

The SparkOnHBase project in Cloudera Labs was recently merged into the Apache HBase trunk. In this post, learn the project’s history and what the future looks like for the new HBase-Spark module.
SparkOnHBase was first pushed to Github on July 2014, just six months after Spark Summit 2013 and five months after Apache Spark first shipped in CDH. That conference was a big turning point for me, because for the first time I realized that the MapReduce engine had a very strong competitor. Spark was about to enter an exciting new phase in its open source life cycle, and just one year later, it’s used at massive scale at 100s if not 1000s of companies (with 200+ of them doing so on Cloudera’s platform).
SparkOnHBase came to be out of a simple customer request to have a level of interaction between HBase and Spark similar to that already available between HBase and MapReduce. Here’s a quick summary of the functionality that was in scope:
- Full access to HBase in a map or reduce stage
- Ability to do a bulk load
- Ability to do bulk operations like get, put, delete
- Ability to be a data source to SQL engines
The initial release of SparkOnHBase was built for a Cloudera customers that had agreed to allow the work to become public. Thankfully, I got early help from fellow Clouderans and HBase PMC members Jon Hsieh and Matteo Bertozzi, and Spark PMC member Tathagata Das, to make sure the design would work both for base Apache Spark as well as Spark Streaming.
It wasn’t long before other customers started using SparkOnHBase—most notably Edmunds.com with its real-time Spark Streaming application for Super Bowl Sunday. When other companies jumped on board, it quickly became clear that a single project maintainer (namely: me) wasn’t going to scale. Fortunately, at that time, Cloudera had recently announced Cloudera Labs, which turned out to be the perfect home for the project. Put simply, Cloudera Labs is a virtual container for emerging ecosystem projects that are young in terms of their enterprise readiness, development, and ambition, but are in high demand by users who want to try the latest technologies. SparkOnHBase became a Cloudera Labs project in due course.
Today, I am happy to report that SparkOnHBase was recently committed to the HBase trunk (HBASE-13992). HBASE-13992 adds SparkOnHBase to HBase core under a new moniker, the HBase-Spark module. I want to thank HBase VP Andrew Purtell for his encouragement and “opening the door” for HBASE-13992 and PMC member Sean Busbey for his mentoring and guidance. Also, I want to thank Elliott Clark, Enis Soztutar, Michael Stack, Nicolas Liochon, Kostas Sakellis, Ted Yu, Lars Hofhansl, and Steve Loughran for their code reviews. (As you can see, SparkOnHBase was an authentic community effort.)
Notably, with HBASE-13992, I was able to add Spark and Scala code to the Apache HBase project for the first time ever. It was super-fun having the privilege to build the first Scala unit test in HBase’s history!
Now, let’s dive into the technical details.
Inside HBASE-13992
In HBASE-13992, you will see that most of the original code and design from SparkOnHBase are left unchanged. The basic architecture still holds, in that the core part of the code is designed to get an HBase connection object in every Spark Executor.
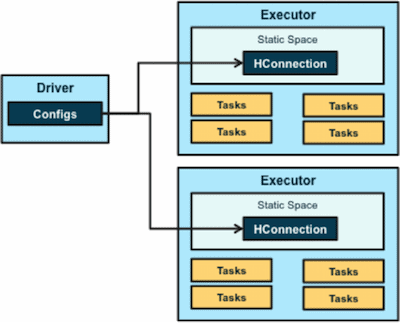
While the basics remain, there are three major differences between the HBASE-13992 patch and the Cloudera Labs SparkOnHBase project:
- HBase APIs: HBASE-13992 uses all the new HBase 1.0+ APIs throughout.
- RDD and DStream functions: One of the biggest complaints about SparkOnHBase related to how functions were executed; Spark lovers wanted to make HBase actions straight from an RDD or DStream. In HBASE-13992, that capability is baked-in via unit tests and examples. Furthermore, there are code examples of HBase functions directly off RDDs later in this post, so you can get a feel for what the APIs will look like.
- Easy
foreachandmapfunctions: Now it is even easier to doforeachPartitions andmapPartitions with a HBase connection. An example will follow later in this post.
