

Introduction and Rationale
The release of Cloudera Data Platform (CDP) Private Cloud Base edition provides customers with a next generation hybrid cloud architecture. This blog post provides an overview of best practice for the design and deployment of clusters incorporating hardware and operating system configuration, along with guidance for networking and security as well as integration with existing enterprise infrastructure.
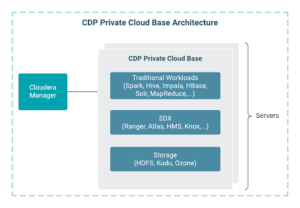
Private Cloud Base Overview
CDP Private Cloud Base is an on-premise version of Cloudera Data Platform that combines the best of Cloudera Enterprise Data Hub and Hortonworks Data Platform Enterprise in addition to new features and enhancements across the stack. This unified distribution is a scalable and customizable platform where you can securely run many types of workloads.
Further information and documentation https://docs.cloudera.com/cdp-private-cloud/latest/overview/topics/cdpdc-overview.html
Summary of major changes
Before we dive into the Best Practices, it’s worth understanding the key improvements that CDP delivers over legacy distributions.
- Best of CDH & HDP, with added analytic and platform features
- The storage layer for CDP Private Cloud, including object storage
- Cloudera SDX for consistent security and governance across the platform
- Traditional data clusters for workloads not ready for cloud
For customers to gain the maximum benefits from these features, Cloudera best practice reflects the success of thousands of -customer deployments, combined with release testing to ensure customers can successfully deploy their environments and minimize risk.
Recommended deployment patterns
The open source software ecosystem is dynamic and fast changing with regular feature improvements, security and performance fixes that Cloudera supports by rolling up into regular product releases, deployable by Cloudera Manager as parcels. Customers are well advised to maintain alignment with these releases in order to benefit from the continuous improvements. Adjacent test and development environments can then be used to validate escalating these changes into production. For those that are unable to connect Cloudera Manager directly or via proxy to the Cloudera software distribution site, they should create an offline mirror of the repository. Customers should also periodically and where possible schedule the submission of cluster diagnostic bundles and benefit from new support features such as validations on https://my.cloudera.com/ when making major changes.
Many customers will wish to automate their cluster deployment to achieve high quality uniformity and repeatability. The recently released Cloudera Ansible playbooks provide the templates that incorporate best practices described in this blog post and can be downloaded from https://github.com/cloudera-labs/cloudera-deploy
The playbooks contain templates for all of the typical cluster roles with tasks that make use of the Cloudera Manager API to simplify the implementation of builds and security.
Role allocation
A typical cluster will be composed of a number of different roles that will require specific memory, disk layouts and in some instances network connectivity in order to optimise performance and resilience. Each role is classified as follows:
Master
Nodes containing “master” roles that will typically manage their set of services operating across the distributed cluster. These include the HDFS NameNode, YARN ResourceManager, Impala Catalog/Statestore, HBase Master Server, and Kudu Masters. There should be a minimum of three master nodes, two of which will be HDFS Namenodes and YARN Resource Managers. All three will be quorums of Zookeepers and HDFS Journal nodes to track changes to HDFS Metadata stored on the Namenodes. A minimum ensemble of 3 is required to achieve a majority consensus. In clusters of more than 200 nodes, five master nodes may be appropriate.
Worker
Nodes containing roles that do most of the compute/IO work for their corresponding services. HDFS DataNodes, YARN NodeManagers, HBase RegionServers, Impala Daemons, Kudu Tablet Servers and Solr Servers are examples of worker roles.
Edge or Gateway
Edge nodes act as a gateway between the rest of the corporate network and the CDP Private Cloud cluster. Many CDP Private Cloud services come with “gateway roles” that would reside here, along with endpoints for REST API calls and JDBC/ODBC type connections coming from the corporate network. Often it is simpler to set up perimeter security when you allow corporate network traffic to only flow to these nodes, as opposed to allowing access to Masters and Workers directly.
Ingest
Typically ingest nodes will follow a similar pattern to utility nodes. The key requirements for ingest are a number of dedicated disks for both the Kafka broker roles and the Nifi roles. Kafka disk sizing warrants its own blog post however the number of disks allocated are proportional to the intended storage and durability settings, and/or required throughput of the message topics with at least 3 broker nodes for resilience.
Utility
Utility nodes contain services that allow you to manage, monitor, and govern your cluster. Such services include Cloudera Manager (CM) and associated Cloudera Management Services (CMS), the Hive metastore RDBMS (if co-located on the cluster) storing metadata on behalf of a variety of services and perhaps your administrator’s custom scripts for backups, deploying custom binaries and more.
