



With the release of CDP Private Cloud (PvC) Base 7.1.7, you can look forward to new features, enhanced security, and better platform performance to help your business drive faster insights and value. We understand that migrating your data platform to the latest version can be an intricate task, and at Cloudera we’ve worked hard to simplify this process for all our customers.
We’re pleased to share that with this release, we’ve enabled our CDH 6.x customers to upgrade in-place to CDP PvC Base without having to create a new cluster. This completes our vision to bring in-place upgrades to all our customers on traditional platforms, enabling both CDH 5/6 and HDP 2/3 customers to upgrade to CDP PvC Base using their existing hardware, and without the need to stand up an additional cluster. In-place upgrades may be the most suitable path for many large, complicated environments, but we have a number of alternative paths available to make your transition fit your needs. We recommend reading through The Four Upgrade and Migration Paths to CDP from Legacy Distributions for a good summary of the additional options.
For a detailed list of what’s included in CDP PvC Base 7.1.7, please review the Release Summary. Some of the highlights of this release include:
- Cloudera Manager enhancements for greater efficiency and hardened platform security. The platform provides stronger security and corporate compliance by drastically reducing the number of open CVEs with upgrades to 20+ embedded third party libraries.
- Enhanced analytic features that deliver faster SQL queries and ETL with Hive on Tez and Impala, improved Spark with support for Spark 3.1 and NVidia RAPIDS libraries, and HBase performance improvements.
- Apache Ozone enhancements deliver full High Availability providing customers with enterprise-grade object storage and compatibility with Hadoop Compatible File System and S3 API.
- SDX enhancements for improved platform and data governance, including the following notable features:
- Impala Row Filtering to set access policies for rows when reading from a table. This helps simplify Impala queries and provides row-level security for each table. We expand on this feature later in this blog.
- Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafka metadata and metadata lineage in the Atlas UI.
- Additional databases, operating systems, and development environments are now supported for better integration and compatibility, including support for RHEL8.
