


Cloudera is launching and expanding partnerships to create a new enterprise artificial intelligence “AI” ecosystem. Businesses increasingly recognize AI solutions as critical differentiators in competitive markets and are ready to invest heavily to streamline their operations, improve customer experiences, and boost top-line growth. That’s why we’re building an ecosystem of technology providers to make it easier, more economical, and safer for our customers to maximize the value they get from AI.

At our recent Evolve Conference in New York we were extremely excited to announce our founding AI ecosystem partners: Amazon Web Services (“AWS“), NVIDIA, and Pinecone.

In addition to these founding partners we’re also building tight integrations with our ecosystem accelerators: Hugging Face, the leading AI community and model hub, and Ray, the best-in-class compute framework for AI workloads.
In this post we’ll give you an overview of these new and expanded partnerships and how we see them fitting into the emerging AI technology stack that supports the AI application lifecycle.
We’ll start with the enterprise AI stack. We see AI applications like chatbots being built on top of closed-source or open source foundational models. Those models are trained or augmented with data from a data management platform. The data management platform, models, and end applications are powered by cloud infrastructure and/or specialized hardware. In a stack including Cloudera Data Platform the applications and underlying models can also be deployed from the data management platform via Cloudera Machine Learning.
Here’s the future enterprise AI stack with our founding ecosystem partners and accelerators highlighted:

This is how we view that same stack supporting the enterprise AI application lifecycle:
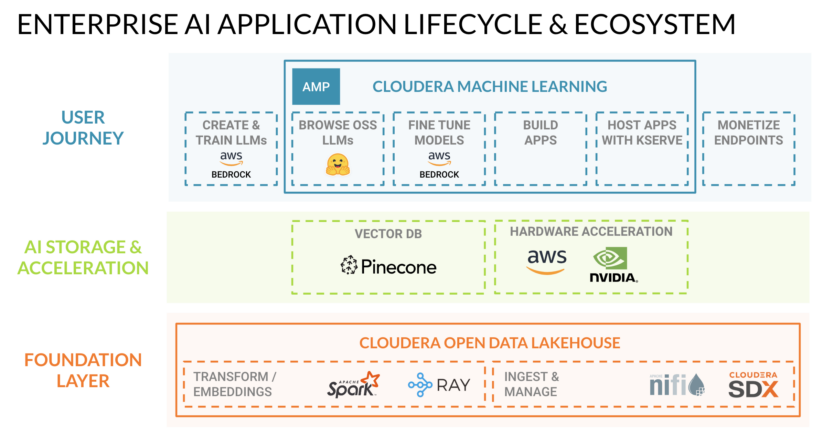
Let’s use a simple example to explain how this ecosystem enables the AI application lifecycle:
- A company wants to deploy a support chatbot to decrease operational costs and improve customer experiences.
- They can select the best foundational LLM for the job from Amazon Bedrock (accessed via API call) or Hugging Face (accessed via download) using Cloudera Machine Learning (“CML”).
- Then they can build the application on CML using frameworks like Flask.
- They can improve the accuracy of the chatbot’s responses by checking each question against embeddings stored in Pinecone’s vector database and then enhance the question with data from Cloudera Open Data Lakehouse (more on how this works below).
- Finally they can deploy the application using CML’s containerized compute sessions powered by NVIDIA GPUs or AWS Inferentia—specialized hardware that improves inference performance while reducing costs.
Read on to learn more about how each of our founding partners and accelerators are collaborating with Cloudera to make it easier, more economical, and safer for our customers to maximize the value they get from AI.
