


Cloudera delivers an enterprise data cloud that enables companies to build end-to-end data pipelines for hybrid cloud, spanning edge devices to public or private cloud, with integrated security and governance underpinning it to protect customers data. Cloudera has found that customers have spent many years investing in their big data assets and want to continue to build on that investment by moving towards a more modern architecture that helps leverage the multiple form factors. Let’s take a look at one customer’s upgrade journey.
Background:
Customer A is a financial services firm running CDH 5.14.2. They have dev, test, and production clusters running critical workloads and want to upgrade their clusters to CDP Private Cloud Base. The customer had a few primary reasons for the upgrade:
- Utilize existing hardware resources and avoid the expensive resources, time and cost of adding new hardware for migrations.
- Modernize their architecture to ingest data in real-time using the new streaming features available in CDP Private Cloud Base in order to make the data available to their users quickly. In addition the customer wanted to use the new Hive capabilities shipped with CDP Private Cloud Base 7.1.2.
- The customer also wanted to utilize the new features in CDP PvC Base like Apache Ranger for dynamic policies, Apache Atlas for lineage, comprehensive Kafka streaming services and Hive 3 features that are not available in legacy CDH versions.
| New Features CDH to CDP
Identifying areas of interest for Customer A |
|
| Hive 3 |
|
| Security |
|
| Ranger 2.0 |
|
| Atlas 2.0 |
|
| Streaming | Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams
Cluster management and replication support for Kafka clusters Store and access schemas across clusters and rebalance clusters with Cruise Control |
The customer had shorter upgrade windows, which dictated the need to do an in-place upgrade by installing CDP on their existing environment, instead of a longer migration path that required data migrations, operation overhead to setup news clusters and time needed to procure and setup new hardware.
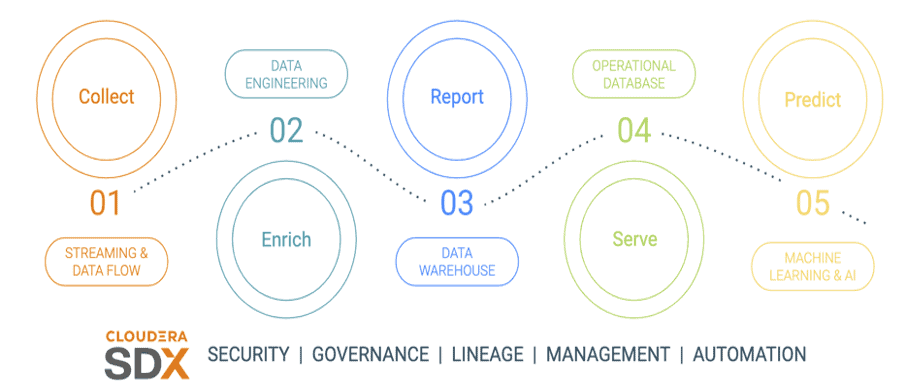
The customer leverages Cloudera’s multi-function analytics stack in CDP. The data lifecycle model ingests data using Kafka, enriches that data with Spark-based batch process, performs deep data analytics using Hive and Impala, and finally uses that data for data science using Cloudera Data Science Workbench to get deep insights.
This customer’s workloads leverage batch processing of data from 100+ backend database sources like Oracle, SQL Server, and traditional Mainframes using Precisely. Data Science and machine learning workloads using CDSW. The customer is a heavy user of Kafka for data ingestion. Cloudera CDP has the industry-leading Kafka offering providing customers a strong motivation to be adopters of the platform.
By upgrading to CDP Private Cloud Base, the customer is also prepared for the next stages in their CDP journey as they are now enabled to install CDP Private Cloud Experiences to take advantage of Hive LLAP based virtual data warehousing.
Customer Environment:
The customer has three environments: development, test, and production. In order to minimize risk and downtime, the upgrades were performed in that order and the learning from each upgrade was applied to the next upgraded environment. The total data size is over one petabyte (1PB).
| Services | Cluster Type | Data Size | CDP Version |
| Kafka, SRM, SMM | Test and QA | 7.1.2 | |
| Hive, Ranger, Atlas, Spark. Ranger KMS, KTS, CM and CDSW | Production | 1.5 PB (replicated) | 7.1.2 |
| Hive, Ranger, Atlas, Spark. Ranger KMS, KTS, CM and CDSW | Test and QA | 7.1.2 | |
| Kafka
|
Development | 100TB | 7.1.2 |
| Kafka | Production | 7.1.2 | |
| Hive, Ranger, Atlas, Spark. Ranger KMS, KTS, CM, and CDSW | Development | 7.1.2 | |
| Precisely ( Partner Product) |
Upgrade Team
The upgrade was driven by a task force that included the customer, Cloudera account team and Professional Services. The Cloudera team included a Professional Services Solution Architect and Service Delivery Manager. The customer team included several Hadoop administrators, a program manager, a database administrator and an enterprise architect. Additionally, individual application teams contributed to test and deploy their jobs. Some customers may also need to include platform/infrastructure, network and information security resources.