- Upgrade enhancements delivering in-place upgrades for CDH versions 6.1.x, 6.2.x, and 6.3.x, as well as documented rollback procedures to help customers with their move to CDP PvC Base, as mentioned in the blog introduction.
The above list are just key highlights of the CDP PvC Base 7.1.7 release that we’d like to draw your attention to. For details of all the features included, please review the official release summary here.
We’ll use the remainder of this blog to illustrate how three of these features from this release improve the platform – Impala Row Filtering, Atlas / Kafka integration, and Ranger Audit Filters & Policies.
Deep Dive 1: Impala Row filtering
Thanks to integration of Apache Ranger and Apache Impala we are now able to bring Ranger Row Level Filtering to Impala. Alongside column filtering and column masking, this means that it is possible to specify policies that will limit access to rows and columns within a table based on a user’s id, role, group or via custom expressions; row filtering effectively adds an automatic ‘WHERE’ clause. This feature will be useful to any customers that have a requirement to store and process sensitive or regulated information where previously filtering would only have been possible via a complex set of views and permissions.
As an example, you may wish to restrict sales data based on membership of a specific regional group in order to limit the overall visibility of market-sensitive data. In the example below we have granted SELECT to members of a number of sales groups.
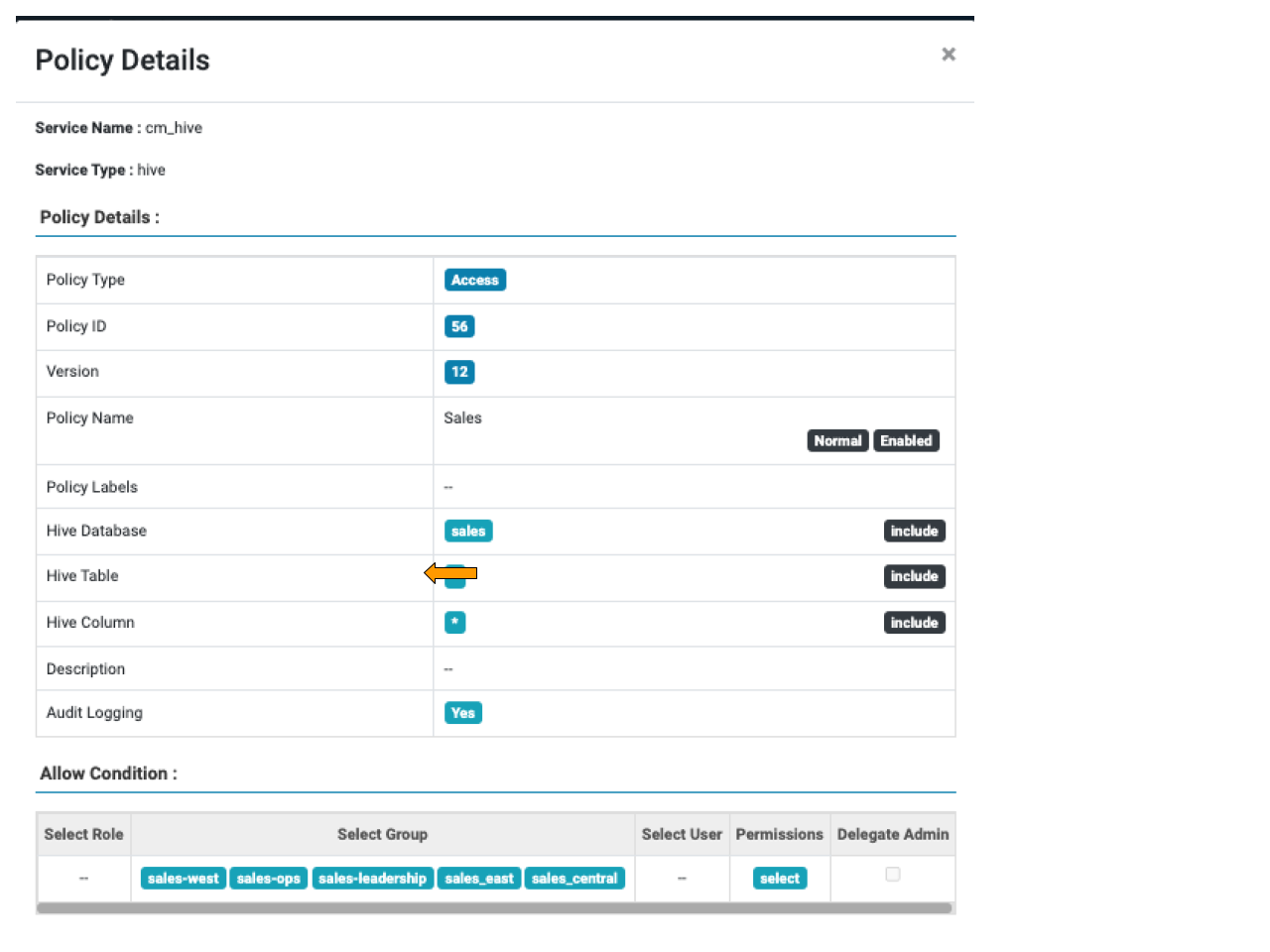
Figure 1: sales group SELECT access
On top of this we can specify a Row Level Filter that, for members of the sales_east, sales_west and sales_central groups, will apply a predicate based on the region column.
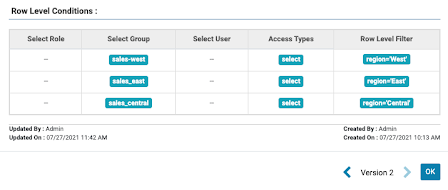
Figure 2: row level filtering setup for each sales group
Now, when this query is executed in Impala, the user scott (who is a member of sales_leadership; see the access policy in figure 1) can see all rows, but the user test1 (who is a member of sales_west; see the row filtering policy in figure 2) is restricted only to the rows where the region is equal to ‘West’.
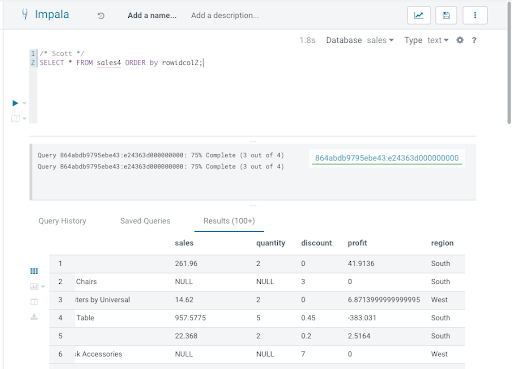
Figure 3: query executed as ‘scott’ returning all region details
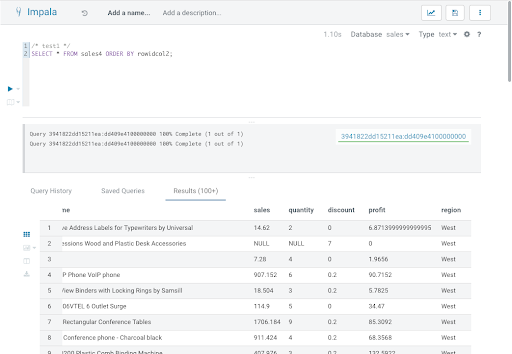
Figure 4: query executed as ‘test1’ returning only west region details
Because Ranger is passing the filtering down to Impala’s query engine itself, we can even take advantage of performance enhancements such as column statistics, dictionary filtering and partition pruning. As a result, the performance of certain queries is improved through use of Row Filtering.