Founding AI ecosystem partners | NVIDIA, AWS, Pinecone
Highlights:
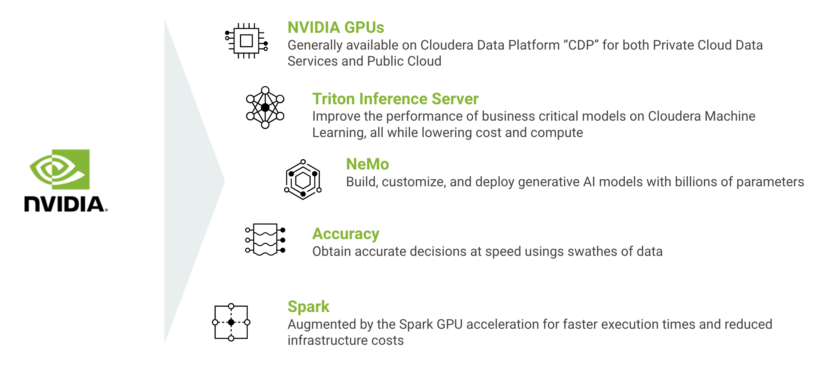
Currently, NVIDIA GPUs are already available in Cloudera Data Platform (CDP), allowing Cloudera customers to get eight times the performance on data engineering workloads at less than 50 percent incremental cost relative to modern CPU-only alternatives. This new phase in technology collaboration builds off of that success by adding key capabilities across the AI-application lifecycle in these areas:
- Accelerate AI and machine learning workloads in Cloudera on Public Cloud and on-premises using NVIDIA GPUs
- Accelerate data pipelines with GPUs in Cloudera Private Cloud
- Deploy AI models in CML using NVIDIA Triton Inference Server
- Accelerate generative AI models in CML using NVIDIA NeMo
Amazon Bedrock | Closed-Source Foundational Models
Highlights:
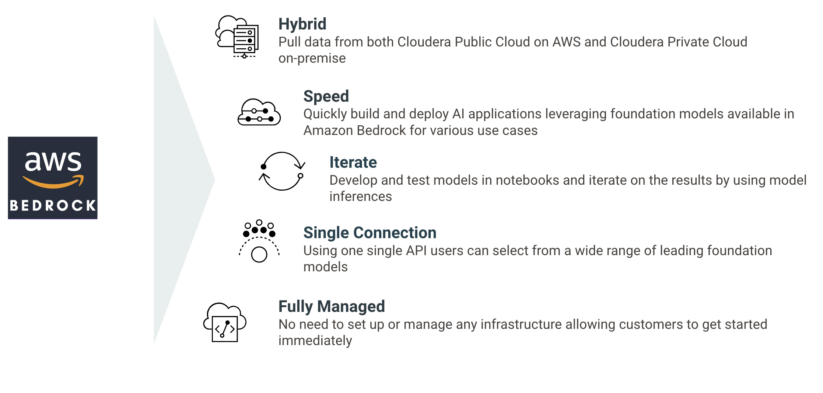
We are building generative AI capabilities in Cloudera, using the power of Amazon Bedrock, a fully managed serverless service. Customers can quickly and easily build generative AI applications using these new features available in Cloudera.
With the general availability of Amazon Bedrock, Cloudera is releasing its latest applied ML prototype (AMP) built in Cloudera Machine Learning: CML Text Summarization AMP built using Amazon Bedrock. Using this AMP, customers can use foundation models available in Amazon Bedrock for text summarization of data managed both in Cloudera Public Cloud on AWS and Cloudera Private Cloud on-premise. More information can be found in our blog post here.
Cloudera is working on integrations of AWS Inferentia and AWS Trainium–powered Amazon EC2 instances into Cloudera Machine Learning service (“CML”). This will give CML customers the ability to spin-up isolated compute sessions using these powerful and efficient accelerators purpose-built for AI workloads. More information can be found in our blog post here.
