

At Cloudera, we’re always working to provide our customers and the Apache Spark community with the most robust, most reliable software possible. This article describes some recent engineering work on [SPARK-8425] that is available in CDH 5.10 and CDH5.11, as well as in upstream Apache Spark starting with the 2.2 release.
The work pertains to the Blacklist Tracker mechanism in Spark’s scheduler. This was the subject of a recent Spark Summit talk, “Fault Tolerance in Spark: Lessons Learned from Production”. A video of the talk is available here: https://youtu.be/OPPg4JeWkzs.
In the remainder of this article, we’ll describe the work we’ve done to increase Spark’s reliability and resilience to errors. We’ll introduce the problem, examine the shortcomings of the previous solution, introduce our solution, and explain how to configure Spark to use our solution.
Problem Synopsis: Spark error recovery causes application failure
Problem Description:
Apache Spark, by design, is tolerant to many classes of faults. It builds on top of the ideas originally espoused by Google’s MapReduce and GoogleFS papers over a decade ago to allow a distributed computation to soldier on even if some nodes fail. The core idea is to expose coarse-grained failures, such as complete host failure, to the driver, so that it may decide how best to deal with the failure.
In general, this design works quite well. The driver communicates with executors constantly. If an executor or node fails, or fails to respond, the driver is able to use lineage to re-attempt execution. This design makes Spark tolerant to most disk and network issues. It also makes Spark performant, since checkpointing can happen relatively infrequently, leaving more cycles for computation.
Every now and again, we find an exceptional use case that challenges fault tolerance. This was such a case.
In rare instances, a single failed disk can cause the scheduler to attempt re-execution in such a way that a user’s job will fail. Here is one scenario that, prior to our work on [SPARK-8425], would have triggered such a failure:
- One disk on one host has an intermittent failure that causes some sectors to not be read. The disk is still “available” to the operating system, and other reads and writes succeed, but reads and writes related to execution tend to fail. This leads to a task failure.
- The driver sees that the task has failed and re-submits the task to the scheduler for recovery using lineage.
- The scheduler receives the request from the driver and makes a scheduling decision for where to run the task. Taking locality and load into account, the scheduler tends to re-execute this task on the same host, possibly even the same executor.
- After encountering the same failure repeatedly, the driver gives up, and kills the job, assuming that it will never finish. This leads to a complete failure to the end user.
All of this can happen so quickly that a cluster manager (such as Apache YARN) is unable to detect this failure and take its own corrective action. Moreover, Apache Spark is unable to directly communicate failures to YARN as this is a potential denial-of-service vector.
Solution:
To solve this problem, Cloudera engineering worked closely with the Apache Spark community to enhance the scheduler with a blacklist to enhance the scheduler’s ability to track failures, using a blacklist. The blacklist is a software mechanism that maintains a record of executors and hosts that have had prior failures.
When a task fails on an executor, the blacklist tracks which executor – and which host – was associated with the failure. After a certain number of failures, two by default, the scheduler will no longer schedule work on that node or host. Optionally, the scheduler can kill a failing executor, or even kill all the failing executors on a particular host. Please see the “Configuration” section below for further details.
The blacklist feature allows for configuration of the number of retries for a task, the number of failures before a resource is no longer available for scheduling, the amount of time a blacklist entry is valid, and whether or not to attempt to kill blacklisted resources.
Starting in Apache Spark 2.2 and Cloudera’s release of Apache Spark 2.1, the Apache Spark Web UI is able to communicate the “blacklisted” state to an end user. The scheduler also prints log messages when the blacklist is updated, and when a scheduling decision takes the contents of the blacklist into consideration. The screenshot below demonstrates this feature.
