

As many of us know, data in HDFS is stored in DataNodes, and HDFS can tolerate DataNode failures by replicating the same data to multiple DataNodes. But exactly what happens if some DataNodes’ disks are failing? This blog post explains how some of the background work is done on the DataNodes to help HDFS to manage its data across multiple DataNodes for fault tolerance. Particularly, we will explain block scanner, volume scanner, directory scanner, and disk checker: what they do, how they work, and some relevant configurations.
Background: Blocks in HDFS
To make sure everyone is on the same page, let’s take a moment to go through some fundamentals of HDFS. We’ll specifically focus on the DataNodes since that is where most of things described in this blog post reside.
As described in HDFS architecture, the NameNode stores metadata while the DataNodes store the actual data content. Each DataNode is a computer which usually consists of multiple disks (in HDFS’ terminology, volumes). A file in HDFS contains one or more blocks. A block has one or multiple copies (called Replicas), based on the configured replication factor. A replica is stored on a volume of a DataNode, and different replicas of the same block are stored on different DataNodes. Detailed status of the block is sent from each DataNode to the NameNode via block reports. A block has several states, as described in Understanding HDFS Recovery Processes. Eventually a block is finalized and stored on the DataNode disk as a block file and a meta file on the local file system. The block file stores the file data, while the meta file stores the checksum of the file data, which can be used to verify the integrity of the block file. The meta file is named after the block file, and additionally contains the generation stamp.
A sample of block files and their .meta files stored on a DataNode’s disk:

One of HDFS’ core assumptions is that hardware failure is the norm rather than the exception. When a disk fails, either or both the block file and the meta file could potentially become corrupt. HDFS has mechanisms to identify and handle these. But what are these mechanisms? Specifically:
- When and how do the DataNodes verify the block files?
- How do the DataNodes verify if its in-memory metadata about the blocks is consistent with what’s actually on the disk?
- If failures occur during a block read operation, is it due to disk error? Or is it just some intermittent errors (e.g. network timeout)?
The answers to these questions lie in various DataNode background tasks, and we will go through them in the following sections. Three types of tasks on the DataNode are introduced, each trying to address one question above accordingly: Block Scanners & Volume Scanners, Directory Scanners, and Disk Checker.
Block Scanner & Volume Scanner
The function of block scanner is to scan block data to detect possible corruptions. Since data corruption may happen at any time on any block on any DataNode, it is important to identify those errors in a timely manner. This way, the NameNode can remove the corrupted blocks and re-replicate accordingly, to maintain data integrity and reduce client errors. On the other hand, we don’t want to utilize too many resources, so that disk I/O can still serve actual requests.
Therefore, block scanner needs to make sure that suspicious blocks are scanned relatively quickly, and other blocks are scanned every once in awhile, at a relatively lower frequency, without significant I/O usage.
A block scanner is associated with a DataNode, and contains a collection of volume scanners. Each volume scanner runs its own thread and is responsible to scanning a single volume of the DataNode. The volume scanner slowly reads all the blocks one by one, and verifies each block. Let’s call this regular scans. Note that this is slow because the entire block needs to be read to perform the check, which consumes a considerable amount of I/O.
Volume scanner also maintains a list of suspicious blocks. These are the blocks that caused specific types of exceptions (described in detail below) to be thrown when they are read from disk. The suspicious blocks take priority over the regular blocks during the scans. Moreover, each volume scanner tracks which suspicious blocks it has scanned in the past 10 minutes, to avoid repeatedly scanning the same suspicious blocks.
Notice that the block scanner and the volume scanner are implementation details, they together handles the job of block scanning. So for simplicity of this blog post, we will refer to both the block scanner and the volume scanner as ‘block scanner’ in the rest of this blog post.
The mechanism block scanner uses to decide which block to scan is as follows:
- When a DataNode is serving I/O requests, either from a client or from another DataNode, if an IOException is caught, and it’s not due to network (i.e. socket timeout, broken pipe or connection reset), then the block is marked as suspicious and added to the block scanner’s suspicious block list.
- The block scanner loops over all the blocks. At each iteration, it checks one block.
- If the suspicious block list is not empty, it pops one suspicious block to scan.
- Otherwise, a normal block is scanned.
Only local (non-network) IOExceptions cause a block to be marked as suspicious, because we want to keep the suspicious block list short and reduce false positives. This way, a corruption will take priority and get reported in a timely manner.
To keep track of the scanning position among the blocks, a block cursor is maintained for each volume. The cursor is saved to disk periodically (interval is configurable via dfs.block.scanner.cursor.save.interval.ms, the default value is 10 minutes). This way, even if the DataNode process restarts or the server reboots, the scan doesn’t have to restart from the very beginning.