As the row level filter may be composed using any valid WHERE clause, more predicates based on SQL expressions can be used, including by referencing other tables. The example below shows how a table called user_lookups can be referenced with the filter composed based on the actual user ID.
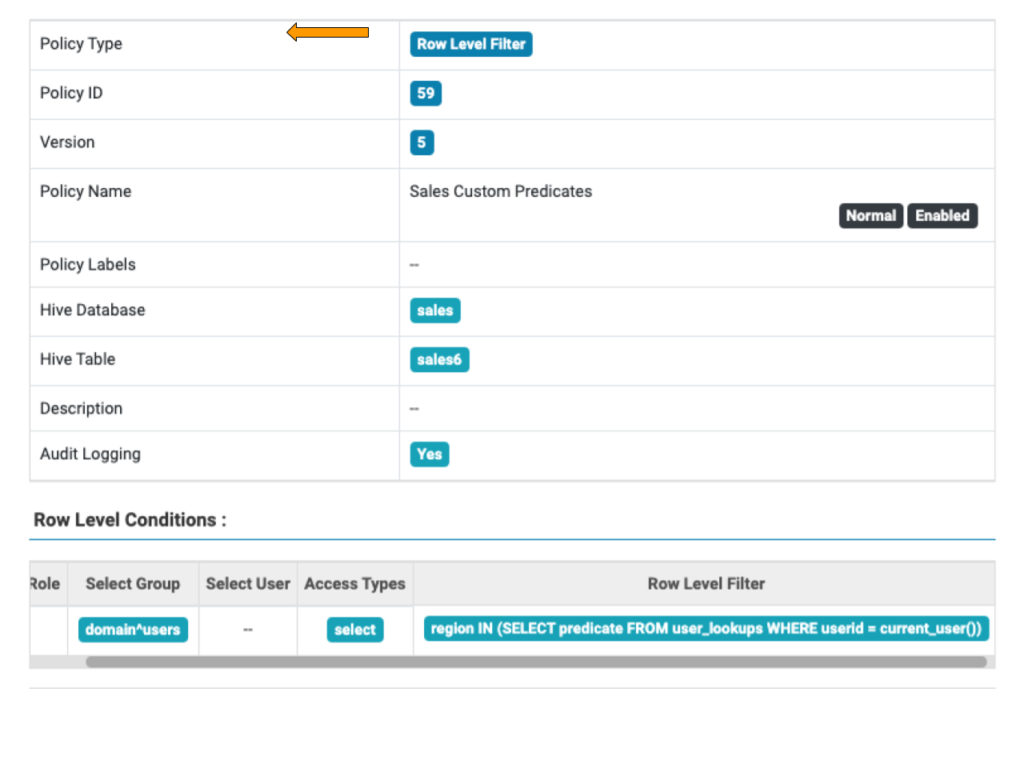
Figure 5: Row Level Filter containing SQL expression
Deep Dive 2: Atlas / Kafka integration
The Atlas – Kafka integration is provided by the Atlas Hook that collects metadata from Kafka and stores it in Atlas. Once the metadata is in Atlas, administrators can now fully manage, govern and monitor the Kafka metadata and the data lineage using the Atlas UI. This requires no changes to Consumers or Producers. All the auditing is performed on the Brokers.
To enable the Atlas Hook, the Atlas service needs to be deployed on the Kafka cluster or the data context cluster. Once that is installed please go to the Kafka Service in Cloudera Manager and select the Enable Auditing to Atlas option. This will expose newly created Kafka topics to Atlas. For existing topics we have provided an import tool called Kafka Import which helps import the existing metadata manually into Atlas.
