

Data teams have the impossible task of delivering everything (data and workloads) everywhere (on premise and in all clouds) all at once (with little to no latency). They are being bombarded with literature about seemingly independent new trends like data mesh and data fabric while dealing with the reality of having to work with hybrid architectures. Each of these trends claim to be complete models for their data architectures to solve the “everything everywhere all at once” problem. Data teams are confused as to whether they should get on the bandwagon of just one of these trends or pick a combination. There also seems to be no coherent path from where they are now with their data architecture to the “ideal state” that will allow them to finally realize their dream of becoming a “data-driven organization.”
In this article, we attempt to show how these concepts may be related to each other, and even suggest thinking about all of them all at once (gasp!).
First, we describe how data mesh and data fabric could be related. Then, we add hybrid architectures to the mix since they are here to stay and will not just be a “temporary state until we all move to the cloud.”
Data mesh defined
Data Mesh is a concept used to help scale a company’s data footprint in a manageable way. It is a set of rubrics around people, process, and technology choices that allow for companies to scale their data systems.
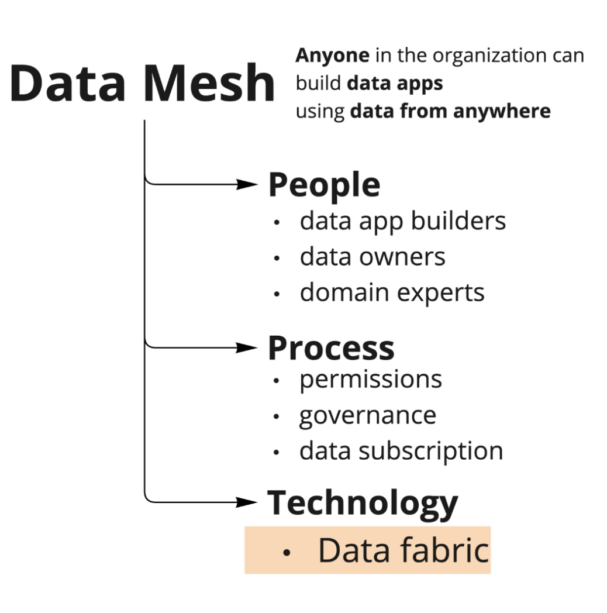
Figure 1. Data mesh conceptual hierarchy
Instead of having a central team that manages all the data for a company, the thinking is that the responsibility of generating, curating, documenting, updating, and managing data should be distributed across the company based on whichever team is best suited to produce and own that data. Each team in a company is a domain expert in the domain of the data that is produced by the product or business function that is owned by the team. This team or domain expert will be responsible for the data produced by the team. The data itself is then treated as a product. The data product is not just the data itself, but a bunch of metadata that surrounds it—the simple stuff like schema is a given. But more dynamic information like freshness, statistics, access controls, owners, documentation, best uses of the data, and lineage also need to be considered to be part of the data product and interface of the data.
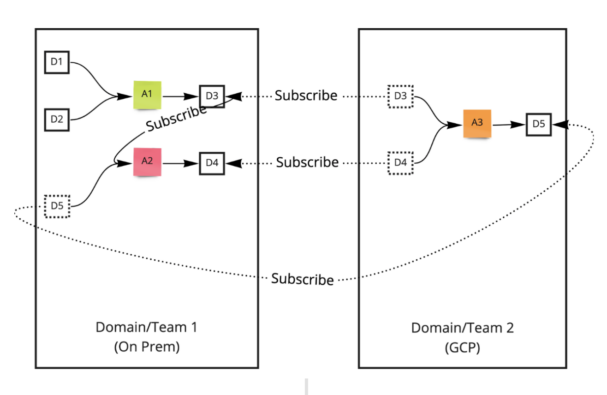
Figure 2. Data mesh example
In the picture above showing a data mesh example, there are data apps, data products, and data subscriptions.
- A1, A2 are data apps
- D1, D2, etc., are data products
- Apps subscribe to data products and produce data products
Note that the actual technologies used to generate, store, and query the actual data may be varied—and are not even prescribed by data mesh. It is also agnostic to where the different domains are hosted. Some domains can be on premises, while other domains could be in the cloud.
Data fabric defined
One way to implement a data mesh is to make technology choices within the framework of data fabric. Data fabric is a collection of technologies used to ingest, store, process, and govern data anywhere (on prem or in the cloud) at any time. Data mesh is about people, process, and technology. Data fabric can be deemed as the technology part of data mesh. Concepts in data mesh map to real-world artifacts in the data fabric implementation.
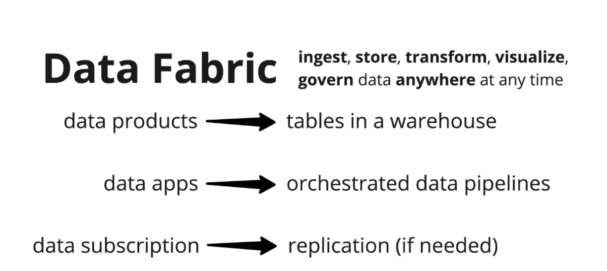
Figure 3. Data mesh concepts mapping to data fabric entities
The corresponding data fabric example to the data mesh implementation in Figure 2 is shown in Figure 4.