Upgrade planning, process, and implementation:
The customer engaged Cloudera Professional services to perform deep analysis and support of the upgrade. A major upgrade typically has several risks that Cloudera PS can help mitigate with an in-depth plan and testing including changes to functionality, incompatible data formats, deprecation of older components or database schema changes. Major upgrades of production environments can require hours to days of downtime, so it is critical that upgrades are efficient and planned to minimize risks.
The process started with creating base requirements and an in-depth plan for each upgrade and testing steps and procedures.
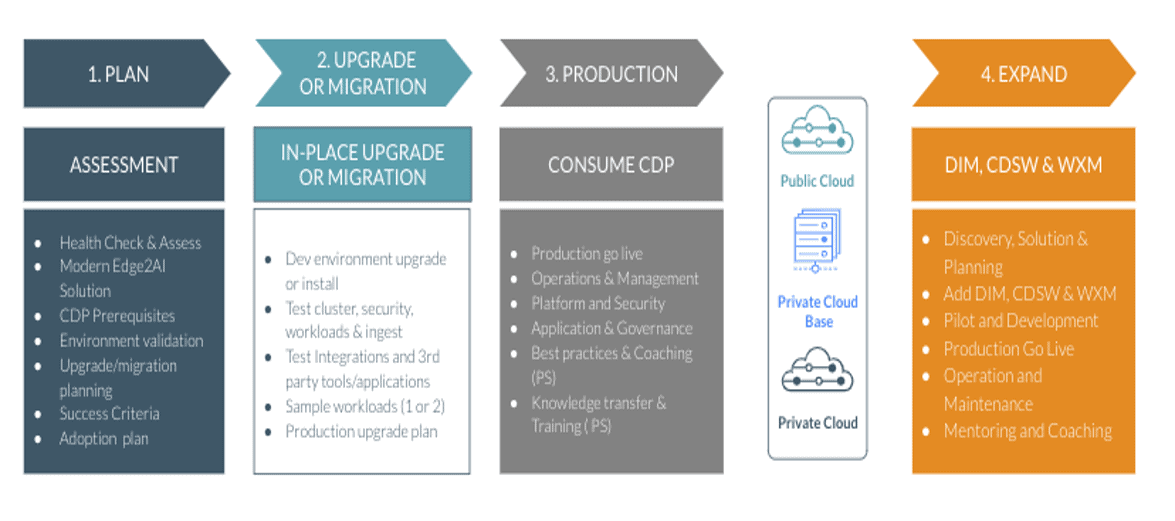
Phase 1: Planning
- Review component list and determine any work needed to migrate workloads of deprecated and removed components like Pig, Flume, Yarn Fair Scheduler, Sentry and Navigator.
- Review the Upgrade document topic for the supported upgrade paths.
- Review Upgrade Requirements – The following OS, databases, and JDK are supported in CDP Private Cloud Base edition.
- OS – RHEL/CentOS/OEL 7.6/7.7/7.8 or Ubuntu 18.04
- DB – Oracle 12.2.0.1, Postgres 10, MySQL 5.7 or Maria DB 10.2
- JDK – OpenJDK 8/Oracle JDK 8/OpenJDK 11
- Review the pre-upgrade transition steps
- Review Upgrade Requirements – The following OS, databases, and JDK are supported in CDP Private Cloud Base edition.
- Gather information on the current deployment. Document the number of dev/test/production clusters. Document the operating system versions, database versions, and JDK versions. Determine if the operations systems need upgrade, follow the documentation to backup and upgrade your operating systems to the supported versions. Review the JDK versions and determine if a JDK version change is needed and if so follow the documentation here to upgrade
- Plan how and when to begin your upgrade. Scan all the documentation and read all upgrade steps.
Phase 2: Pre-upgrade
- Backup existing cluster using the backup steps list here
- Confirm if all the prerequisites are addressed. Ensure all outstanding dependencies are met.
- Convert Spark 1.x jobs to Spark 2.4.5. Test and validate the jobs to ensure all the required code changes are performed and tested.
- Convert YARN from FairScheduler to CapacityScheduler, and configure queues for the new default scheduler. FairScheduler is deprecated and unsupported in CDP. A new tool ‘fs2cs’ CLI tool is provided to do basic queue structure migration (there are different behaviors between CS and FS, the fs2cs tool only converts part of configurations, see doc), upload to new CM. Post upgrade steps needed queue migration are reconfigure ACLs of queues, fine-tune scheduler queues using new Queue Manager UI.