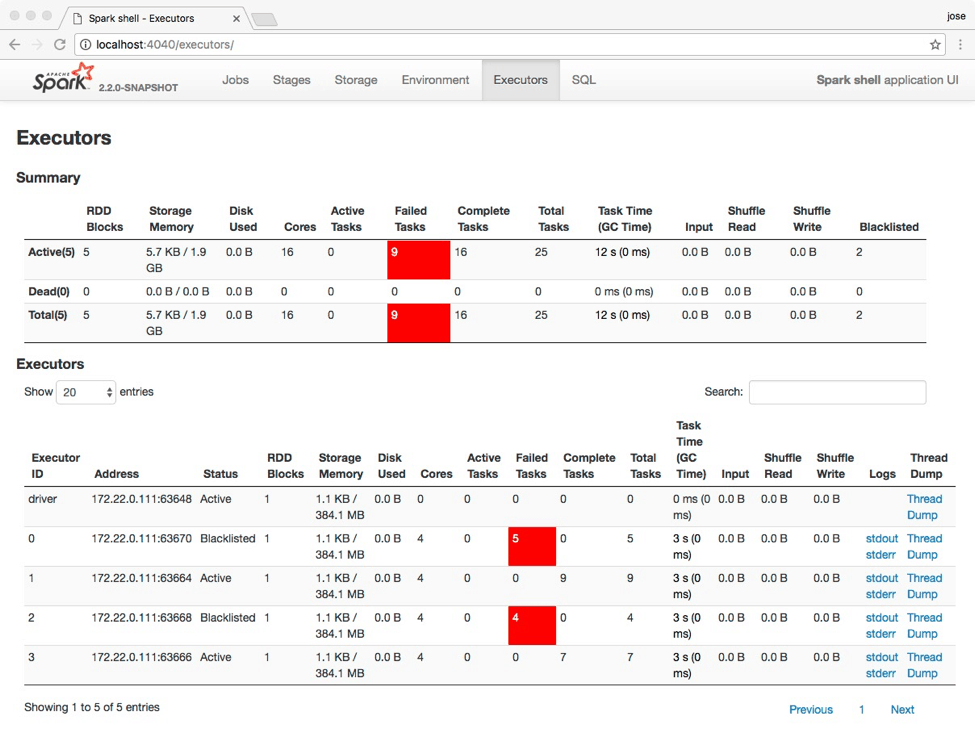
Spark application UI demonstrating the new “blacklisted” state in the Summary and Executors views.
Conclusion: Node with Failing Disk
As we discussed in the Problem Description, without the blacklist mechanism, a single node with a single failing disk could cause an entire Spark job to grind to a halt by hitting a series of edge cases. Here, we walk through the same scenario, with the blacklist mechanism enabled.
Steps 1, 2, and 3 proceed as before. The change comes with Step 4:
- After encountering the failure repeatedly, the driver decides that this executor and/or this node is unreliable. The driver removes the executor or node from the pool of available compute resources, and retries the task somewhere else. It likely succeeds and the user’s job continues transparently.
We’re replaced an application failure with an error that is recovered transparently to the user.
Configuration:
As of this writing, the following configuration keys will enable or alter the blacklist mechanism:
spark.blacklist.enabled – set to True to enable the blacklist.
spark.blacklist.task.maxTaskAttemptsPerExecutor (1 by default)
spark.blacklist.task.maxTaskAttemptsPerNode (2 by default)
spark.blacklist.application.maxFailedTasksPerExecutor (2 by default)
spark.blacklist.stage.maxFailedTasksPerExecutor (2 by default)
spark.blacklist.application.maxFailedExecutorsPerNode (2 by default)
spark.blacklist.stage.maxFailedExecutorsPerNode (2 by default)
spark.blacklist.timeout (not set by default)
spark.blacklist.killBlacklistedExecutors (false by default)
For additional details on how to configure this updated blacklisting mechanism, please consult the documentation provided with your version of Apache Spark.
Credits:
This was a community effort. Imran Rashid, Tom Graves, and Kay Ousterhout were all instrumental in this fix. Mark Hamstra, Saisai Shao, Wei Mao, Mridul Muralidharan, and the author were involved in design discussions and code reviews as well.
Glossary:
For definitions of the terms driver, executor, host, job, lineage, locality, node, scheduler, and task, please consult the Apache Spark documentation at http://spark.apache.org/docs/latest/index.html, or the documentation provided with your version of Spark.
Further Reading:
[SPARK-8425] is the primary bug for blacklisting upstream, and details how the design of the blacklist mechanism evolved over time to its final state.
The Design Document for the Blacklist Mechanism describes out, in more detail, the scenarios that we needed to balance in the design process of the blacklist.
[SPARK-16654] and [SPARK-16554], respectively, are upstream feature requests tracking UI visibility for this blacklist feature, and logic to automatically kill failing executors if desired.
Editor's Choice

