

HDFS now includes (shipping in CDH 5.8.2 and later) a comprehensive storage capacity-management approach for moving data across nodes.
In HDFS, the DataNode spreads the data blocks into local filesystem directories, which can be specified using dfs.datanode.data.dir in hdfs-site.xml. In a typical installation, each directory, called a volume in HDFS terminology, is on a different device (for example, on separate HDD and SSD).
When writing new blocks to HDFS, DataNode uses a volume-choosing policy to choose the disk for the block. Two such policy types are currently supported: round-robin or available space (HDFS-1804).
Briefly, as illustrated in Figure 1, the round-robin policy distributes the new blocks evenly across the available disks, while the available-space policy preferentially writes data to the disk that has the most free space (by percentage).
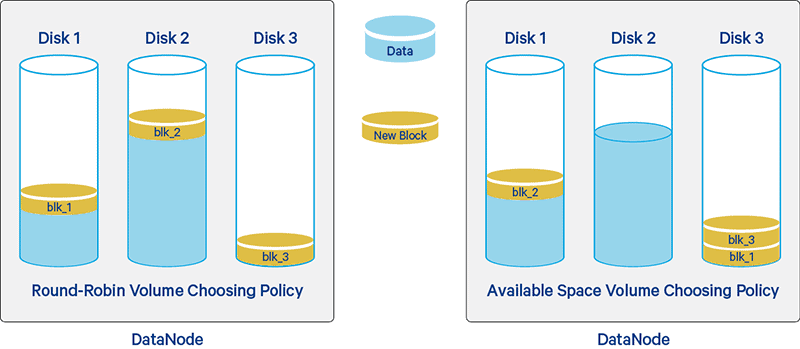
By default, the DataNode uses the round-robin-based policy to write new blocks. However, in a long-running cluster, it is still possible for the DataNode to have created significantly imbalanced volumes due to events like massive file deletion in HDFS or the addition of new DataNode disks via the disk hot-swap feature. Even if you use the available-space-based volume-choosing policy instead, volume imbalance can still lead to less efficient disk I/O: For example, every new write will go to the newly-added empty disk while the other disks are idle during the period, creating a bottleneck on the new disk.
Recently, the Apache Hadoop community developed server offline scripts (as discussed inHDFS-1312, the dev@ mailing list, and GitHub) to alleviate the data imbalance issue. However, due to being outside the HDFS codebase, these scripts require that the DataNode be offline before moving data between disks. As a result, HDFS-1312 also introduces an online disk balancer that is designed to re-balance the volumes on a running DataNode based on various metrics. Similar to the HDFS Balancer, the HDFS disk balancer runs as a thread in the DataNode to move the block files across volumes with the same storage types.
In the remainder of this post, you’ll learn why and how to use this new feature.
Disk Balancer 101
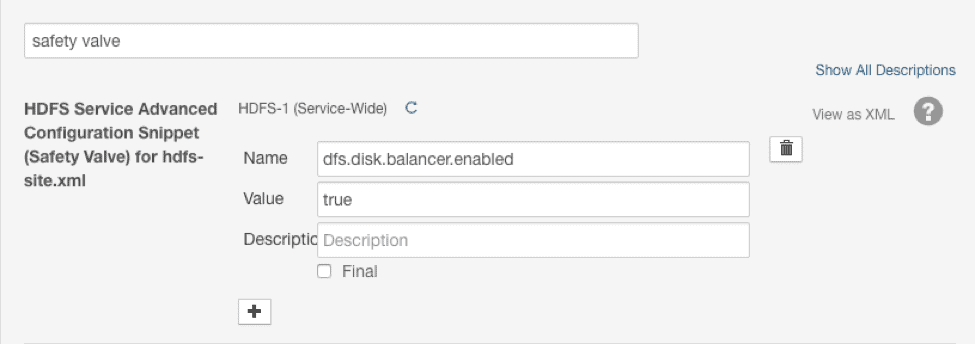
Let’s explore through this useful feature step-by-step using an example. First, confirm that the dfs.disk.balancer.enabled configuration is set to true on all DataNodes. From CDH 5.8.2 onward, a user can specify this configuration via the HDFS safety valve snippet in Cloudera Manager:
In this example, we will add a new disk to a pre-loaded HDFS DataNode (/mnt/disk1), and mount the new disk to /mnt/disk2. In CDH, each HDFS data directory is on a separate disk, so you can use df to show disk usage:
# df -h …. /var/disk1 5.8G 3.6G 1.9G 66% /mnt/disk1 /var/disk2 5.8G 13M 5.5G 1% /mnt/disk2
Obviously, it’s time to make the disks balanced again!
