

In Part 1: Infrastructure Considerations in this three part revamped series on deploying clusters like a boss, we provided a general explanation for how nodes are classified, disk layout configurations and network topologies to think about when deploying your clusters.
In this Part 2: Service and Role Layouts segment of the series, we take a step higher up the stack looking at the various services and roles that make up your Cloudera Enterprise deployment. There are so many capabilities and configurations possible in CDH to meet a variety of demands. To help focus our discussion, we zero in on three different product offerings and how they would be deployed in your enterprise. These layouts will ensure you’re meeting high availability and full security demands while setting your cluster up for stability as you continue to scale out whether on-prem or in the cloud.
Part 2: Service and Role Layouts
There are many different approaches you can take when architecting your next cluster, depending on your goals and problems you’re intending to solve. We will assume that high availability and security is a must. Our goal is to define service and role layout examples for different purpose driven environments, defined by three different product offerings – Analytic DB, Operational DB, and Data Engineering.
Getting started on the cloud today with these products couldn’t be easier. Earlier in 2017, Cloudera Altus Data Engineering was launched as a first tier, platform as a service cloud offering enabling you to quickly submit jobs to clusters configured on demand for data engineering workloads. More recently, Cloudera Altus Analytic DB (Beta) platform as a service on the cloud provides environments targeting instant analytics going beyond just SQL.
Let’s jump right in and cover how you would architect your on-prem or custom cloud solutions (unmanaged) as we cover the placement and layouts of the services and roles available in our product. See the Cloudera Products page for more product ideas to build purpose-built clusters.
Analytic DB
Analytic Database is backed by the following set of core, high level components.
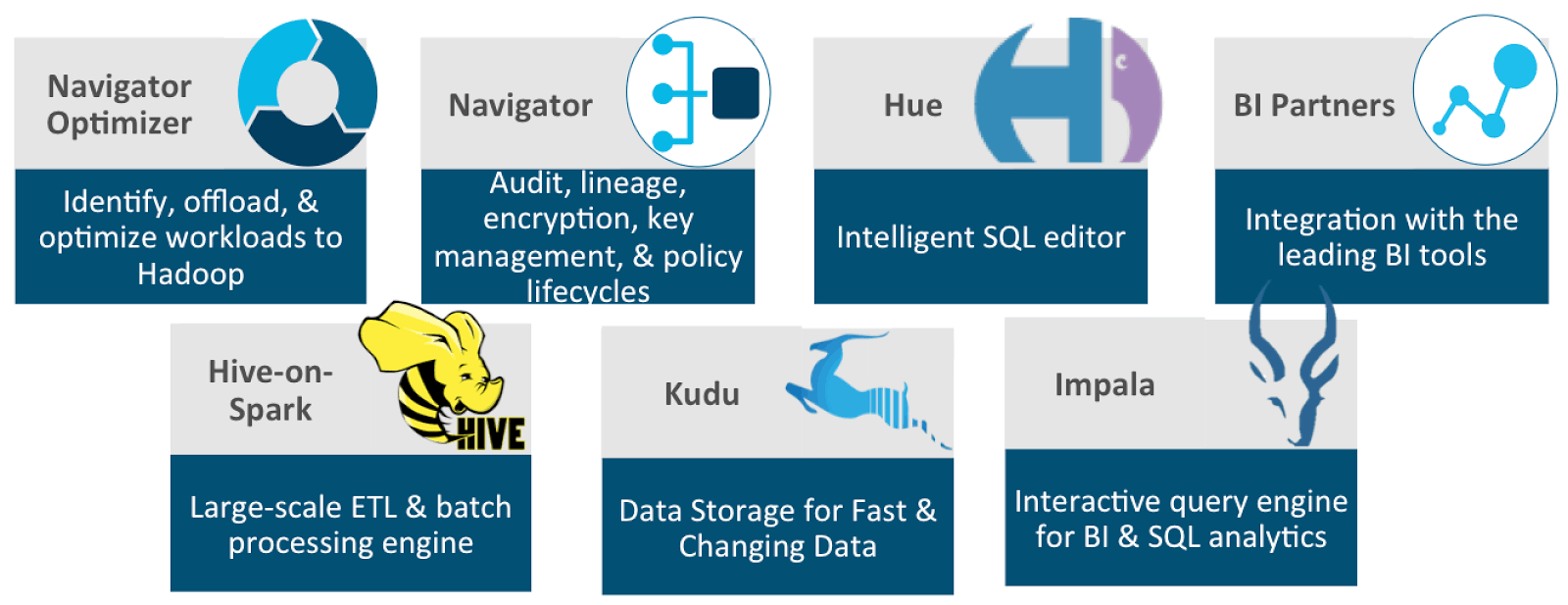
Navigator Optimizer is a Cloudera product that is not installed on your cluster directly, rather it is a cloud service we provide at Cloudera to help identify, offload and optimize workloads from traditional RDBMS systems over to your Cloudera cluster.
