


Cloudera DataFlow for the Public Cloud (CDF-PC) is a cloud-native service for Apache NiFi within the Cloudera Data Platform (CDP). CDF-PC enables organizations to take control of their data flows and eliminate ingestion silos by allowing developers to connect to any data source anywhere with any structure, process it, and deliver to any destination using a low-code authoring experience.
The GA of DataFlow Functions (DFF) marks the next significant stage in the evolution of CDF-PC. With DFF, users now have the choice of deploying NiFi flows not only as long-running auto scaling Kubernetes clusters but also as functions on cloud providers’ serverless compute services including AWS Lambda, Azure Functions, and Google Cloud Functions.
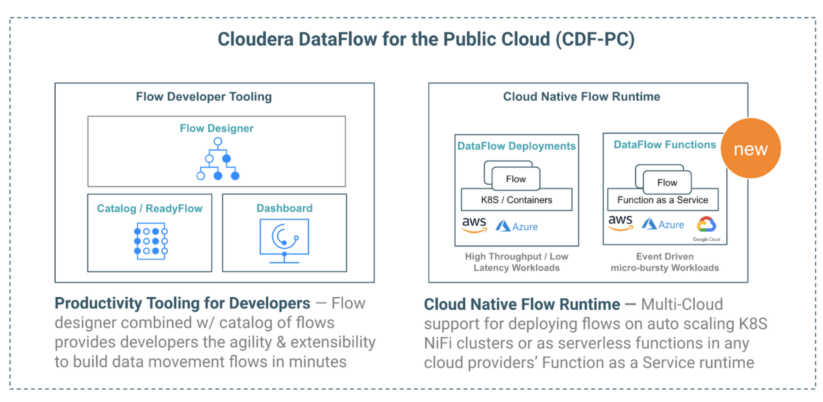
With the addition of DFF, CDF-PC expands the addressable set of use cases, enables developers to focus more on business logic and less on operational management, and establishes a true pay-for-value model.
New use cases: event-driven, batch, and microservices
Since its initial release in 2021, CDF-PC has been helping customers solve their data distribution use cases that need high throughput and low latency requiring always-running clusters. CDF-PC’s DataFlow Deployments provide a cloud-native runtime to run your Apache NiFi flows through auto-scaling Kubernetes clusters as well as centralized monitoring and alerting and improved SDLC for developers. The DataFlow Deployments model is an ideal fit for use cases with streaming data sources where those streams need to be delivered to destinations with low latency, like collecting and distributing streaming POS data in real time.
However, customers also have a class of use cases that do not require always running NiFi flows. These use cases range from event-driven object store processing, microservices that power serverless web applications, to IoT data processing, asynchronous API gateway request processing, batch file processing, and job automation with cron/timer scheduling. For these use cases, the NiFi flows need to be treated like jobs with a distinct start and end. The start is based on a trigger event like a file landing in object store, the start of a cron event, or a gateway endpoint being invoked. Once the job completes, the associated compute resources need to shut down.
With DFF, this class of use cases can now be addressed by deploying NiFi flows as short-lived, job-like functions using the serverless compute services of AWS, Azure, and Google Cloud. A few example use cases for DFF are the following:
- Serverless data processing pipelines: Develop and run your data processing pipelines when files are created or updated in any of the cloud object stores (e.g: when a photo is uploaded to object storage, a data flow is triggered that runs image resizing code and delivers a resized image to different locations to be consumed by web, mobile, and tablets).
- Serverless workflows/orchestration: Chain different low-code functions to build complex workflows (e.g: automate the handling of support tickets in a call center).
- Serverless scheduled tasks: Develop and run scheduled tasks without any code on pre-defined timed intervals (e.g: offload an external database running on premises into the cloud once a day every morning at 4:00 a.m.).
- Serverless IOT event processing: Collect, process, and move data from IOT devices with serverless IOT processing endpoints (e.g: telemetry data from oil rig sensors that need to be filtered, enriched, and routed to different services are batched every few hours and sent to a cloud storage staging area).
- Serverless microservices: Build and deploy serverless independent modules that power your applications microservices architecture (e.g: event-driven functions for easy communication between thousands of decoupled services that power a ride-sharing application).
- Serverless web APIs: Easily build endpoints for your web applications with HTTP APIs without any code using DFF and any of the cloud providers’ function triggers (e.g: build high performant, scalable web applications across multiple data centers).
- Serverless customized triggers: With the DFF State feature, build flows to create customized triggers allowing access to on-premises or external services (e.g: near real-time offloading of files from a remote SFTP server).
Improved developer agility
In addition to addressing a whole new class of data distribution use cases, DFF is an important next step in our mission to enable users to focus more on their application business logic.
When the DataFlow Deployments model was introduced last year in CDF-PC, users could focus less on operational activities of running Apache NiFi in the cloud, including managing resource contention, autoscaling, and monitoring, as well as the hardening, security, and upgrades of infrastructure, OS, Kubernetes, and Apache NiFi itself.