A typical disk-balancer task involves three steps (implemented via the hdfs diskbalancer command): plan, execute, and query. In the first step, the HDFS client reads necessary information from the NameNode regarding the specified DataNode to generate an execution plan:
# hdfs diskbalancer -plan lei-dn-3.example.org 16/08/19 18:04:01 INFO planner.GreedyPlanner: Starting plan for Node : lei-dn-3.example.org:20001 16/08/19 18:04:01 INFO planner.GreedyPlanner: Disk Volume set 03922eb1-63af-4a16-bafe-fde772aee2fa Type : DISK plan completed.Th 16/08/19 18:04:01 INFO planner.GreedyPlanner: Compute Plan for Node : lei-dn-3.example.org:20001 took 5 ms 16/08/19 18:04:01 INFO command.Command: Writing plan to : /system/diskbalancer/2016-Aug-19-18-04-01
As you can see from the output, the HDFS disk balancer uses a planner to calculate the steps for the data movement plan on the specified DataNode, by using the disk-usage information that DataNode reports to the NameNode. Each step specifies the source and the target volumes to move data, as well as the amount of data expected to move.
At the time of this writing, the only planner supported in HDFS is GreedyPlanner, which constantly moves data from the most-used device to the least-used device until all data is evenly distributed across all devices. Users can also specify the threshold of space utilization in the plan command; therefore, the planner considers the disks balanced if the difference in space utilization is under the threshold. (The other notable option is to throttle the diskbalancer task I/O by specifying --bandwidth during the planning process, so that the disk balancer I/O will not influence foreground work.)
The disk-balancer execution plan is generated as a JSON file stored in HDFS. By default, the plan files are saved under the /system/diskbalancer directory:
# hdfs dfs -ls /system/diskbalancer/2016-Aug-19-18-04-01 Found 2 items -rw-r--r-- 3 hdfs supergroup 1955 2016-08-19 18:04 /system/diskbalancer/2016-Aug-19-18-04-01/lei-dn-3.example.org.before.json -rw-r--r-- 3 hdfs supergroup 908 2016-08-19 18:04 /system/diskbalancer/2016-Aug-19-18-04-01/lei-dn-3.example.org.plan.json
To execute the plan on DataNode, run:
$ hdfs diskbalancer -execute /system/diskbalancer/2016-Aug-17-17-03-56/172.26.10.16.plan.json 16/08/17 17:22:08 INFO command.Command: Executing "execute plan" command
This command submits the JSON plan file to the DataNode, which executes it in a background BlockMover thread.
To check the status of the diskbalancer task on the DataNode, use the query command:
# hdfs diskbalancer -query lei-dn-3:20001 16/08/19 21:08:04 INFO command.Command: Executing "query plan" command. Plan File: /system/diskbalancer/2016-Aug-19-18-04-01/lei-dn-3.example.org.plan.json Plan ID: ff735b410579b2bbe15352a14bf001396f22344f7ed5fe24481ac133ce6de65fe5d721e223b08a861245be033a82469d2ce943aac84d9a111b542e6c63b40e75 Result: PLAN_DONE
The output (PLAN_DONE) indicates that the disk-balancing task is complete. To verify the effectiveness of the disk balancer, use df -h again to see the data distribution across two local disks:
# df -h Filesystem Size Used Avail Use% Mounted on …. /var/disk1 5.8G 2.1G 3.5G 37% /mnt/disk1 /var/disk2 5.8G 1.6G 4.0G 29% /mnt/disk2
The output confirms that the disk balancer successfully reduced the difference in disk-space usage across volumes to under 10%. Mission accomplished!
To read more details about the HDFS disk balancer, read the Cloudera docs and the upstream docs.
Conclusion
With the long-awaited intra-DataNode disk balancer feature introduced in HDFS-1312, the version of HDFS shipping in CDH 5.8.2 and later provides a comprehensive storage capacity-management solution that can move data across nodes (Balancer), storage types (Mover), and disks within a single DataNode (Disk Balancer).
Acknowledgements
HDFS-1312 was collaboratively developed by Anu Engineer, Xiaobin Zhou, and Arpit Agarwal from Hortonworks, and Lei (Eddy) Xu and Manoj Govindasamy from Cloudera.
Lei Xu is a Software Engineer at Cloudera, and a committer to Hadoop and member of the Hadoop PMC.
Editor's Choice


Hi Lei,
It’s a very good post. Was wondering does it support multiple nodes running disk balancer at the same time ? Will the name node get confused because of simultaneous disk balancing running on multiple data nodes ?
Thank you !
Hi Team,
Will this work on HDP 3.0 Cluster?