


Did you know Cloudera customers, such as SMG and Geisinger, offloaded their legacy DW environment to Cloudera Data Warehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? In addition to substantial cost savings upon moving to CDW, Geisinger is also able to search through hundreds of million patient note records in seconds providing better treatment to their patients.
CDW customers provided valuable feedback that stored procedures should be supported to accelerate offloading legacy DW environments to CDW. Legacy DWs, often built on traditional database management systems, offer stored procedures that are used to implement advanced ETL and complex workflows. DW developers and data analysts have been implementing business logic and workflows substantially with stored procedures in legacy DWs. They wish to run these stored procedures that were written for legacy DWs in CDW with minimal or no rewrites to accelerate the offloading process.
Cloudera values customers’ feedback. Today, we are pleased to announce the general availability of HPL/SQL integration in CDW public cloud. You can now define Hive stored procedures using the HPL/SQL to perform a set of SQL statements (DDLs & DMLs), control-of-flow language. These Hive stored procedures are stored in the Hive MetaStore (HMS). HPL/SQL is a hybrid and heterogeneous language that understands syntaxes and semantics of almost any existing procedural SQL dialect, and you can use it with any database, for example, running existing Oracle PL/SQL code on Apache Hive. HPL/SQL language is compatible to a large extent with Oracle PL/SQL, ANSI/ISO SQL/PSM (IBM DB2, MySQL, Teradata i.e), Teradata BTEQ, PostgreSQL PL/pgSQL (Netezza), Transact-SQL (Microsoft SQL Server and Sybase) that allows you to leverage existing SQL skills and use a familiar approach to implementing data warehouse solutions. HPL/SQL support allows customers to run their stored procedures as is on CDW, without modifications to accelerate migration of legacy DWs to Cloudera Data Warehouse.
The Cloudera Data Warehouse (CDW) service is a managed data warehouse that runs Cloudera’s powerful engines on a containerized architecture. CDW is part of the new Cloudera Data Platform, which has two form factors: CDP Private Cloud and CDP Public Cloud that enable hybrid cloud deployment. The Data Warehouse on Cloudera Data Platform provides easy to use self-service and advanced analytics use cases at scale. It supports auto-provisioning, cloud optimization, self-service workload management, and auto scaling capabilities. Cloudera shared data experience (SDX) provides consistent data security, governance, and control across all multi-function analytics and data discovery.
The CDW is also highly scalable service that marries the MPP-based SQL engine technologies with cloud-native features to deliver best-in-class price-performance for users running data warehousing workloads in the cloud. But don’t just take our word for it. GigaOM recently published their own third party benchmark study comparing the price-performance of Cloudera Data Warehouse to 4 other prominent cloud data warehouse vendors. The results demonstrate superior price performance of Cloudera Data Warehouse on the full set of 99 queries from the TPC-DS benchmark.
In the following sections, we are going to show you how to use HPL/SQL in Cloudera Data Warehouse (CDW).
Setting up the warehouse
On CDW, the stored procedure support is turned off by default, but it is very easy to enable it. The only thing to do is to append a “mode=hplsq” suffix to the JDBC URL. You can either create a new warehouse or use an existing one. Next, click on the options menu in the upper right corner of your Hive Virtual Warehouse tile, and select Copy JDBC URL. This copies the JDBC URL to the system’s clipboard.