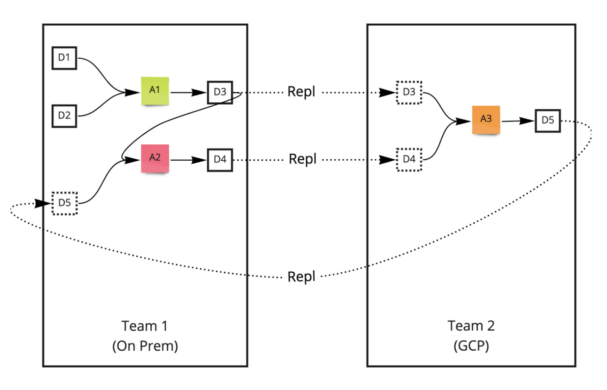
Figure 4. Data fabric implementation corresponding to data mesh example in Figure 2
In the data fabric implementation, the concepts in data mesh map to real-world artifacts in a data architecture. Corresponding to the data mesh example in Figure 4,
- D1, D2 are tables in a data warehouse
- A1 is an app with ingestion and an SQL statement pipeline orchestrated to run on a certain schedule
- A2 is an app built as a spark job orchestrated to run when some data shows up
Subscriptions can be implemented as replication in the opposite direction only if the subscription is across form factors or regions. Transparent replication is a key capability in the data fabric that allows for data to be made available in the location where it is going to be used. An underlying replication engine can replicate changes to the tables at the source (as it is produced and updated) to all the consumers (who have subscribed to the data).
Hybrid data architectures defined
The “modern data” thinking is that companies that either weren’t born in the cloud or haven’t been able to move completely to the cloud are the ones that are touting hybrid architectures. But even if the ultimate destination of all compute and storage resources is the cloud, there is going to be a non-trivial period of transition. Companies will have to take their time migrating their data and workloads to the cloud. And during this time they will by definition have a hybrid architecture. So the industry ask is clear: hybrid data architectures have to be made viable—and they’re here to stay (for the foreseeable future).
For example, the sales team might be producing sales data in a teradata warehouse in an on-prem data center in Utah. The R&D team would then want to get the sales data to join with other data sets they might have in their Snowflake data warehouse in Azure’s us-west-2 region. A hybrid architecture should allow for the R&D team to subscribe to the sales data and have the data be automatically replicated whenever the source data changes.
Hybrid architectures are technology choices made to ingest, store, process, govern, and visualize data in different form factors—-on premises as well as in multiple clouds, potentially replicating data as needed. Hybrid architecture can thus be deemed to be an implementation of a data fabric that spans multiple form factors.
A hybrid architecture can allow data producers to produce data and tables in an on-prem data warehouse in a data center and data consumers in the cloud to subscribe to those tables. The same can happen for a data set produced in the cloud and consumed in an on-prem data center.
Cloudera has been working on the hybrid data architecture for a while. You can read more about it at https://blog.cloudera.com/the-future-is-hybrid-data-embrace-it/. Reach out to us at innovation-feedback@cloudera.com about how we can help you leverage the latest data trends in your data architecture journey to become a data driven organization.
Resources
What is a data mesh contract?
We believe that the metadata—-both static and dynamic—-has to be consistent across all data products, i.e., that the data model of the metadata has to be consistent irrespective of the underlying technologies used. This data model is also the structure of the contract that is defined between the producers and consumers of the data. Consumers subscribe to data products that are produced by the data producers.
What are the different definitions of hybrid architectures?
There are many definitions of the hybrid data architecture. There are stringent definitions of hybrid around having the ability to automatically and seamlessly migrate data workloads between different locations, like from on premise deployments to any cloud, or from one cloud to another. But it is not clear that that definition is truly what is needed in the market. There is definitely a need for more customer development, but it is more likely that companies want a potentially simpler definition where hybrid allows companies to not be constrained by the specific technologies or locations where data is produced and consumed.
What else has been out there that resembles a data mesh?
There is some overlap in ideas between the data mesh and the data exchanges being built out currently—-like Snowflake data exchange, Amazon data exchange, and so on. These exchanges are purely treated as producer/consumer marketplaces and don’t typically have a query capability associated with them. It is not yet clear how this will play out in the future.
Data mesh is also related to data virtualization in the sense that with data virtualization, one can query data produced by others seamlessly within their own query engines. Starburst with Trino are doing this nowadays. Denodo is one of the more established players in data virtualization. Amazon Redshift with Spectrum and Athena, with the ability to query from RDS, are other examples.
Back in 2011, Facebook ran into a problem with building clusters big enough to hold all data. The project to solve this problem not only solved the scale problem, but also provided a blueprint for a producer/consumer model for data. Teams would own a “namespace/database” (domain) and all the data within that namespace. The teams would then “publish” specific tables within their namespaces as publicly referenceable. Other teams could then subscribe to these tables and would get a near–real time replicated table that is queryable along with their own tables. Hive table links (EP2767913A1) was one of the outcomes of that project.
Where can I read more about data mesh and data fabric?
There are tons of blogs/videos etc about data mesh. But you can start with these:
Editor's Choice

