( Part3 Distributed training using DASK Backend ) :
# Run a Dask cluster with three workers and return an object containing # a description of the cluster. # # Using helper library # Note that the scheduler will run in the current session, and the Dask # dashboard will become available in the nine-dot menu at the upper # right corner of the CDSW app. cluster = cdsw_dask_utils.run_dask_cluster( n=2, \ cpu=1, \ memory=3, \ nvidia_gpu=0 )
Result :
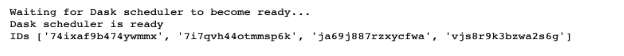
1.2 Get the Dask Scheduler UI link
#Get the Dask Scheduler UI import os engine_id = os.environ.get('CDSW_ENGINE_ID') cdsw_domain = os.environ.get('CDSW_DOMAIN') from IPython.core.display import HTML HTML('<a target="_blank" rel="noopener noreferrer" href="http://read-only-{}.{}">http://read-only-{}.{}</a>' .format(engine_id,cdsw_domain,engine_id,cdsw_domain))
The library, which uses the same syntax as the worker’s function (leveraged under the covers), installs all the DASK dependencies and then launches the scheduler and the workers.
You can connect to the Dask Dashboard to verify that the cluster is indeed up and running.
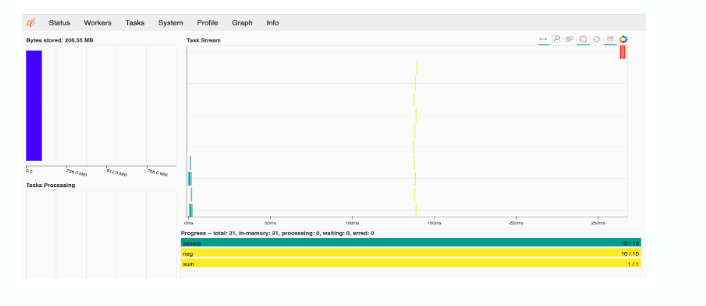
1.Replace SKLearn Joblib with DASK
2.1 Connect a dask client to the scheduler (previously started in the step above)
Code:
# #### Connect a Dask client to the scheduler address in the cluster from dask.distributed import Client client = Client(cluster["scheduler_address"])
2.2 Replace Joblib with Dask’s Distributed Joblib (and that’s it!!)
Note : Data volume – 563Klines and 11 features
Code:
# ### Fit Model with Dask from joblib import Parallel, parallel_backend with parallel_backend('dask'): CV_rfc.fit(X_train, y_train)
Result : 
In the example above, I am using DASK to train a Random Forest classifier, within a pipeline containing a grid search and cross-validation.
pipeline configuration :
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# ### parameters for grid search param_numTrees = list(range(2,12,2)) print(param_numTrees) param_maxDepth = list(range(2,12,2)) print(param_maxDepth) rfc = RandomForestClassifier(random_state=10, n_jobs=-1) GS_params = { 'n_estimators': param_numTrees, 'max_depth' : param_maxDepth } CV_rfc = GridSearchCV(estimator=rfc, param_grid=GS_params, cv= 3, verbose = 1, n_jobs=-1)
Result :

Dask Dashboard
DASK provides an interesting Dashboard where we can peek into the progress of execution of the training.
Below:the DAG for the SKLearn training
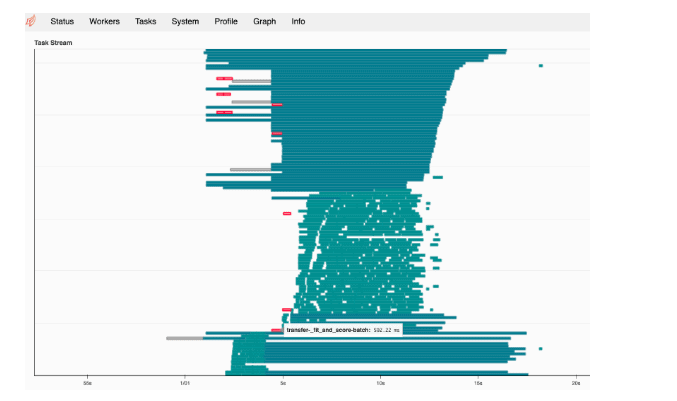
We can also look at the current load of the cluster.
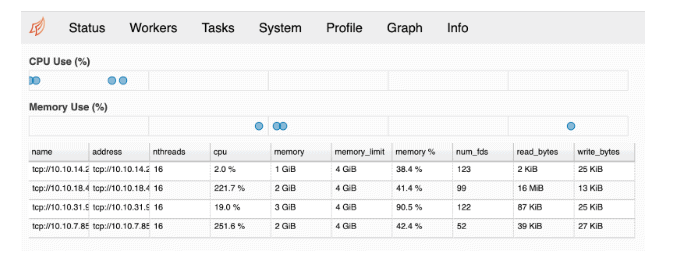
Resources :
Code example for this article: DASK and SKLearn for distributed Grid Search and Cross-validation
For more information on :
- Cloudera Machine Learning Products https://www.cloudera.com/products/machine-learning.htm
- DASK
https://ml.dask.org/joblib.html - Distributed ML Algorithms :
- https://www.cs.cmu.edu/~epxing/Class/10708-16/note/10708_scribe_lecture28.pdf
- https://link.springer.com/article/10.1007/s13748-012-0035-5
And if you want to go into the mathematical aspects of approximate optimization algorithms
Editor's Choice