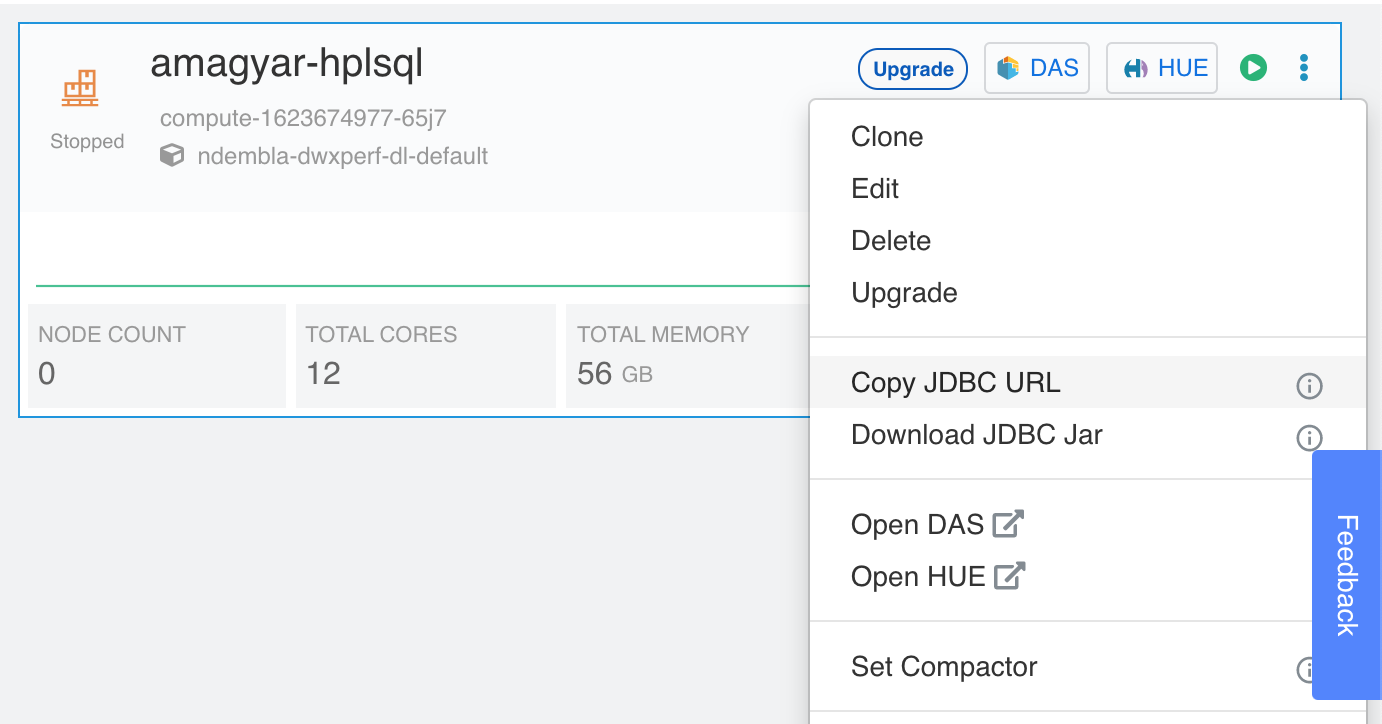
jdbc:hive2://<host>/<database>;transportMode=http;httpPath=cliservice;ssl=true;retries=3;mode=hplsql
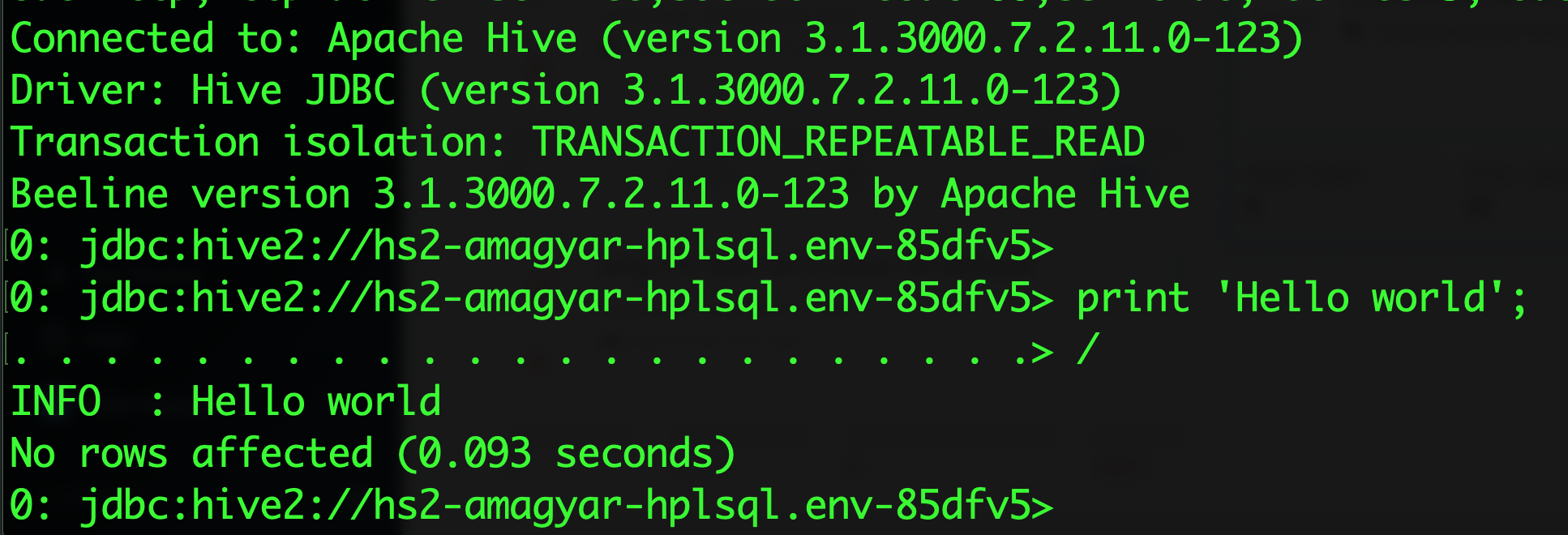
Add the “;mode=hplsql” to the end of the original URL. This is the URL that you need to use on the client side when connecting to HiveServer via JDBC. No restart is needed, you can start writing stored procedures right away. To quickly verify everything is working, connect to the modified JDBC URL via Beeline and type:
beeline -n <csso_username> -p <password> -u "jdbc:hive2://<hostname>/default;transportMode=http;httpPath=cliservice;socketTimeout=60;ssl=true;retries=3;mode=hplsql" print ‘Hello world’; /
