


Data is core to decision making today and organizations often turn to the cloud to build modern data apps for faster access to valuable insights. With cloud operating models, decision making can be accelerated, leading to competitive advantages and increased revenue. Can you achieve similar outcomes with your on-premises data platform? You absolutely can. Application modernization initiatives have led to cloud native architectures gaining popularity on premises, making it a sensible choice to extend to your data platform.
In the blogs that follow, as part of this multi-part series, we will shed light on the latest and greatest features released via Cloudera Data Platform (CDP) Private Cloud Data Services. These include data recovery service, quota management, node harvesting, optimizing TCO, and more.
CDP Private Cloud Data Services 1.5.0, Cloudera’s latest iteration of its best-in-class data platform, delivers cloud native superpowers on premises. At its core, CDP Private Cloud Data Services (“the platform”) is an end-to-end cloud native platform that provides a private open data lakehouse. It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment. The platform offers advanced capabilities for data warehousing (DW), data engineering (DE), and machine learning (ML), with built-in data protection, security, and governance. Let’s look at what a cloud native powered data platform can achieve for your compute-hungry data workloads.
What is cloud native exactly?
According to Cloud Native Computing Foundation (CNCF), cloud native applications use an open source software stack to deploy applications as microservices, packaging each part into its own containers, and dynamically orchestrating those containers to optimize resource utilization. This is exactly how the platform was designed from the ground up.
Traditional monolithic data platforms are complex, constraining end users who need quick access to insights and requiring technical IT support. Today’s end users demand speed, agility, and cutting-edge features. This is exactly where cloud native architectures excel, and why they are so popular.
Adopting a cloud native data platform architecture empowers organizations to build and run scalable data applications in dynamic environments, such as public, private, or hybrid clouds. Not only does this deliver faster and richer data services that end users expect, but also enables IT teams to operate a well-oiled platform with benefits such as simpler management and improved security.
What business benefits do cloud native architectures deliver?
Cloud native architectures empower your business users to quickly and easily access data to deliver timely insights and make critical business decisions for their LOBs. By embracing a cloud native architecture for your data platform here are three key benefits you can expect for your data practitioners:
- Greater agility allows for faster deployment of self-service data applications, enabling business users to quickly adapt to changing market conditions and enjoy a better user experience with your data platform.
- Better innovation, first by enabling end users to adopt new features faster for better insights, and second, by allowing developers to run experimental workloads without risking production stability, fostering a culture of innovation.
- Reduced cost by optimizing compute utilization to run more analytics with the same hardware allocation. Quick adoption of software updates further lowers maintenance costs.
Key technology benefits of cloud native architectures
Simpler platform management makes it easier for your IT platform team to service your data practitioners’ needs, and meet downstream business SLAs. As with the business benefits above, there are three key ways that cloud native architectures help simplify platform management:
- Easily scale data platform resources to optimize hardware utilization and minimize costs for on-demand workloads.
- Enhance platform resilience with automatic recovery from application failures and faster adoption of security measures, greatly improving overall platform reliability to meet SLAs.
- Achieve true hybrid portability with “write once, run anywhere” capabilities, facilitating movement of applications and data between on-premises and public cloud environments without code changes help to optimize for cost, scalability, resilience, innovation, and/or ESG initiatives.
Now let’s unpack the cloud native “superpowers” that enable these business and technology benefits, namely workload isolation, independent scaling of storage and compute, and the ability to shift capacity to where it’s needed.
Workload Isolation
The platform makes workload isolation simpler. It’s powered by Kubernetes, providing container-level resource isolation by using namespaces. Secondly, it uses Apache Yunikorn, a modern, enterprise-grade resource scheduler for Kubernetes, enhancing resource utilization and providing strong user, group, and application isolation.
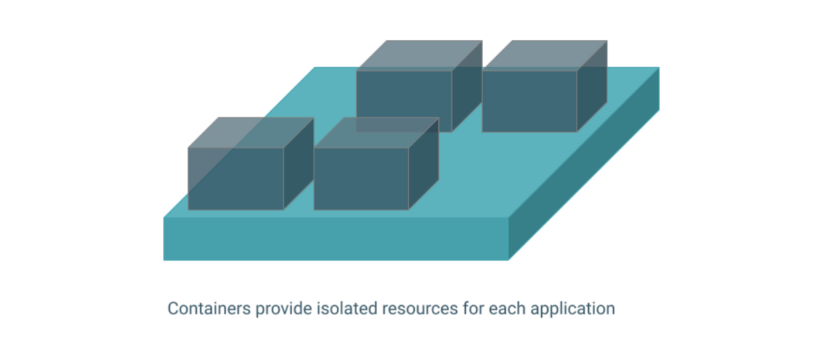
Through workload isolation the platform can deliver many of the business and technology benefits previously covered, including scalable compute, self-service analytics, workload resilience, independent upgrades, and application portability.