- Setup and configure new databases for all dependent services like Ranger, Atlas and others.
Phase 3: Upgrade
- Upgrade Cloudera Manager to 7.1.2 using the steps documented here.
- Download, distribute, and activate Cloudera Runtime 7.1.x parcels using Cloudera Manager.
- Migrate or Upgrade all dependent services and components like Kafka, CDSW to the appropriate supported versions. Verify if all those
- Upgrade to the latest version of CDP DC 7.1.2. Perform the pre-transition steps for the components deployed in your clusters.
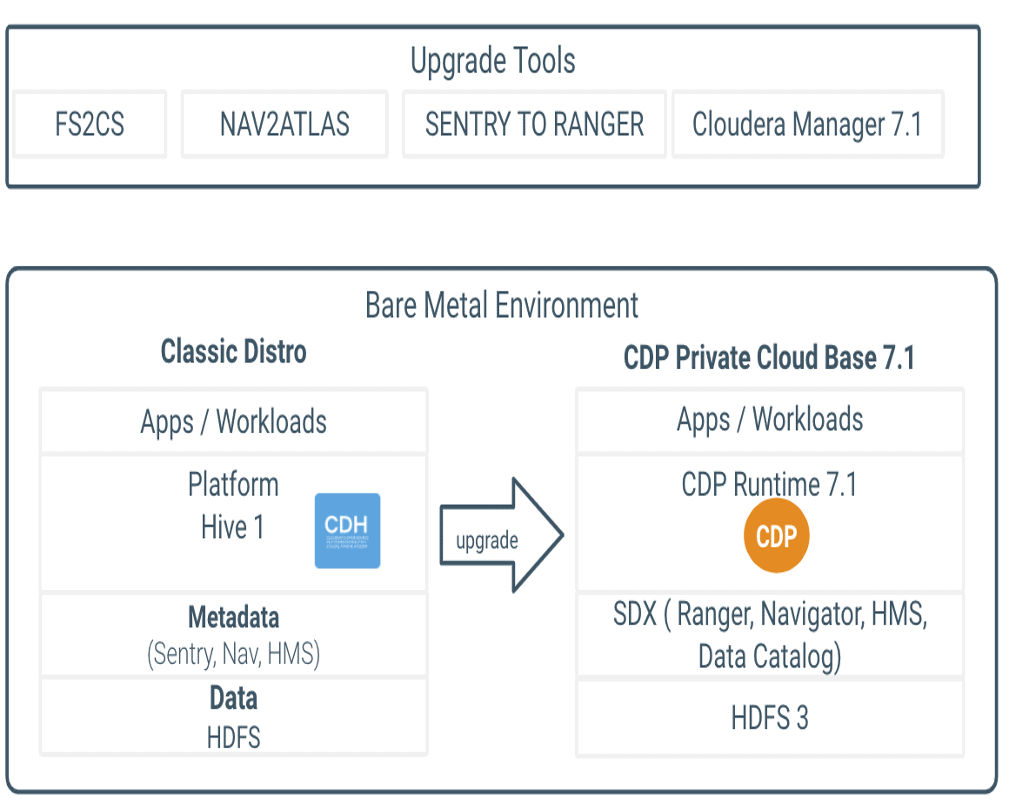
Note: fs2cs, nav2atlas and sentry to ranger are migration tools and procedures provided to transition from CDH5 legacy clusters to CDP PvC Base.
- Perform all encryption-related steps
- Transition YARN schedulers from FairScheduler to Capacity Scheduler by migrating the YARN settings from Fair Scheduler to Capacity Scheduler using the FS2CS conversion utility and then manually configuring scheduler configurations using the YARN Queue Manager UI to ensure that the resulting configurations suit the application scheduling requirements. Queue priorities needed to be reconfigured for optimal performance.
- Transition from Sentry to Ranger by exporting the policy rules from sentry and continuing with the upgrade steps to convert Sentry policies to Ranger policies. The transition converts the following sentry entities to ranger:
- sentry role -> ranger role
- sentry grant to parent object includes children -> ranger is finer-grained so translation crates policies enable for parent and child (parent db, child tables)
- sentry OWNER concept -> ranger ALL privilege
- sentry OWNER WITH GRANT OPTION -> ranger ALL with delegate admin and does not transition
- Sentry Hive / HDFS ACL sync is not included in CDP-DC 7.1 (on roadmap)
- Sentry style GRANT/DENY statements not recommended. Instead use Ranger REST API.