Beeline is switched to multiline mode, so you can type multiple rows and evaluate them at once, if you enter a forward slash character.
Configuring a third-party database management tool
Apart from Beeline, there are third-party, JDBC based database management tools that you can use to execute HPL/SQL. The setup is the same. You need to set the modified JDBC URL in the tool.
In this demo I’m going to use the free version of DbVisualizer. Click on Connections / Create Database Connection, select “No Wizard” and edit the connection properties.
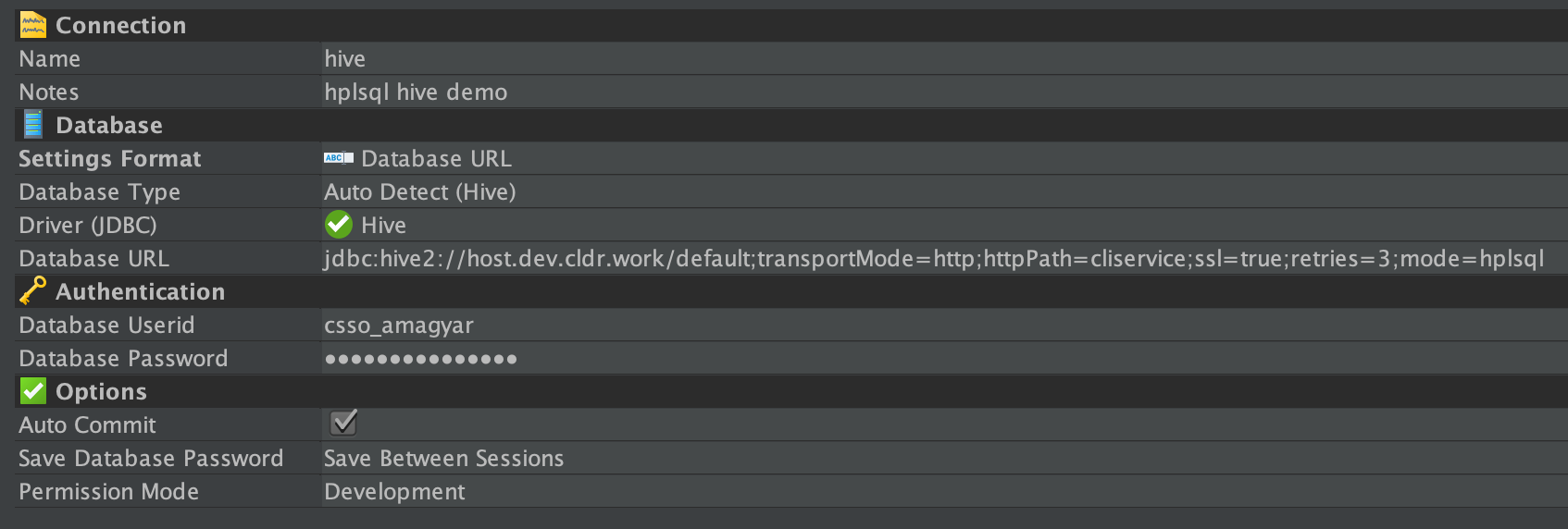
Set the Database Type to Hive and fill out the credential details, such as Database UserId and Database Password. Finally set the JDBC URL and click on Connect.
Open a new SQL Commander tab and type some commands to verify it works.