Similarly, BI Partners may not directly run within the cluster, though they often make JDBC/ODBC connections to the Impala service in order to provide Business Intelligence through ad-hoc BI queries and/or meaningful reports.
Navigator, Hue, Hive-on-Spark, Kudu and Impala are components very much a part of the cluster, that require a set of other services in order to properly function in the overall ecosystem.
The services may be assigned as shown in the following diagram:
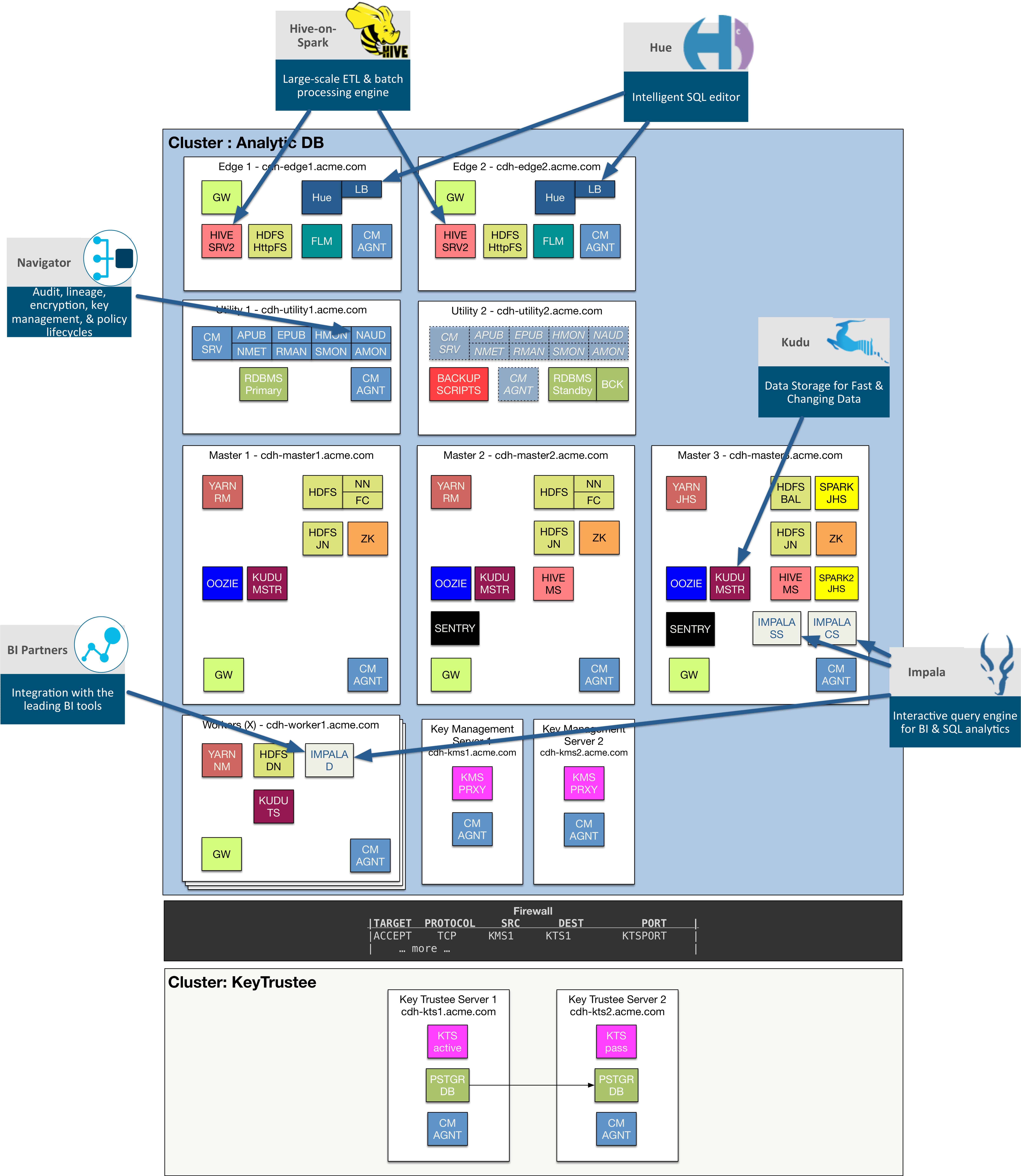
Analytic DB Specific Components
Hue: Hue servers reside on the edge nodes, and may scale out as required by adding additional edge nodes. Hue is made available with a built-in load balancer as well, which also may be installed on multiple edge nodes. User traffic should be directed to these load balancers for high availability as well as performance, since not only users distributed across Hue servers, but static UI elements are cached on the load balancers providing an overall better user experience.