Scaling Storage and Compute
With evolving business needs and expanding data use cases, it becomes critical to scale compute and storage resources independently to avoid waste, sub-optimal workload performance, and incurring unnecessary costs. The platform separates compute and storage by default, allowing flexible scaling to meet varied workload demands more efficiently.
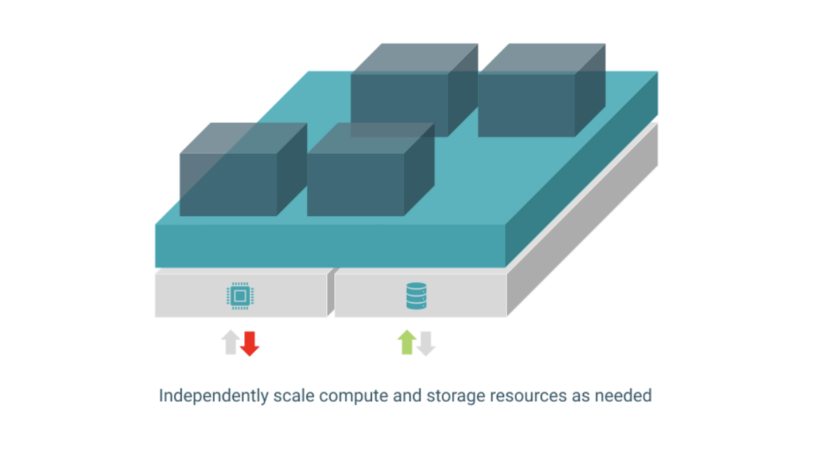
Platform Managers can easily determine when and where to scale compute or storage resources, reacting quickly to changing demands—if a use case needs more data storage, buy more storage without attached compute, and vice-versa.
Shifting Capacity
The platform leverages Kubernetes’ auto-scaling, self-healing, and load balancing features for maximized resource utilization, creating spare capacity that is available for other tasks.
- Horizontal Pod Autoscaling (HPA) adjusts pod replicas based on CPU or memory utilization, scaling your application automatically.
- Kubernetes has a self-healing mechanism that monitors the health of your application and automatically restarts any failed containers or pods to minimize downtime.
- Kubernetes’ load balancing distributes traffic across multiple pods running an application to prevent overload and handle high traffic.
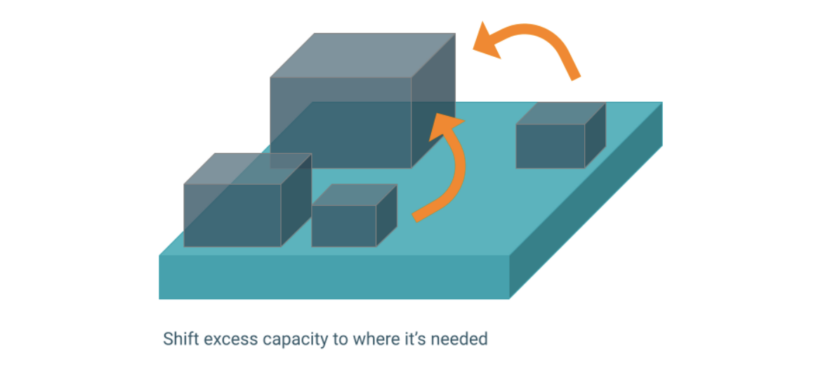
Shifting available capacity based on expected demand optimizes overall server utilization, yielding benefits for business and technology teams we previously covered, such as lower costs and better scalability.
Unified Data Platform
CDP Private Cloud Data Services is a unified data platform that provides on-premises flexibility with cloud-like capabilities. Enterprise solution architects benefit from the platform’s security, portability, and economies of scale, while data practitioners and citizen data scientists enjoy the simplicity of the cloud native user experience. Customers can standardize on a single data platform that consistently meets their processing, security, and governance needs, whether on-premises or in the public cloud, offering unmatched portability. This flexibility allows customers to choose where their workloads run, for the right platform at the right time and economics.
Adopting a cloud native architecture is essential for thriving in today’s fast-paced economy. Cloudera Data Platform empowers businesses to manage data assets and applications efficiently and securely, running millions of jobs daily across exabytes of data. CDP provides the speed, flexibility, and scalability required to drive insights for successful decision-making. To learn more about CDP Private Cloud Data Services, please visit our website and contact your sales representatives to learn about free trials.
Editor's Choice