declare sum int = 0; for i in 1..10 loop sum := sum + i; end loop; select sum;
To evaluate the code it is important to use the “Execute the complete buffer as one SQL statement” button.
Creating stored procedures and functions
The syntax that HPLSQL uses is quite close to Oracle’s PL/SQL. You can create stored procedures and functions and use them in Hive selects.
First let’s create a table and populate it with some numbers.
create table numbers (n int); for i in 1..10 loop insert into numbers values(i); end loop;
Then let’s create our first Stored Function.
create function fizzbuzz(n int) returns string begin if mod(n, 15) == 0 then return 'FIZZBUZZ'; elseif mod(n, 5) == 0 then return 'BUZZ'; elseif mod(n, 3) == 0 then return 'FIZZ'; else return n; end if; end;
HPLSQL stores the function and procedure code permanently in Hive Metastore’s RDBMS. The procedure is loaded and cached on demand to the interpreter’s memory when needed. You can close the session or restart Hive without losing the definitions.
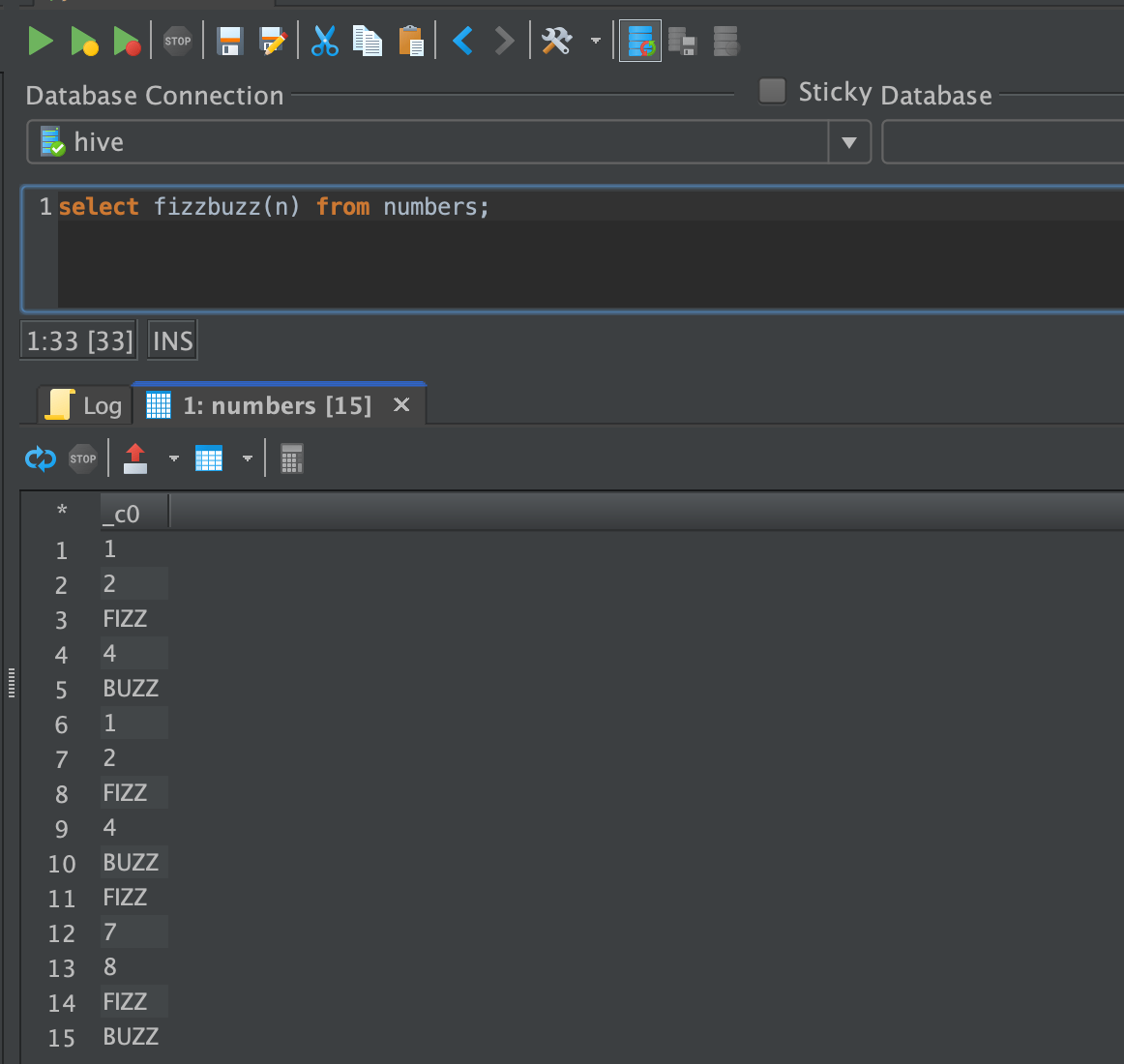
select fizzbuzz(n) from numbers;
It might happen that a third party tool won’t show you some of the error messages if you make some mistake in the syntax, so it’s recommended to use Beeline if you want to see them. Internally, while executing the select statement above, Hive transforms the stored procedure invocation to a UDF call.
select hplsql('fizzbuzz(:1)', n) from numbers
The hplsql UDF interprets the fizzbuzz function and calls it on each row.
