

Introduction
Apache HBase is the Hadoop open-source, distributed, versioned storage manager well suited for random, realtime read/write access.
Wait wait? random, realtime read/write access?
How is that possible? Is not Hadoop just a sequential read/write, batch processing system?
Yes, we’re talking about the same thing, and in the next few paragraphs, I’m going to explain to you how HBase achieves the random I/O, how it stores data and the evolution of the HBase’s HFile format.
Apache Hadoop I/O file formats
Hadoop comes with a SequenceFile[1] file format that you can use to append your key/value pairs but due to the hdfs append-only capability, the file format cannot allow modification or removal of an inserted value. The only operation allowed is append, and if you want to lookup a specified key, you’ve to read through the file until you find your key.
As you can see, you’re forced to follow the sequential read/write pattern… but how is it possible to build a random, low-latency read/write access system like HBase on top of this?
To help you solve this problem Hadoop has another file format, called MapFile[1], an extension of the SequenceFile. The MapFile, in reality, is a directory that contains two SequenceFiles: the data file “/data” and the index file “/index”. The MapFile allows you to append sorted key/value pairs and every N keys (where N is a configurable interval) it stores the key and the offset in the index. This allows for quite a fast lookup, since instead of scanning all the records you scan the index which has less entries. Once you’ve found your block, you can then jump into the real data file.
MapFile is nice because you can lookup key/value pairs quickly but there are still two problems:
- How can I delete or replace a key/value?
- When my input is not sorted, I can not use MapFile.
HBase & MapFile
The HBase Key consists of: the row key, column family, column qualifier, timestamp and a type.
![]()
To solve the problem of deleting key/value pairs, the idea is to use the “type” field to mark key as deleted (tombstone markers). Solving the problem of replacing key/value pairs is just a matter of picking the later timestamp (the correct value is near the end of the file, append only means last inserted is near the end).
To solve the “non-ordered” key problem we keep the last added key-values in memory. When you’ve reached a threshold, HBase flush it to a MapFile. In this way, you end up adding sorted key/values to a MapFile.
HBase does exactly this[2]: when you add a value with table.put(), your key/value is added to the MemStore (under the hood MemStore is a sorted ConcurrentSkipListMap). When the per-memstore threshold (hbase.hregion.memstore.flush.size) is reached or the RegionServer is using too much memory for memstores (hbase.regionserver.global.memstore.upperLimit), data is flushed on disk as a new MapFile.
The result of each flush is a new MapFile, and this means that to find a key you have to search in more than one file. This takes more resources and is potentially slower.
Each time a get or a scan is issued, HBase scan through each file to find the result, to avoid jumping around too many files, there’s a thread that will detect when you’ve reached a certain number of files (hbase.hstore.compaction.max). It then tries to merge them together in a process called compaction, which basically creates a new large file as a result of the file merge.
HBase has two types of compaction: one called “minor compaction” that just merges two or more small files into one, and the other called “major compaction” that picks up all the files in the region, merges them and performs some cleanup. In a major compaction, deleted key/values are removed, this new file doesn’t contain the tombstone markers and all the duplicate key/values (replace value operations) are removed.
Up to version 0.20, HBase has used the MapFile format to store the data but in 0.20 a new HBase-specific MapFile was introduced (HBASE-61).
HFile v1
In HBase 0.20, MapFile is replaced by HFile: a specific map file implementation for HBase. The idea is quite similar to MapFile, but it adds more features than just a plain key/value file. Features such as support for metadata and the index is now kept in the same file.
The data blocks contain the actual key/values as a MapFile. For each “block close operation” the first key is added to the index, and the index is written on HFile close.
The HFile format also adds two extra “metadata” block types: Meta and FileInfo. These two key/value blocks are written upon file close.
The Meta block is designed to keep a large amount of data with its key as a String, while FileInfo is a simple Map preferred for small information with keys and values that are both byte-array. Regionserver’s StoreFile uses Meta-Blocks to store a Bloom Filter, and FileInfo for Max SequenceId, Major compaction key and Timerange info. This information is useful to avoid reading the file if there’s no chance that the key is present (Bloom Filter), if the file is too old (Max SequenceId) or if the file is too new (Timerange) to contain what we’re looking for.
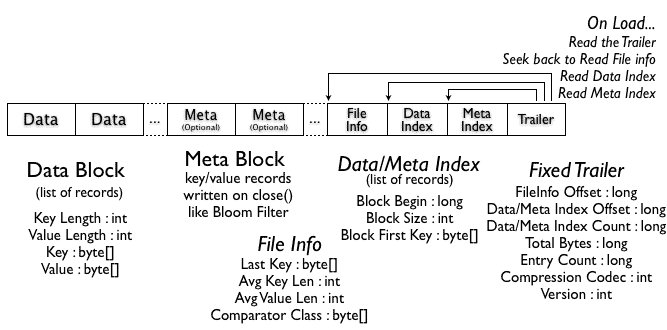
HFile v2
In HBase 0.92, the HFile format was changed a bit (HBASE-3857) to improve the performance when large amounts of data are stored. One of the main problems with the HFile v1 is that you need to load all the monolithic indexes and large Bloom Filters in memory, and to solve this problem v2 introduces multi-level indexes and a block-level Bloom Filter. As a result, HFile v2 features improved speed, memory, and cache usage.