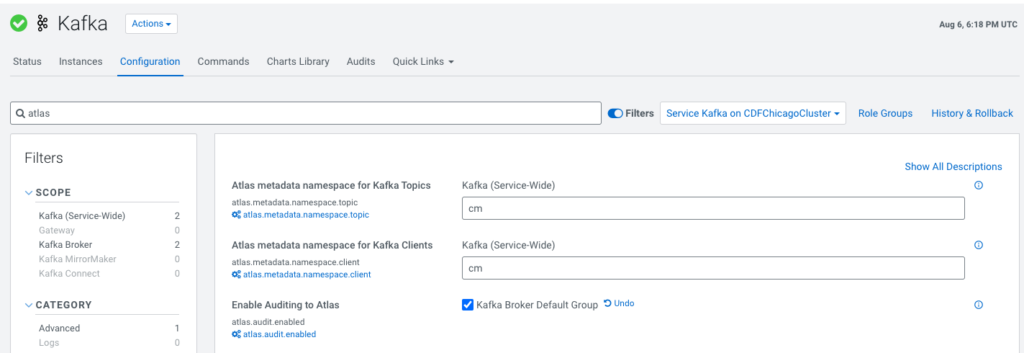
Figure 6: Atlas Hook configuration in Kafka cluster
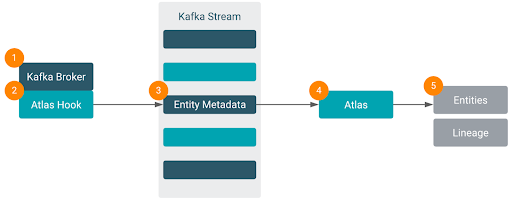
Figure 7: Kafka ATlas Hook feeding through to Atlas Entities and Lineage
Atlas auditing of Kafka topics is only supported for Kafka consumers using version 2.5 and above.
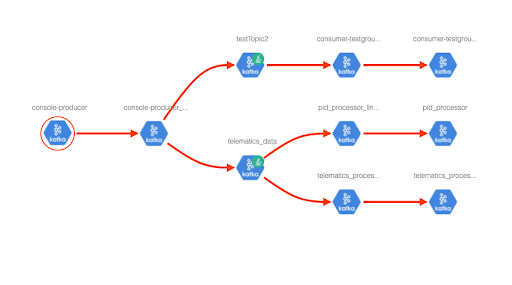
Figure 8: Data lineage based on Kafka Atlas Hook metadata
The producer and consumer lineage is displayed from the metadata collected using the Atlas hook in the lineage tab.
Deep Dive 3: Ranger Audit Filters and Policies
Further improvements in Ranger include the addition of audit events for HDFS superusers and a way of defining audit filters to reduce the amount of potential noise in the audit logs. As a result it is easier to find the relevant audit data and the amount of storage required for audit data is reduced.
New deployments of CDP Private Cloud Base 7.1.7 will include a default set of audit policies, which can be viewed via the Ranger UI by clicking on the “edit” button next to the service (e.g. “cm_hdfs”, “cm_hbase”).
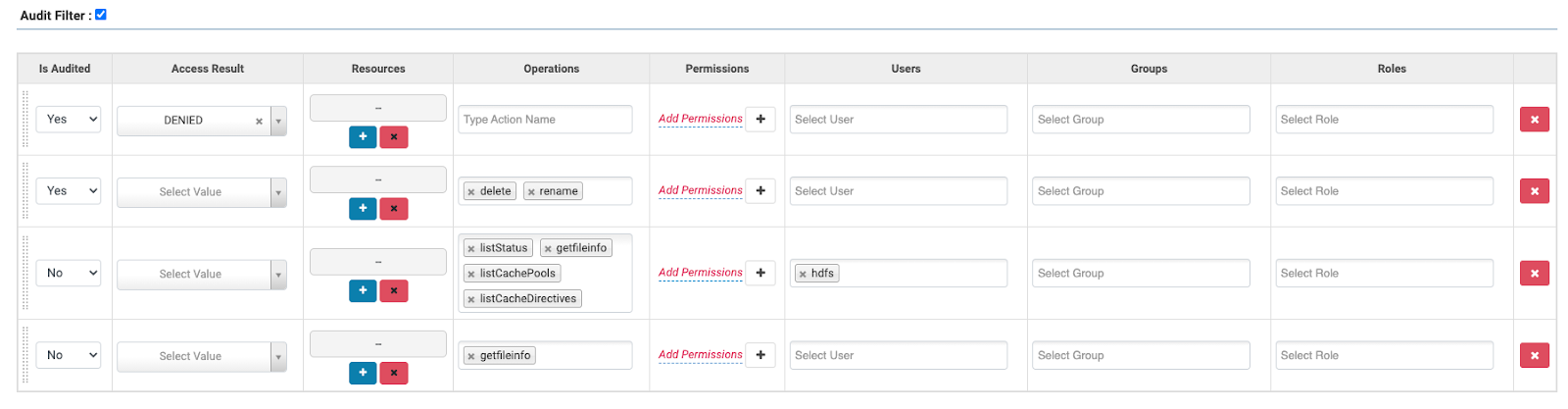
Figure 9: Default Audit filters
The default filters exclude certain internal operations by the hdfs user and also the “getfileinfo” event. These operations are standard HDFS internal operations that would not normally be of audit interest, although you can re-enable the auditing if you require. Using the UI we can create our own policies, as follows:
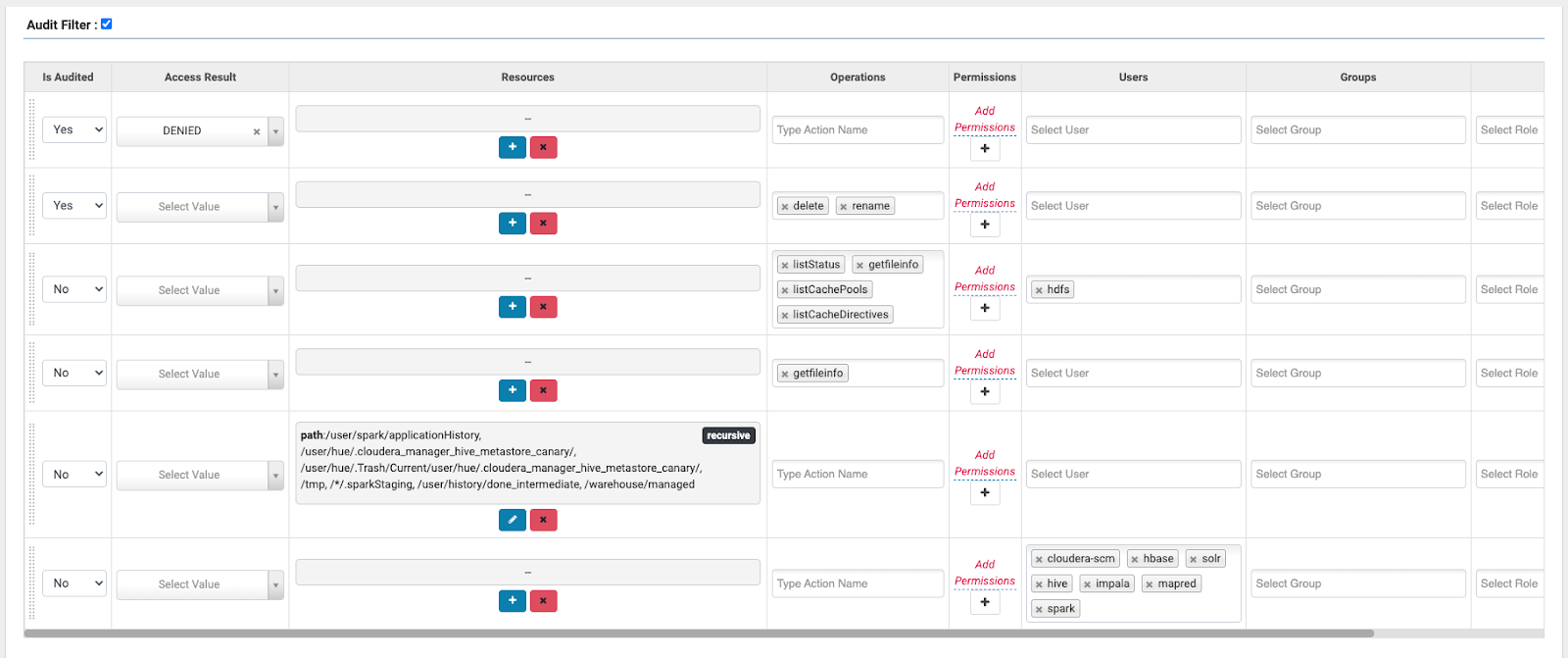
Figure 10: Example of a custom Audit Filter for HDFS activity
In this example we have created filters to ignore HDFS activities in certain known “managed” and/or staging locations and also to ignore HDFS activities from services such as Hive or Impala who are themselves configured to audit the actual SQL queries to Ranger themselves.
To summarize, CDP Private Cloud Base 7.1.7 delivers improved platform and analytic features that provide better security and encryption with SDX, faster SQL queries and ETL with Hive on Tez and Impala, improved Spark with support for Spark 3.1 and NVidia RAPIDS API, HBase performance improvements and an enterprise-grade scale out Object Store with Apache Ozone. With multiple paths to transition to CDP Private Cloud Base, making the shift has never been easier. To plan your migration, please refer to CDP Upgrade & Migration Paths for more information, or contact your Cloudera account team to discuss the best approach.
Additional resources:
- CDP Private Cloud Base 7.1.7 Release Summary
- What’s new in 7.1.7 Runtime
- What’s new in Cloudera Manager 7.4.4
- CDH 6 Upgrade Overview
- Journey advisor tool
- Knowledge Hub
Editor's Choice