Cloudera Navigator: Resides on one of the utility nodes typically co-located with Cloudera Manager server. It may run alongside the rest of Cloudera Management Services or may be pulled out to be on its own utility node when clusters grow significantly in size.
Hive: HiveServer2 services reside on the edge nodes and may further scale out by adding additional edge nodes as required. The Hive Metastore Servers are across two master nodes in active-active mode.
Spark and Spark2: Spark needs a place for the JobHistory Server for both Spark and Spark2 separately. We place those on one of the master nodes. Spark binaries are installed throughout the cluster and Spark’s gateway services reside both on the edge and worker nodes.
Kudu: Kudu Master roles are deployed across all the master nodes while Tablet Servers reside on the worker nodes.
Impala: Impala’s StateStore and Catalog Service are installed on a single master. These are stateless services meaning they can be brought up again at any time on any node if the node becomes completely unavailable. Impala Daemons are installed across all worker nodes, and third-party BI tools may connect to any one of these daemons to submit SQL requests. Typically, these requests would be driven by a 3rd party load balancer.
Other core components supporting Analytic DB
Cloudera Manager (CM): Every cluster is managed by CM which is deployed on the utility nodes. The Cloudera Management Services are similarly typically installed on the same utility node. The second utility node may act as a cold standby for CM, by which we mean if the first utility node fails, we can install and bring up CM on a second utility node.
Of course, we can also configure CM for high availability with a load balancer to automatically failover to the standby utility node. CM agents are installed on all hosts that are part of the cluster.
Note that in the above diagram, there are actually two CM managed clusters – one for Analytic DB cluster and the second for the KeyTrustee cluster supporting full encryption.
Metastore RDBMS: Utility nodes can be used for the Active-Standby configuration of the RDBMS. RDBMS backups may be considered to be taken on the less-used second utility node.
YARN: The ResourceManager (Active-Standby) and YARN JobHistory Server are spread out across the master nodes. YARN gateway on the edge while NodeManagers reside on all the workers.
HDFS: The NameNode (Active-Standby), JournalNodes, Failover Controllers and HDFS Balancer are spread across the master nodes. HDFS gateway and HttpFS instances are deployed on the edge nodes while DataNodes reside on the workers.
ZooKeeper: ZooKeeper instances are spread across the master nodes.
Oozie: Oozie operates in active-active mode, and can both scale or just provide high availability in case one of the Oozie servers fails. It is advisable to point workloads to a load balancer which will help direct traffic to an available Oozie service.
Sentry: Sentry (Active-Standby) servers are rolled out across a pair of master nodes.
Flume: Flume services reside on edge nodes and may scale out simply by adding more edge nodes. Remember that multiple flume agents may run on a single node as well as long as agents are listening on different ports from one another.
Firewalls: The CDH cluster should be fenced off by a firewall from the rest of the corporate network, but there should also be a firewall between the CDH cluster and the KeyTrustee cluster as shown in the diagram.
Key Management Server: Resides on a pair of dedicated nodes that are part of the CDH cluster.