The main feature of this v2 are “inline blocks”, the idea is to break the index and Bloom Filter per block, instead of having the whole index and Bloom Filter of the whole file in memory. In this way you can keep in ram just what you need.
Since the index is moved to block level you then have a multi-level index, meaning each block has its own index (leaf-index). The last key of each block is kept to create the intermediate/index that makes the multilevel-index b+tree like.
![]()
The block header now contains some information: The “Block Magic” field was replaced by the “Block Type” field that describes the content of the block “Data”, Leaf-Index, Bloom, Metadata, Root-Index, etc. Also three fields (compressed/uncompressed size and offset prev block) were added to allow fast backward and forward seeks.
Data Block Encodings
Since keys are sorted and usually very similar, it is possible to design a better compression than what a general purpose algorithm can do.
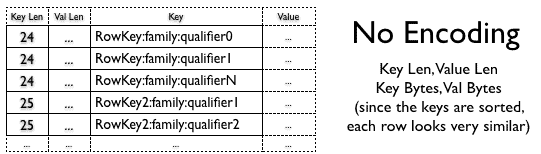
HBASE-4218 tried to solve this problem, and in HBase 0.94 you can choose between a couple of different algorithms: Prefix and Diff Encoding.
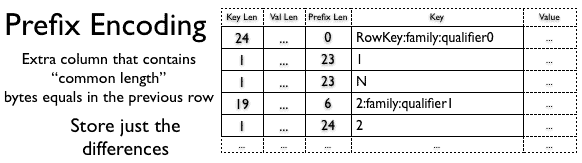
The main idea of Prefix Encoding is to store the common prefix only once, since the rows are sorted and the beginning is typically the same.

The Diff Encoding pushes this concept further. Instead of considering the key as an opaque sequence of bytes, the Diff Encoder splits each key field in order to compress each part in a better way. This being that the column family is stored once. If the key length, value length and type are the same as the row prior, the field is omitted. Also, for increased compression, the timestamp is stored is stored as a Diff from the previous one.
Note that this feature is off by default since writing and scanning are slower but more data is cached. To enable this feature you can set DATA_BLOCK_ENCODING = PREFIX | DIFF | FAST_DIFF in the table info.
HFile v3
HBASE-5313 contains a proposal to restructure the HFile layout to improve compression:
- Pack all keys together at beginning of the block and all the value together at the end of the block. In this way you can use two different algorithms to compress key and values.
- Compress timestamps using the XOR with the first value and use VInt instead of long.
Also, a columnar format or a columnar encoding is under investigation, take a look at AVRO-806 for a columnar file format by Doug Cutting.
As you may see the trend in evolution is to be more aware about what the file contains, to get better compression or better location awareness that translates into less data to write/read from disk. Less I/O means more speed!
[1] https://clouderatemp.wpengine.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
[2] https://clouderatemp.wpengine.com/blog/2012/06/hbase-write-path/
Editor's Choice