Now, let’s take a quick minute and walk through the differences between the SparkOnHBase code base and the HBASE-13992 patch. Here is a quick example of bulkDelete from SparkOnHBase:
val hbaseContext = new HBaseContext(sc, config); hbaseContext.bulkDelete[Array[Byte]](rdd, tableName, putRecord => new Delete(putRecord), 4);
Note in this example we are calling a function straight off the HBaseContext object, even though the operation was really being executed on the RDD. So now let’s look at the HBase-Spark module for the same code:
val hbaseContext = new HBaseContext(sc, config) rdd.hbaseBulkDelete(hbaseContext, tableName, putRecord => new Delete(putRecord), 4)
The big difference is that the hbaseBulkDelete method comes straight out of the RDD. Also, this approach leaves the door open to the following options with a future JIRA:
val hbaseContext = new HBaseContext(sc, config) rdd.hbaseBulkDelete(tableName)
This is as clean as I can get it for now, but the goal is to make it even more simple and clean.
Let’s also take a quick look at the foreach and map functions in HBASE-13992. You can see in the ForeachPartition example below that we have an iterator and an HBase Connection object. This will give us full power to do anything with HBase as we iterate over our values:
val hbaseContext = new HBaseContext(sc, config)
rdd.hbaseForeachPartition(hbaseContext, (it, conn) => {
val bufferedMutator = conn.getBufferedMutator(TableName.valueOf("t1"))
...
bufferedMutator.flush()
bufferedMutator.close()
})
Finally, here is an example of a map partition function where we can get a connection object as we iterate over our values:
val getRdd = rdd.hbaseMapPartitions(hbaseContext, (it, conn) => {
val table = conn.getTable(TableName.valueOf("t1"))
var res = mutable.MutableList[String]()
...
})
Future Work
The following JIRAs are on my TO DO list:
HBASE-14150 – Add BulkLoad functionality to HBase-Spark Module
Soon we will be able to do bulk loads straight off RDDs with code that looks as simple as:
rdd.hbaseBulkLoad (tableName,
t => {
Seq((new KeyFamilyQualifier(t.rowKey, t.family, t.qualifier), t.value)).
iterator
},
stagingFolder)
HBASE-14181 – Add Spark DataFrame DataSource to HBase-Spark Module
With this patch, we will be able to directly integrate Spark SQL with HBase and do cool things like filter and column selection pushdown, along with scan-range pushdown. The goal of getting Spark SQL and HBase interaction is as simple as the following:
val df = sqlContext.load("org.apache.hadoop.hbase.spark",
Map("hbase.columns.mapping" -> "KEY_FIELD STRING :key, A_FIELD STRING c:a, B_FIELD STRING c:b,",
"hbase.table" -> "t1"))
df.registerTempTable("hbaseTmp")
sqlContext.sql("SELECT KEY_FIELD FROM hbaseTmp " +
"WHERE " +
"(KEY_FIELD = 'get1' and B_FIELD < '3') or " +
"(KEY_FIELD <= 'get3' and B_FIELD = '8')").foreach(r => println(" - " + r))
There are other JIRAs designed to make the code easier to use and making the unit test more comprehensive. My personal goal is to be able to report back in a follow-up blog post with all the great progress we are making. The aim is to turn Spark into the first-class citizen that it deserves to be with respect to HBase, further solidifying it as the MapReduce replacement in the industry. Replacing MapReduce with Spark will allow us to do even more processing on HBase clusters, without adding concern that there will be more disk IO contention.
It will take time before the HBase-Spark module makes it into a release of HBase. In the meantime, there are plans to back-port some of the code from the HBase-Spark module into SparkOnHBase in Cloudera Labs. Currently, SparkOnHBase works on CDH 5.3 and 5.4, and the goal will be to update SparkOnHBase with the HBase-Spark module advances for the upcoming CDH minor release later in 2015.
Ted Malaska is a Solutions Architect at Cloudera, a contributor to Spark, Apache Flume, and Apache HBase, and a co-author of the O’Reilly book, Hadoop Application Architectures.
Editor's Choice