KeyTrustee Server: Resides on a pair of dedicated nodes in its own KeyTrustee cluster, managed by the same Cloudera Manager as the CDH cluster. It too contains a database and service that is enabled transparently in Active-Standby mode.
Operational DB
Operational Database is backed by the following set of core, high level components:
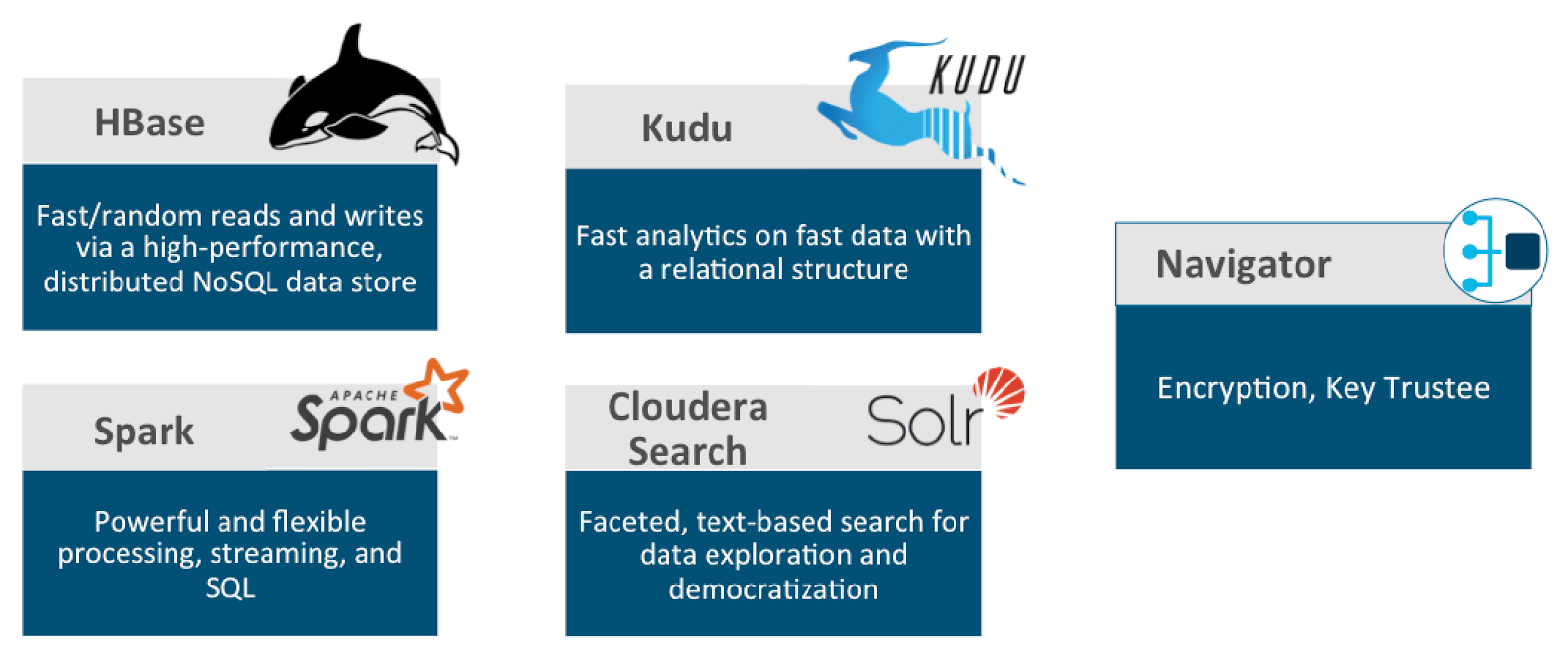
Many of the core components already described above in the section, “Other core components supporting Analytic DB” also support Operational DB components. We particularly highlight Navigator Encrypt and Key Trustee in this section although encryption may be applied to any cluster.
HBase, Kudu and Solr provide various low-latency insert, update, delete and fetch storage options for a variety of operational use cases. Solr is further enhanced by Hue, which is why we include Hue in this cluster, to quickly provide a way to create a Search dashboard.
Spark is used here not only for powerful processing capabilities, but SQL as well as streaming to quickly bring data into this cluster.
Finally, with streaming, we include a cluster specific to Kafka, which is often a key component in many streaming architectures, particularly pipelines that come from upstream producers with Spark Streaming consumers landing data in HBase, Kudu or Solr.
