


There are two clear trends in the big-data ecosystem: the growth of machine learning use cases that leverage large distributed data sets, and the growth of Spark’s Machine Learning libraries (often referred to as MLlib) for these use cases. In fact, Spark’s MLlib library is arguably the leading solution for machine learning on large distributed data sets.
Intel and Cloudera have collaborated to speed up Spark’s ML algorithms, via integration with Intel’s Math Kernel Library (Intel® MKL).
Intel MKL is a library of optimized math routines that are hand-optimized specifically for Intel processors. For example, it includes highly-optimized routines for Linear Algebra, Fast Fourier Transforms (FFT), Vector Math and Statistics functions. These mathematical operations are building blocks for machine learning and related analytic algorithms, and thus integration with MKL delivers massive performance boost for machine learning workloads. Spark is already instrumented to take advantage of optimized implementations of these routines using netlib-java, but still requires the addition of an implementation like MKL to activate these optimizations.
The benchmark
We benchmarked performance of MKL against the default JVM based execution (referred to as F2JBLAS) and against a popular open source hardware acceleration library called OpenBLAS. For the benchmark, we used an open source suite of performance tests called spark-perf.
We selected seven popular Machine Learning Algorithms for the benchmark:
1) ALS: Alternating Least Squares for collaborative filtering
2) PCA: Principal Component Analysis
3) LDA: Latent Dirichlet Allocation
4) SVD: Singular Value Decomposition
5) Logistic Regression classifier
6) RF: Random Forest classifier
7) GBT: Gradient Boosted Tree classifier
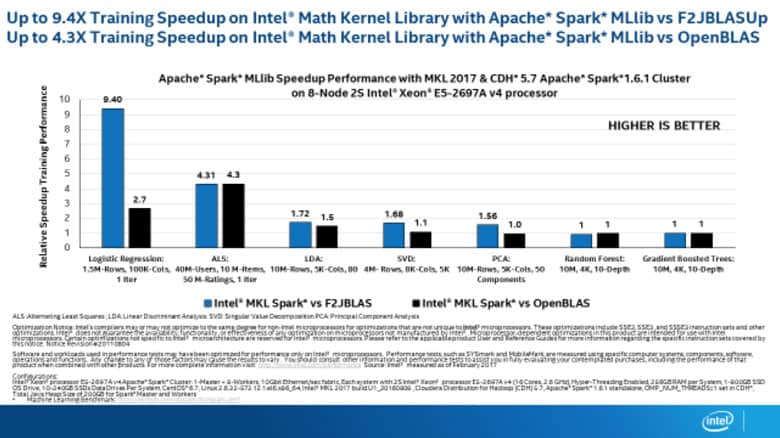
For the popular Logistic Regression algorithm (which arguably still is the most popular algorithm for building predictive analytics use cases), MKL provides an incredible 9x performance boost vs F2JBLAS, and a significant 2.5x performance boost over OpenBLAS.
ALS, which is the most popular algorithm for building recommender systems, demonstrates a resounding 4x performance boost.
As you can see, the achieved performance boost varies for different algorithms. Moreover, it should be noted that the observed performance boost will have some variation over different Intel processors. This benchmark was done on Intel® Xeon® E5-2697A processors, and more details about the hardware used for the benchmark are provided below.
Benefit to Customers: Enjoy a performance boost for free!
The best part about the performance boost with MKL is that it does not require a modified version of Spark, or modifications to your Spark application code, nor does it require procurement of extra or special hardware (after all, most data-centers in the world are running Intel processors). It merely requires a few steps to install MKL on your cluster. Moreover, we will soon simplify the installation process by providing MKL as a parcel which can be installed on your entire CDH cluster via two simple clicks in Cloudera Manager.
The benefits of these performance gains are clear: improved performance means you can train with larger data sets, explore a larger range of the model hyper-parameter space, and train more models. In many cases, it alleviates the need to buy any specialized hardware for your Machine Learning workloads.
This is another example of the strong partnership between Intel and Cloudera delivering business value to our customers. We are only getting started. We will continue to collaborate and deliver compelling features that will provide significant benefits for data science and machine learning use cases across our customers.
Benchmark hardware and software specs:
The benchmark was run on an 8 node cluster where each node had: 2 Intel® Xeon® E5-2697A v4 processors with 16 Cores, 2.6 GHz, Hyper-Threading Enabled, 256GB RAM, 1-800GB SSD OS Drive, 10-240GB SSDs Data Drives. The cluster had 10Gbit Ethernet/sec fabric.
We used Spark 1.6 running on CentOS* 6.7.
Editor's Choice