As mentioned at the beginning of this section, another concern about the scanner is I/O consumption. Whether the block being scanned is a suspicious block or a normal block, we cannot afford to loop scanning them continuously, because this could create busy I/Os and harm normal I/O performance. Instead, the scanners run at a configured rate for throttling purpose, with appropriate sleep intervals between two scan periods. A scan period is an interval that a whole scan should be performed. When a block is marked as suspicious, the volume scanner is woken up if it’s waiting for the next scan period. If a full scan isn’t finished within the scan period, the scan continues without sleeping.
Important Configurations:
The following 2 configurations in hdfs-site.xml are the most used for block scanners.
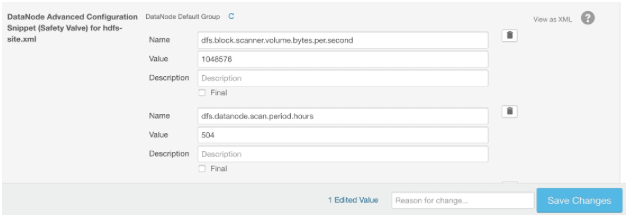
- dfs.block.scanner.volume.bytes.per.second to throttle the scan bandwidth to configurable bytes per second. Default value is 1M. Setting this to 0 will disable the block scanner.
- dfs.datanode.scan.period.hours to configure the scan period, which defines how often a whole scan is performed. This should be set to a long enough interval to really take effect, for the reasons explained above. Default value is 3 weeks (504 hours). Setting this to 0 will use the default value. Setting this to a negative value will disable the block scanner.
These configurations can be set via Cloudera Manager for all DataNodes by setting name/value pairs within the DataNode Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml:
Notable JIRAs:
HDFS-7430 enhances the block scanner to use O(1) memory and enables each volume scanner to run on a separate thread.
HDFS-7686 allows fast rescan of suspicious blocks.
HDFS-10512 fixes an important bug that a race condition could terminate the volume scanner.
Directory Scanners
While block scanners ensure the block files stored on disk are in good shape, DataNodes cache the block information in memory. It is critical to ensure the cached information is accurate. The directory scanner checks and fixes the inconsistency between the cache and actual files on disk. Directory scanner periodically scans the data directories for block and metadata files, and reconciles the differences between block information maintained in disk and that in memory.
The logic to check for all the differences is described by the following diagram. Only finalized blocks are checked.
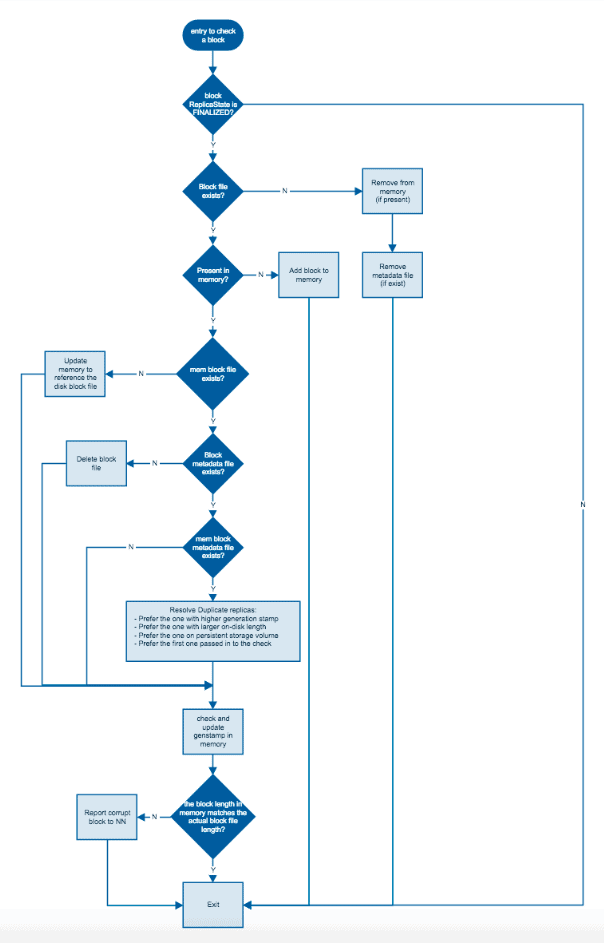
If a block is marked as corrupted, it’s reported to the NameNode via the next block report. The NameNode will then arrange the block for replication from good replicas.
Similar to block scanner, throttling is also needed by the directory scanner. The throttling is done by limiting each directory scanner thread to only run for a given number of milliseconds per second.
Important Configurations:
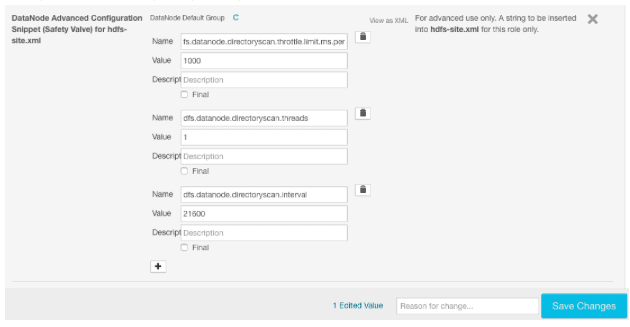
- dfs.datanode.directoryscan.throttle.limit.ms.per.sec controls how many milliseconds per second a thread should run. Note that this limit is taken per thread, not an aggregated value for all threads. Default value is 1000, meaning the throttling is disabled. Only values between 1 and 1000 are valid. Setting an invalid value will result in the throttle being disabled and an error message being logged.
- dfs.datanode.directoryscan.threads controls the maximum number of threads a directory scanner can have in parallel. Default value is 1.
- dfs.datanode.directoryscan.interval controls the interval, in seconds, that the directory scanner thread runs. Setting this to a negative value disables the directory scanner. Default value is 6 hours (21600 seconds).
The above configurations can be changed in hdfs-site.xml on each DataNode to take effect. The default values should be sufficient for most of the time, representing a good balance between cluster I/O and prompt correction of data corruption. These can also be set via Cloudera Manager conveniently by adding name/value pairs to DataNode Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml:
Notable JIRAs:
HDFS-8873 Allows the directoryScanner to be rate-limited
Disk Checker
Aside from the above mentioned scanners, DataNodes may also run a disk checker in a background thread to decide if a volume is unhealthy and whether to remove it. The reason to have the disk checker is that, if something goes wrong at the volume level, HDFS should detect it and stop trying to write to that volume. On the other hand, removing a volume is non-trivial and has wide impacts, because it will make all the blocks on that volume inaccessible, and HDFS has to handle all the under-replicated blocks due to the removal. Therefore, disk checker performs the most basic checks, with a very conservative logic to consider a failure.
The logic inside the check is pretty simple – it checks the following directories on the DataNode in sequence:
- Directory ‘finalized’
- Directory ‘tmp’
- Directory ‘rbw’
(This blog post explains what these directories are in greater detail.)
When checking each of the 3 directories, the disk checker verifies that:
- The directory and all its parent directories exist, or can be created otherwise.
- The path is indeed of type directory.
- The process has read, write, and execute permissions on the directory.
Strictly speaking, we should recursively do the same check on all the subdirectories under all these 3 directories. But that turns out to create excessive I/Os, with little benefit – those errored blocks will be added to the suspicious blocks in the block scanners anyway, thus they will get scanned / reported relatively soon. On the other hand, applications such as HBase are very performance-sensitive and strive to ensure SLAs, and the excessive I/Os here could create spikes, which cannot be tolerated. As a result, only the 3 checks listed above are performed.
While block scanners and directory scanners are activated on DataNode startup and scans periodically, the disk checker only runs on-demand, with the disk checker thread lazily created. Specifically, the disk checker only runs if an IOException is caught on the DataNode during regular I/O operations (e.g. closing a block or metadata file, directory scanners reporting an error, etc.). Additionally, the disk checker only runs at most once in a 5~6 seconds period. This specific period is randomly generated when the disk checker thread is created.
Moreover, if the number of failed volumes at startup is greater than a configured threshold, the DataNode shuts itself down. The DataNode performs this initial check by comparing the differences between all configured storage locations and the actual storage locations in use after attempting to put all of them into service. The threshold is configurable in hdfs-site.xml via dfs.datanode.failed.volumes.tolerated. Default value is 0.
Cloudera Manager has this configuration item listed explicitly under DataNode, as ‘DataNode Failed Volumes Tolerated’:

Notable JIRAs:
HDFS-7722 DataNode#checkDiskError should also remove Storage when error is found.
HDFS-8617 Throttle DiskChecker#checkDirs() speed.
HADOOP-13738 DiskChecker should perform some disk IO
Conclusion
Various background tasks in the DataNodes keep HDFS data durable and reliable. They should be carefully tuned to maintain cluster health and reduce I/O usage. This blog explains the following background tasks: block scanner, volume scanner, directory scanner, and disk checker, what they do, how they work, and some of the relevant configurations. Hope you have a good understanding about them after reading.
Having a hard time remembering and configuring all the configurations described in this blog post on every DataNode? No problem! Cloudera Manager makes this convenient and easy to manage – you can configure them in one place and push to all the DataNodes.
Xiao Chen is a Software Engineer at Cloudera, and an Apache Hadoop committer.
Editor's Choice


Assume the DataNode d2 is broken. How can the broken DataNode be detected
by Hadoop? Explain what actions are done by the HDFS regarding this issue. Be
precise about the access of the NameNode to d2, the availability of the data sets s2j
and the effects regarding the replication factor?