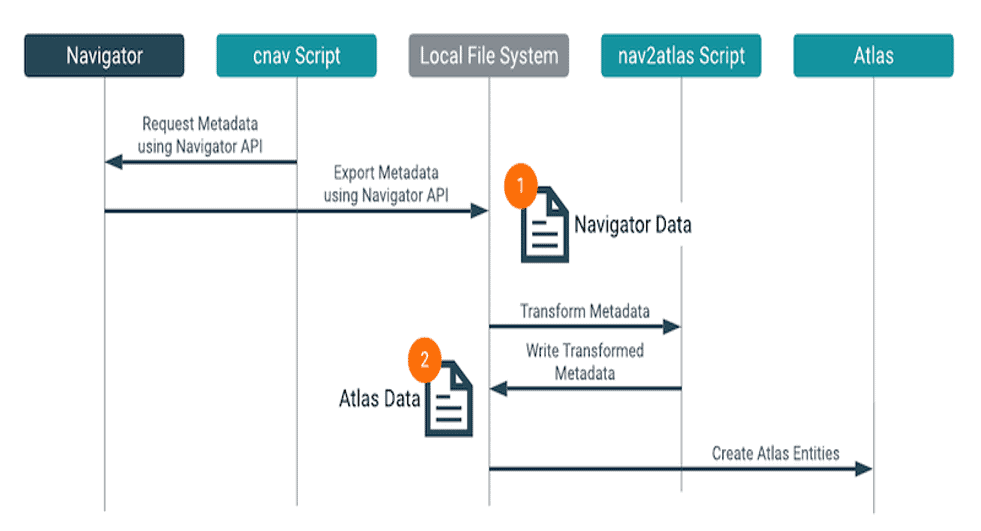
- Transition from Navigator by migrating the business metadata (tags, entity names, custom properties, descriptions and technical metadata (Hive, Spark, HDFS, Impala) to Atlas. The process looks like the following:
- Finalize the HDFS Upgrade and complete the upgrade.
Phase 4: Implementation
- Evaluate and perform the yarn placement rules to make sure the jobs can migrate easily
- Manually convert HDFS ACL policies to Ranger-based policies for all the DB/table paths. Ranger currently does not support HDFS ACL sync-up. This feature is in development and will be released soon.
- Monitor and tune YARN queue configurations with CapacityScheduler to match expected run-time behavior
Phase 5: Post-upgrade test and validation
- Test and validate Hive, Spark, YARN and Policy behavior.
- Test and validate 3rd party tools.
Challenges and Resolutions:
The following questions, challenges were encountered and resolved.
- Hive-on-Tez performance vs Hive-on-MapReduce.
- Customer A wanted to understand Hive on Tez vs Hive on Mapreduce. This has a great architectural insight into Hive on Tez.
- Ranger, Ranger KMS and Atlas
- Navigator to Atlas Migrations were slow due to complex lineage rules and configurations. Atlas ships with a default heap size of 2GB as specified in this Config changes to increase memory configurations resolved the issue.
- Issues while upgrading Ranger KMS in the importing policies step. Granting the “keyadmin” role to the rangerkms user in Ranger helped the Ranger KMS ACL Import step of the upgrade completed successfully.
- Atlas to Kafka connectivity issue. This issue was discovered in testing and was resolved after upgrading to 7.1.2 Atlas is able to connect to Kafka via SASL_SSL. CDP Private Cloud Base 7.1.2 has the fix.
Conclusion:
The upgrade from CDH 5.x to CDP Private Cloud Base can be a complex process, but the Cloudera team has a carefully documented process to mitigate the risk and enable a smooth upgrade. Customer A was able to successfully complete a migration and drive value from their production workload in 10 weeks. By leveraging Cloudera PS expertise, the customer was able to quickly identify any issues or risks and resolve them promptly in collaboration with Cloudera Support. As the applications teams were tested and new issues arose, Cloudera PS and the customer teams quickly engaged to debug, identify problem areas, and mitigate them with recommendations. These recommendations included either a configuration change or updates to customer practices based on Cloudera’s ongoing learning with other customers.
Customer A was able to upgrade successfully from CDH 5.14.2 to CDP Private Cloud Base with the guidance of the Cloudera PS team. This allowed them to enable a modern data architecture, enhance their streaming capabilities and prepare for the next phase of the CDP Journey.
Special thanks to Nicolas Moureau, Nishant Patel, Travis Campbell, Vineeth Varughese for their contributions.
If you’re ready to begin your upgrade to CDP Private Cloud, contact your account team and visit the CDP Upgrade advisor at my.cloudera.com to assess the readiness of your clusters.
References:
CDP Runtime release notes:
Install references:
Editor's Choice


In the diagram depicting the 01,02,03,04,05 steps, shouldnt the Operational database come before the Datawarehouse?
Or am i missing some point here?