The services may be assigned as shown in the following diagram:

Operational DB Specific Components
HBase: Deploy a set of HBase Masters (HMaster) across the master nodes. RegionServers are deployed on all the worker nodes. High availability is coordinated via ZooKeeper determining which HMaster requests should be directed to.
Cloudera Search: Cloudera Search is made up of a few components, including Solr which is deployed across all the worker nodes. Hue is another element of Cloudera Search providing capabilities for search dashboards. If a Solr server fails, Solr collections should be replicated across multiple Solr servers allowing for full high availability.
Kudu: See description in the Analytic DB portion, as Kudu service role layout is the same.
Spark and Spark2: See description in the Analytic DB portion, as Spark service role layouts are the same.
Navigator: Navigator encrypt and Key Trustee were already described in the Analytic DB portion above.
Kafka: Kafka should reside in its own cluster, though it may be managed by the same Cloudera Manager managing Operational DB cluster. A separate ZooKeeper cluster is deployed along with a pair of Sentry roles across the first few Kafka Brokers. Flume services may also exist on Kafka Brokers as required to pull data from upstream sources using Flume Sources, and providing events into the Kafka cluster either with Kafka sinks or Kafka channels.
The rest of the services are common across platforms, which have been already described earlier in the Analytic DB portion.
Data Science and Engineering
Data Science and Engineering is backed by the following set of core, high level components.
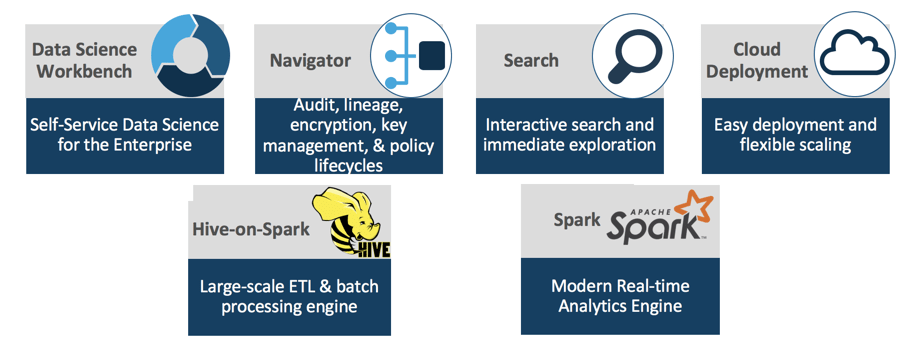
These components provide all the familiar and performant tools needed to address all aspects of predictive analytics. You will be able to perform advanced, exploratory data science and machine learning at scale regardless of being on-premise, across public clouds or both.
Data Science Workbench is a modern, fully featured, secure, flexible and scalable environment enabling data scientists to explore and drive insight on all their data like never before. It provides access to data through programming languages such as R, Python and Scala with favorite libraries and frameworks.
Maintaining audit, lineage, encryption, key management and more through Navigator is still critical in this multi-tenant environment having your data scientists and engineers coming from various parts of the organization and having a deep understanding of how data is interacted with.
Another must have tool in the data scientist’s toolkit is the ability to search through various types of data sets using Hue and Solr. Even still, traditional SQL access to datasets through Hive remains invaluable while Spark is the go-to standard for processing this data at scale.
Finally, all these tools are enabled and optimized for the cloud for easier deployments and flexible scaling.