Highlights:
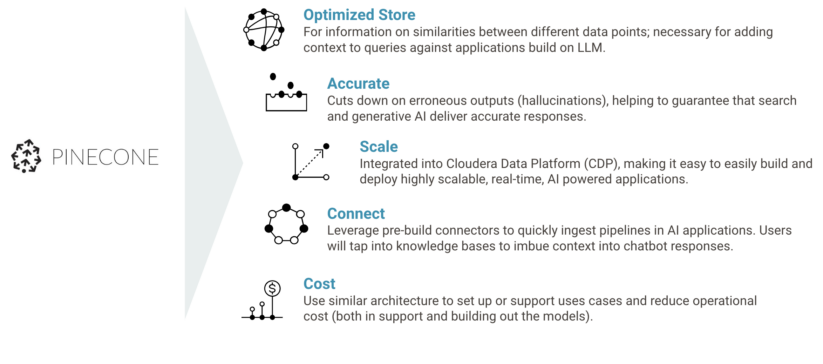
The partnership will see Cloudera integrate Pinecone’s best-in-class vector database into Cloudera Data Platform (CDP), enabling organizations to easily build and deploy highly scalable, real time, AI-powered applications on Cloudera.
This includes the release of a new Applied ML Prototype (AMP) that will allow developers to quickly create and augment new knowledge bases from data on their own website, as well as pre-built connectors that will enable customers to quickly set up ingest pipelines in AI applications.
In the AMP, Pinceone’s vector database uses these knowledge bases to imbue context into chatbot responses, ensuring useful outputs. More information on this AMP and how vector databases add context to AI applications can be found in our blog post here.
AI ecosystem accelerators | Hugging Face, Ray:
Highlights:
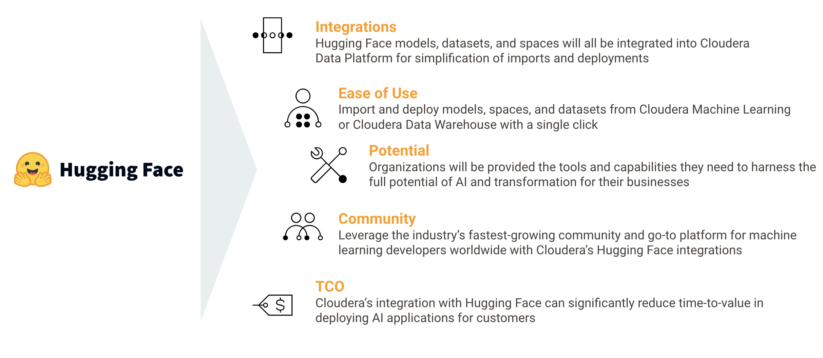
Cloudera is integrating Hugging Faces’ market-leading range of LLMs, generative AI, and traditional pre-trained machine learning models and datasets into Cloudera Data Platform so customers can significantly reduce time-to-value in deploying AI applications. Cloudera and Hugging Face plan to do this with three key integrations:
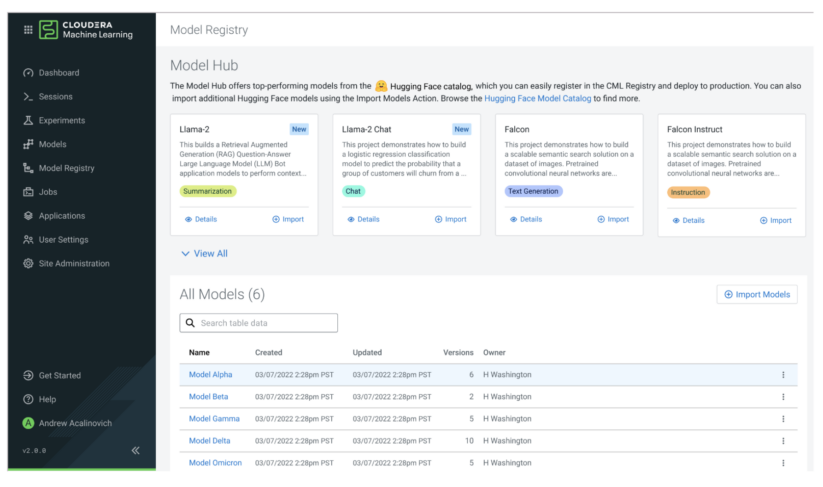
Hugging Face Models Integration: Import and deploy any of Hugging Face’s models from Cloudera Machine Learning (CML) with a single click.