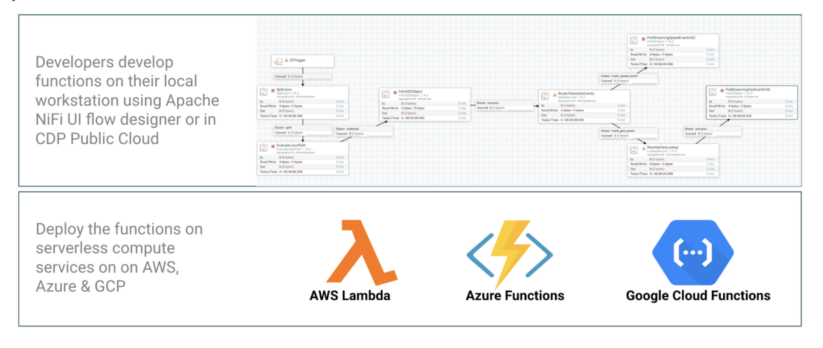
While DataFlow Deployments resulted in fewer operational management activities, DFF further improves this by completely removing the need for users to worry about infrastructure, servers, runtimes, etc., which affords developers more time to focus on business logic. However, implementing this business logic requires long development and testing cycles using custom code with Java, Python, Go, and more. With DFF, developers can use Apache NiFi’s UI flow designer to simplify function development, resulting in faster development cycles and time to market.
As a result, DFF provides the first low-code UI in the industry to build functions with an agility that developers have never had before and an extensible framework that allows developers to plug in their own custom code and scripts.
A true pay-for-value model with lower TCO
DataFlow Deployments offers smart auto scaling Kubernetes clusters for Apache NiFi and a consumption pricing model based on compute (Cloudera Compute Unit). This provides an improved pay-for-value model because customers only pay Cloudera when the flow is running. However, customers would still have to pay the cloud provider for the always-running resources required by the Kubernetes cluster.
With DFF, a true pay-for-value model can be established because customers only pay when their function is executed. The serverless compute paradigm means that you only pay the cloud provider and Cloudera when your application logic is running (compute time, invocations). Hence, DFF offers a lower TCO for event-driven, microservice, and batch use cases that don’t require constantly running clusters but rather have a clearly defined start and end.
Let’s use a sample use case from one of our customers to demonstrate the TCO improvements with DFF. A financial services company subscribes to daily feeds of Bloomberg data to do various analyses. Since Bloomberg charges customers more to access historical data, the company archives data themselves to save costs. With CDF-PC, they built a data flow that collects the daily feeds that arrive in a cloud object store, processes them, and delivers them to multiple downstream systems. For one type of market data, approximately 30,000 market feed files will land in the cloud object store throughout the day with each file taking about 10 seconds to process by the NiFi flow. TCO is defined by how much the customer has to pay the cloud provider for the infrastructure services to run the NiFi flow (VMs, Kubernetes Service, RDS, networking, etc.) and to Cloudera to use the CDF-PC cloud service. The below chart compares the TCO between DataFlow Deployments and DataFlow Functions for this use case.
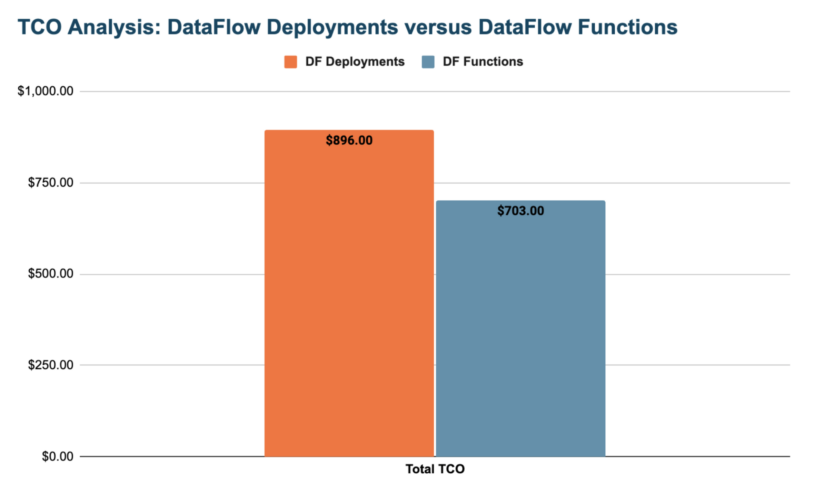
DF Functions provides an approximately 21% cost optimization, with the majority of the savings achieved with lower costs for cloud infrastructure services by moving from always-running resources required by Kubernetes to functions running on the cloud provider’s serverless compute service triggered only when daily feeds land in the cloud object store. The TCO doesn’t account for the fact that the serverless model with DF Functions would decrease the operational management costs, further increasing the cost optimization. For other Bloomberg market feeds, where high throughput and low latency are required, the TCO advantage shifts to DataFlow Deployments, as this deployment model is more conducive for those types of use cases. For more details on identifying the right runtime based on your use case, see the following: DataFlow Deployments versus DataFlow Functions.
In summary, DataFlow Functions is a new capability of Cloudera DataFlow for the Public Cloud that allows developers to create, version, and deploy NiFi flows as serverless functions on AWS, Azure, and GCP.
For developers who build functions on AWS Lambda, Azure, or GCP Functions, DFF provides the first no-code function UI in the industry to quickly create and deploy functions using the 450+ NiFi ecosystem components.
For existing NiFi users, Cloudera DataFlow Functions provides an option to run serverless short-lived NiFi dataflows with no infrastructure management, improved cost optimization, and unlimited scaling.
What to learn more?
To learn more, watch the Technical Demo of DataFlow Functions that showcases how to develop a data movement flow using Apache NiFi and run it as a function using the serverless compute services of different cloud providers.
Next, checkout the DataFlow Functions Product Tour on the Cloudera DataFlow Home Page.
Finally, try it out yourself using the DataFlow Functions quickstart guide that walks you through from provisioning a tenant on CDP Public Cloud using the 60-day CDP Public Cloud trial using your company email address to deploying your first serverless NiFi flow on AWS Lambda.
Editor's Choice

