

Full-stack observability is a critical requirement for effective modern data platforms to deliver the agile, flexible, and cost-effective environment organizations are looking for. For analytic applications to properly leverage a hybrid, multi-cloud ecosystem to support modern data architectures, data observability has become even more important. I spoke to Mark Ramsey of Ramsey International (RI) to dive deeper into that last subject. RI is a global leader in the design and deployment of large-scale, production-level modern data platforms for the world’s largest enterprises.
Luke: Observability has been around for a while as a term in DevOps circles, but what is data observability? How is it different from what folks traditionally think of as observability?
Mark: Data observability rose out of the same circumstances that created that original form of observability. What we’ve seen as organizations grow and evolve is that their tech stacks become more complicated, which requires that the DevOps team also evolve their method of monitoring the health of those systems. The same is true as the data stack becomes more complicated, the method for monitoring the health of your data also needs to evolve. Data observability provides insight into the condition and evolution of the data resources from source through the delivery of the data products. See below. Barr Moses of Monte Carlo presents it as a combination of data flow, data quality, data governance, and data lineage. The data observability five pillars are: freshness, distribution, volume, schema, and lineage.
Luke: Should organizations include data observability in their modern data platform?
Mark: Yes, data observability should be included as it provides a significant acceleration in the creation of data products for business use cases.
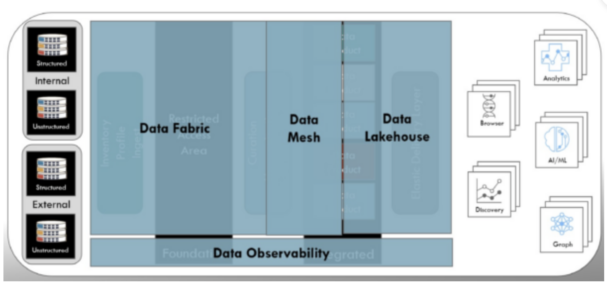
Ramsey International Modern Data Platform Architecture
Luke: Can you take us through a bit more detail on each of the pillars?
Mark: Freshness monitors the frequency of when the data resources are updated, which helps identify the most ideal data for decision making. In addition, freshness can help direct a focus toward stale data in an organization that can be pruned to reduce overall complexity.
Distribution monitors the statistical characteristics of the data resource, which is an excellent linkage with data quality. For example, having a data attribute for age that suddenly contains values of 167 or -23 can help identify areas that must be investigated. Monitoring volume provides another data quality checkpoint. Monitoring data volumes can allow for alerts in situations where a daily update suddenly goes from 2 million records to 200 million records. As the number of data sources continue to rise, monitoring schema allows an organization to quickly recognize when data format has changed due to attributes being added or removed, which can impact the downstream data ecosystem. Finally, data lineage monitoring allows the organization to understand the life cycle of each attribute.
Luke: How is data observability evolving from monitoring into more actionable insights?
Mark: As the name suggests, data observability started as the process to monitor the flow of data across the ecosystem. Leading organizations are now using the insights gained from monitoring to drive positive impacts on the other components of the platform. For example, historically the process of acquiring data from the source systems to populate the data lake was plagued by schema drift. As the schema of the source data changed, it caused the traditional extract, transform, and load (ETL) processes to fail. The data fabric replaces ETL with data pipelines, which are by design more resilient to schema changes, but action may still be required. The insights around the change in schema coupled with the knowledge of the use of attributes within the data products drive a more resilient data pipeline. The addition of a new attribute, or the removal of an attribute that is not being used within a data product, is handled as a warning message versus causing the entire process to fail.
Luke: What, within the data fabric, is required to allow for this interoperability?
Mark: It is critical that the technologies selected within the data fabric provide the foundation for capturing and leveraging the insights from data observability. A data catalog is the repository for the metrics captured within the data observability process. This means having an open and robust data catalog within the data fabric is one of the key components for interoperability. The other important factor is having technologies in the data fabric that can make use of the data observability insights and add to the metrics.
Luke: Can data observability have an impact on data mesh?
Mark: Data observability metrics can have a significant impact on the work being done within the data mesh teams. Rather than being limited by a manual curation process, using the insights from data observability allows the teams to dynamically understand the potential alignment of the data. Coupling the areas of distribution, volumes, and schema provides an organization insight into each attribute in the data landscape to a level that drives automated curation using analytics.
Luke: Why is data observability becoming more important for organizations that are implementing a modern data management platform?
Mark: IDC has forecasted that the creation of data will grow at a compound annual growth rate (CAGR) of nearly 25% into 2025. Of the estimated 64.2ZB of data created or replicated in 2020, less than 2% was retained into 2021. Overall, the amount of data being stored is expected to grow at a 19.2% rate over the next five years. The data fabric must be built to handle the ever-larger amounts of data, the data mesh teams must become more efficient in producing expanded data products, and data observability is becoming more important as it is key to understand the flow and content of that massively increasing amount of data.
Source: IDC
Editor's Choice