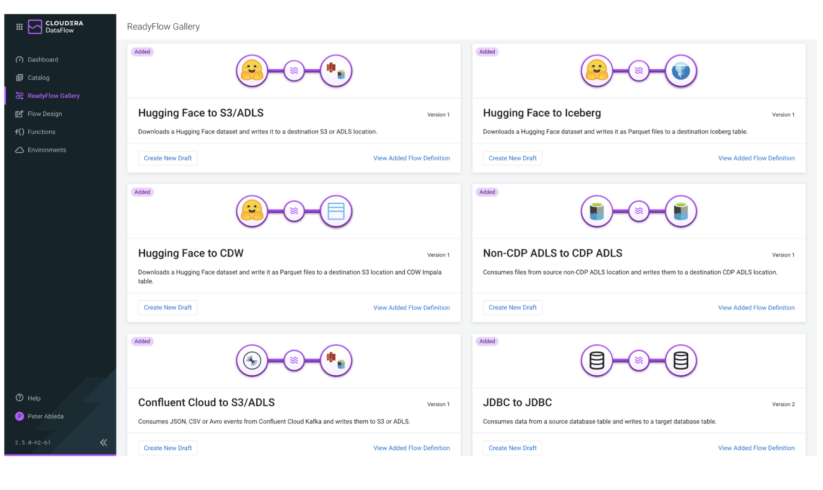
Hugging Face Datasets Integration: Import any of Hugging Face’s datasets via pre-built Cloudera Data Flow ReadyFlows into Iceberg tables in Cloudera Data Warehouse (CDW) with a single click.
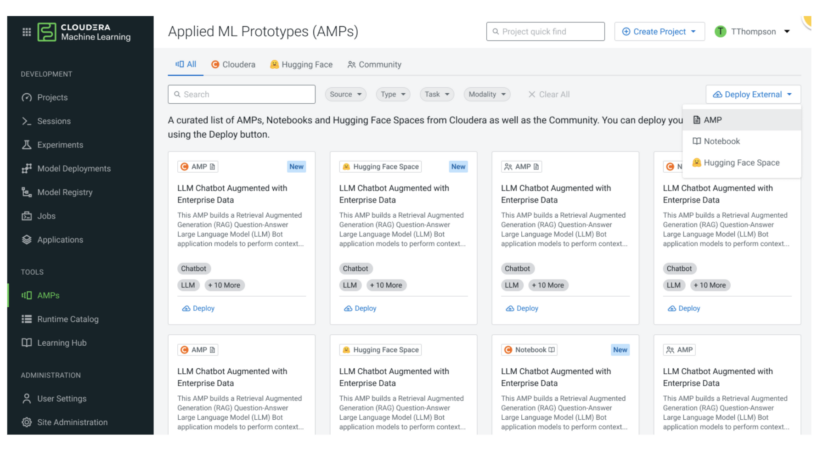
Hugging Face Spaces Integration: Import and deploy any of Hugging Face’s Spaces (pre-built web applications for small-scale ML demos) via Cloudera Machine Learning with a single click. These will complement CML’s already robust catalog of Applied Machine Learning Prototypes (AMPs) that allow developers to quickly launch pre-built AI applications including an LLM Chatbot developed using an LLM from Hugging Face.
Ray | Distributed Compute Framework
Lost in the talk about OpenAI is the tremendous amount of compute needed to train and fine-tune LLMs, like GPT, and generative AI, like ChatGPT. Each iteration requires more compute and the limitation imposed by Moore’s Law quickly moves that task from single compute instances to distributed compute. To accomplish this, OpenAI has employed Ray to power the distributed compute platform to train each release of the GPT models. Ray has emerged as a popular framework because of its superior performance over Apache Spark for distributed AI compute workloads.
Ray can be used in Cloudera Machine Learning’s open-by-design architecture to bring fast distributed AI compute to CDP. This is enabled through a Ray Module in cml extension’s Python package published by our team. More information about Ray and how to deploy it in Cloudera Machine Learning can be found in our blog post here.
Editor's Choice