The services may be assigned as shown in the following diagram:
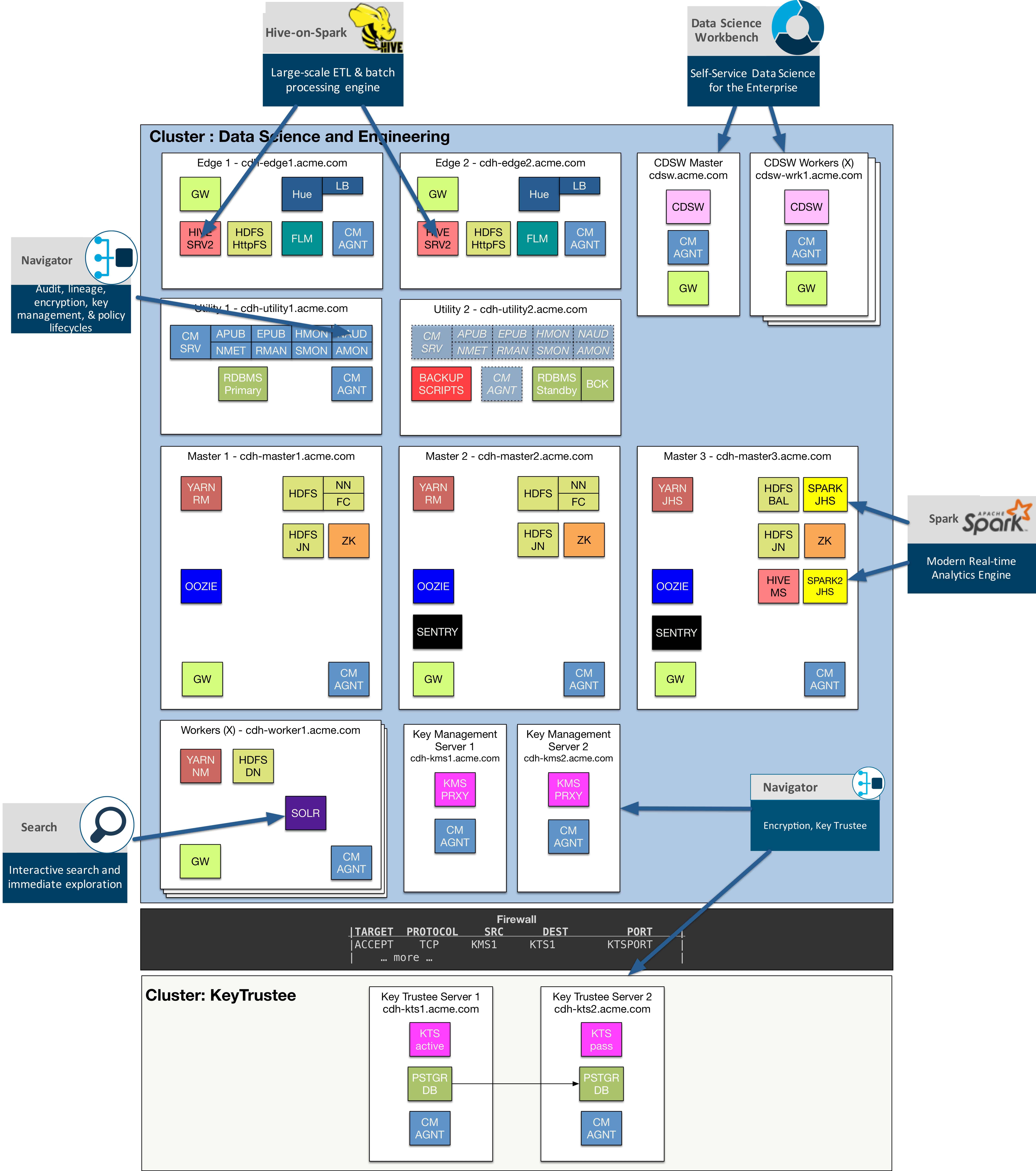
Data Science and Engineering Specific Components
The only notable service not mentioned anywhere in the sections above under Analytic DB or Operational DB, is the Cloudera Data Science Workbench (CDSW). For all other components making up this offering, Navigator, Search, Hive-on-Spark, and Spark, refer to earlier sections describing the placement of these services.
Cloudera Data Science Workbench (CDSW): CDSW consists initially of a single Master node that may also act as a Worker node to start. As you onboard more data scientists and engineers leveraging this capability, you can scale out by adding additional Worker nodes. A wildcard subdomain, such as *.cdsw.acme.com is necessary to provide isolation for user-generated content and be sure to check out additional requirements and scaling guidelines outlined in the CDSW requirements and supported platforms documentation.
Conclusion
In this Part2: Service and Role Layouts blog post, we covered in depth where Cloudera services and roles should be placed across the various nodes in your clusters. We did this by using three different product offerings as use cases for building purpose built clusters which can be deployed both on-premise and in the public cloud. Watch for Part 3 of this series where we will cover cloud specific considerations when deploying Cloudera Enterprise.
Editor's Choice

