

Recently, Cloudera Fast Forward held a webinar on automated question answering. What is automated question answering, you ask? In its simplest form, it’s a human-machine interaction to extract information from data using human language. This is a pretty broad definition that encapsulates the idea that machines don’t inherently understand human language any more than humans understand machine language.
Computer systems are extremely efficient at storing and processing massive amounts of data, but the quest for knowledge — and insights — is uniquely human. Gleaning that knowledge is no easy feat, so a well-developed question answering system should serve to bridge that gap, allowing humans to extract information from electronic systems in a manner that is natural to us, be it spoken language or written text.
In fact, you’re probably already familiar with various forms of question answering systems, many of which are becoming increasingly commonplace — such as voice assistants, chatbots, and augmented analytics platforms.
Whether it’s simply interacting with Siri or OKGoogle on our phones, or talking to Alexa on our countertops, we have come to rely on the convenience of being able to casually check the weather before heading out for the day. We can see another example of a question answering system in the form of chatbots, which have become ubiquitous for digitally transformed businesses as a way to streamline and improve customer service operations with more natural language interactions (though the jury is still out on whether these chatbots facilitate or frustrate the user experience). A third example that is becoming increasingly popular can be seen in augmented analytics tools that are enabling non-technical workers to become “information workers” thanks to the ease of access to data insights through plain natural language queries, rather than highly specialized database languages. These types of capabilities are predicted to increase dramatically in the next three to five years as natural language capabilities march towards maturity.
While each of these general systems have various implementation methods, in our webinar we focus on a specific type of question answering system: information retrieval-based question answering. This type of QA system leverages modern search techniques to identify a relevant set of plain text documents for a given question and then relies on sophisticated reading comprehension algorithms to parse those documents and identify answers. This type of system extracts an answer as a snippet of existing text from a document, allowing users to quickly and intuitively locate information in mountains of unstructured text data.
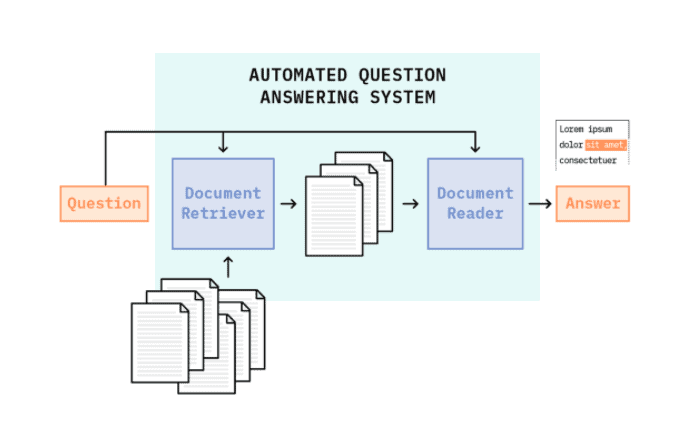
These systems typically require two main components: a Document Retriever and a Document Reader. The retriever functions as a standard search engine. Using the input question, it narrows a large collection of documents to a small set of candidate documents that might contain the answer to the question. These candidate documents are fed into the reader — the reading comprehension algorithm that processes the text in the candidate documents and extracts an explicit span of text that best satisfies the question. This modular, two-stage approach allows each component to play to its strengths — trading off fast, efficient search from the retriever with slower, precision from the reader — providing a more performant overall system in terms of both speed and accuracy.
How can this type of system help your business? The general and modular approach of these systems lend them to myriad applications but perhaps the best among them is as an enhanced search system — instead of a simple keyword search over your company’s documents or internal webpages, IR-QA systems can provide more meaningful, insightful and tangible information in the form of short, direct answers to specific questions, rather than a set of links, which the user must then read and parse. This streamlines the synthesis process, allowing users faster access to mountains of information.
This technology stack is designed to work atop any large collection of documents — from financial statements, legal documents, company policies, to design or process documentation. It can even be used to enhance customer-facing material such as Frequently Asked Questions or, in some cases, to provide some support to existing chatbot infrastructure — though these use cases should be highly focused rather than general knowledge.
Once implemented, these systems can deal with general fact-seeking questions, providing answers that explicitly live within the text itself. For example, a QA system over a collection of financial statements could handle questions like, “What was Company Y’s revenue in Q4 2019?”, while a system over a collection of company policies could field questions like, “When are the blackout dates for company stock sales?” or “What building is Human Resources located in?”
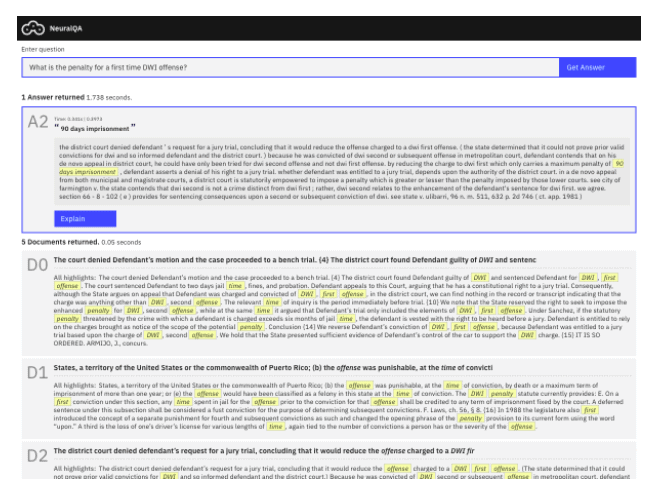
To highlight the enhanced search use case, we built a prototype that you can explore right now! NeuralQA is an interactive tool for question answering and allows the user two forms of QA. In the first, you can explore reading comprehension algorithms by asking questions over a passage that you supply yourself (copy+paste plain text into the provided box). In the second, you can experience a full IR QA system in which we’ve built a search engine over a large collection of documents to which you can pose questions. We’ve included a collection of case law documents from the CaseLaw Access Project. These documents are the Judge’s opinions for various cases heard by the New Mexico Supreme Court.
To learn more about how these systems work and the deep learning and natural language processing that makes reading comprehension and question answering possible, check out the most recent webinar: Deep Learning for Automated Question Answering.
Editor's Choice