Using the cursor
A cursor points to a result of a query. The FETCH statement places the contents of the current row into a variable (num in this example). Before you start fetching rows from the cursor, you must open it. After you’re done, you need to close the cursor with the CLOSE statement:
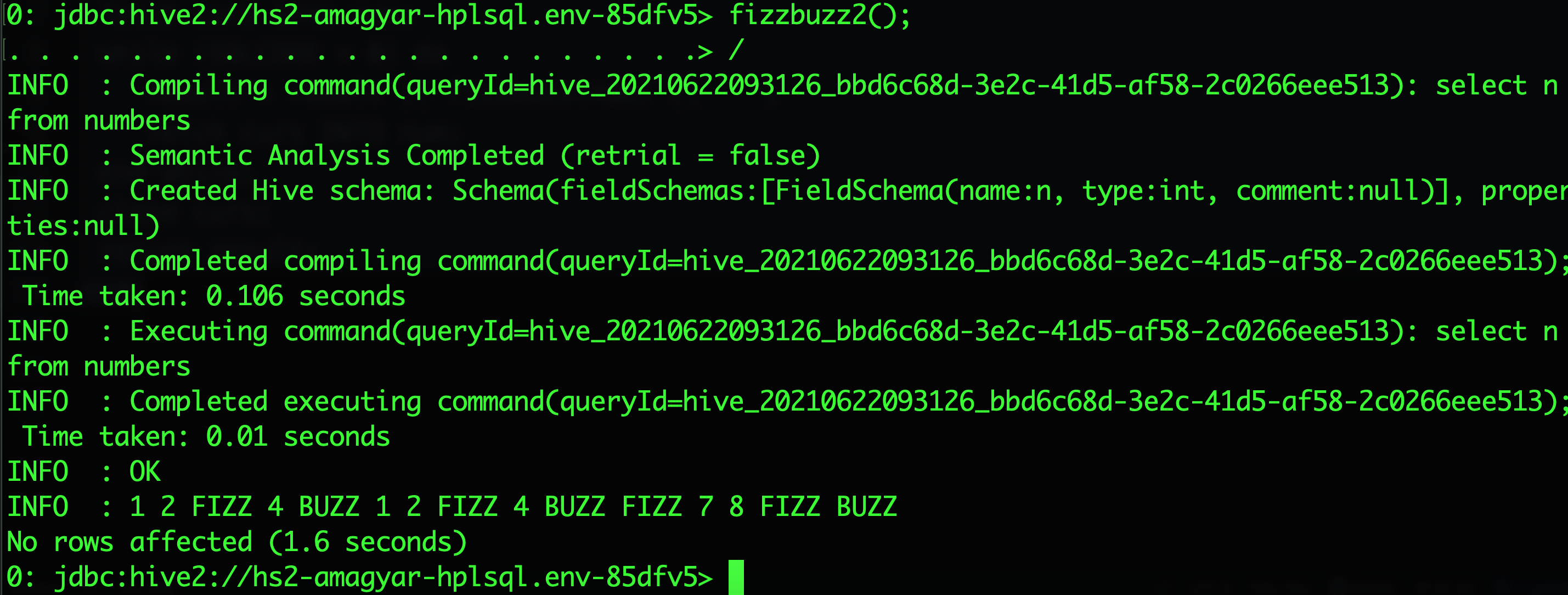
create function fizzbuzz2() returns string begin declare num int = 0; declare result string = ''; declare curs SYS_REFCURSOR; open curs for select n from numbers; fetch curs into num; while (SQLCODE = 0) do result = result || fizzbuzz(num) || ' '; fetch curs INTO num; end while; close curs; return result; end; print fizzbuzz2();
This version opens a cursor object on the result set of the select and iterates over it row by row. It calls the previous version of fizzbuzz on each row and concatenates the result into one string.
Hue integration is also planned so that you can use the Hue as the standard IDE for all SQL based development in CDW including stored procedures.
Summary
Take the next steps on your journey to CDW by offloading your legacy Data Warehouse to take advantage of modern DW architecture, best-in-class price-performance and standard ANSI SQL support including stored procedures. For more on CDW, sign up for a 60 day trial, or test drive CDP. As always, please provide your feedback in the comments section below.
Editor's Choice


While the blockchains themselves are secure, the applications running on the blockchain may not be. These applications interact with the blockchain through smart contracts, but just like any other software, bugs in the code can lead to security vulnerabilities. For this, we need to involve the auditors who conduct security audits on the smart contract. Smart Contract Audit helps you find hidden exploits and eventually reduce the risk and provide you an extra layer of security. Bug-free code is nice to have in other types of software, in blockchain applications, it is essential.