Networking
Busy clusters can generate significant east-west network traffic therefore customers are advised to enable LACP link aggregation to a leaf-spine network with distribution-layer and top-of-rack switches. An oversubscription ratio of at most 1:4, with ideally a minimum of 2x10Gbps or even 2x25Gbps NICs to future proof CDP Private Cloud Experiences and future separation of storage and compute. Generally speaking multi-homing is not supported and we find it should not be needed for most Hadoop architectures as it can lead to significant Hadoop traffic leaking onto the wrong network interfaces disrupting non production networks and impacting performance. IPV6 is not supported and should be disabled.
For larger clusters that are spread across multiple physical racks we recommend customers take advantage of CDP’s rack awareness features. YARN attempts to place compute work close to the data within a rack, minimizing network traffic across racks and HDFS will ensure that each block is replicated to more than one rack.
Customers will implement firewalls at the perimeter of the cluster, the amount of network traffic and ports used for intra cluster communication is significant. Many services such as Spark will use ephemeral ports in order that application master roles such as the Spark driver can maintain command and control of executors that are performing work. Externally facing services such as Hue and Hive on Tez (HS2) roles can be more limited to specific ports and load balanced as appropriate for high availability.
Cloudera supports running CDP Private Cloud clusters with SELinux in permissive mode, however Cloudera does not provide SELinux policy configurations to enable enforcing mode. If a customer requires SELinux enforcement, they need to test and implement the policies themselves. Given the complexity of the platform, Cloudera recommends sticking to permissive mode or disabling SELinux altogether.
Please review the full networking and security requirements.
Operating System Disk Layouts
Most customers will install the operating system on a mirrored pair of 4TB or more disks, these can be partitioned using logical volume manager ensuring sufficient storage for logs and temporary files. It should be noted that /tmp filesystem and logging requirements can be significant and customers should be careful to ensure sufficient space is available. Additionally we also recommend customers disable Transparent Huge Pages (THP), the tuned daemon, and minimize swapping.
Supported file systems are ext3, ext4 and XFS, typically most customers will use XFS v5 for data directories, these will usually be mounted as directly attached JBOD disks in order to maximise I/O performance for HDFS of the form /data1, /data2, dataN for each respective data disks, typically 12-24 4-8Tb disks with a maximum of 100Tb per node supported. The disk access pattern for master services is somewhat different with dedicated disks recommended for Zookeeper and HDFS journal nodes and some resilient storage such as RAID 5 or 10 for HDFS NameNode directories. Disks should be mounted as noatime in order to improve read performance. Full details for hardware requirements are described in the release guide.
CDP is particularly sensitive to host name resolution, therefore it’s vital that the DNS servers have been properly configured and hostnames are fully qualified. Clocks must also be synchronized. The name service caching daemon can help on larger clusters providing a local cache for common name service requests such as passwords groups and hosts.
Supporting infrastructure services
An RDBMS Database is required for Hive, Atlas, Ranger, Cloudera Manager, Hue and Oozie. https://docs.cloudera.com/cdp-private-cloud-base/latest/installation/topics/cdpdc-database-requirements.html and should be deployed with both resilience and performance in mind as under performing database will have an adverse impact on the cluster performance.
Security integration
Cluster security warrants its own blog post however for basic security integration the cluster will need to resolve users and groups via the corporate directory. Authentication and directory services are typically done via a combination of kerberos and LDAP which is advantageous as it simplifies password and user management whilst integrating with existing corporate systems such as Active Directory.
Kerberos is used as the primary authentication method for cluster services composed of individual host roles and also typically for applications. Enterprise clusters will use the existing corporate directory, such as Microsoft Active Directory, for the creation and management of those kerberos principals. Additionally, Apache Knox provides an authentication endpoint for cluster REST APIs and UIs supporting LDAP and SAML.
Authorisation
Apache Ranger provides the key policy framework that defines user access rights to resources. Security administrators can define security policies at the database, table, column, and file levels, and can administer permissions for specific LDAP-based groups, roles or individual users. Data flow and streaming (NiFi, Kafka, etc.) policies can also be defined.
Apache Ranger enables authorisations to be maintained via corporate group membership using tools such as sssd or Centrify to synchronise access rights to services and data with the corporate directory. These authorisations are then periodically synchronized with the underlying Hive objects.
Communications between cluster services are encrypted using TLS 1.2 security to provide strong authentication, integrity and privacy on the wire. Cloudera Manager simplifies TLS certificate management by incorporating a feature called AutoTLS which allows administrators to define and deploy a fully integrated Public Key Infrastructure layout.
Summary
In summary we have provided a reference for the tuning and configuration of the host resources in order to maximise the performance and security of your cluster. In part 2 of this series of blog posts we will take a closer look at how to manage, monitor and tune your applications to benefit from the reference layout. In the meantime you can get started by downloading the latest version of CDP Private Cloud Base edition.
Editor's Choice

