




The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever. At Cloudera, we introduced Cloudera Data Engineering (CDE) as part of our Enterprise Data Cloud product — Cloudera Data Platform (CDP) — to meet these challenges.
Normally on-premises, one of the key challenges was how to allocate resources within a finite set of resources (i.e., fixed sized clusters). In the cloud, with infinite potential capacity, the problem is more about creating efficiencies and managing costs while also meeting critical SLAs. That’s why turning to traditional resource scheduling is not sufficient. When building CDE, we integrated with Apache YuniKorn which offers rich scheduling capabilities on Kubernetes.
Traditional scheduling solutions used in big data tools come with several drawbacks. Most resource schedulers lack the ability to have fine-grained control for autoscaling, which leads to out of sync resource utilization, longer autoscaling times (for both upscaling and downscaling) and because of these, higher cloud costs, and lower throughput/performance.
YuniKorn’s Gang scheduling and bin-packing help boost autoscaling performance and improve resource utilization. We ran periodic Spark jobs concurrently and observed almost 2x the throughput (number of jobs within a set amount of time), reduced average job runtime by 2x , while reducing scale up and scale down latencies by 3x for 200 nodes.
Setup
We tested the scaling capabilities of CDE with the following job runs to mimic a real-world scenario:
- ETL/analytics jobs arriving in waves and run periodically:
- A simple SparkPi job triggered every minute to have something that’s constantly running on the system;
- 3 jobs that are wrapped TPC-DS queries triggered every 5 minutes in parallel for stable load; and
- 8 jobs that are also wrapped TPC-DS queries triggered every 15 minutes in parallel for load spikes.
We chose 5 random TPC-DS queries for these CDE jobs: query number 26, 36, 40, 46 and 48. The tests ran for 3 hours on a 1 TB TPC-DS dataset queried from Hive.
The AWS CDE Cluster that ran these tests was configured with 15 r5d.4xlarge nodes in an autoscaling group with the minimum number of nodes set to 1.
To demonstrate the periodic nature of our scenario, here are the executor CPU time and peak memory graphs we collected during the test, where different colors on the bars represent separate queries:
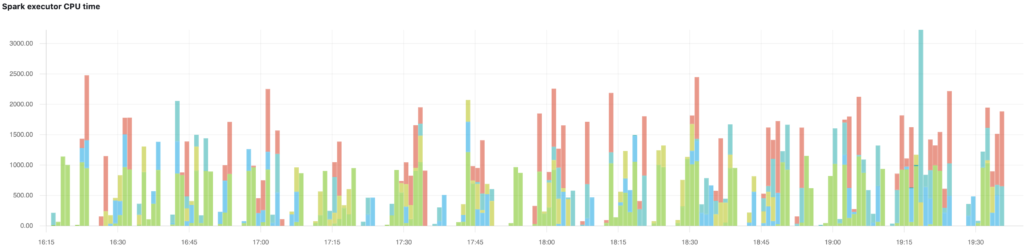
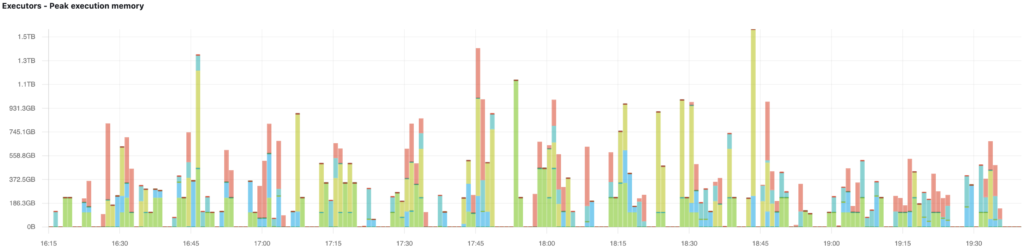
Test results without Gang Scheduling / Bin-Packing
As testing concluded, we immediately noticed how the number of nodes was out of sync compared to the periodic load that was generated on the cluster. The traditional scaling pattern can be observed on the graph below. The system is slow to respond to the increased load as well as to the potential opportunities to scale down the cluster when jobs are finished.
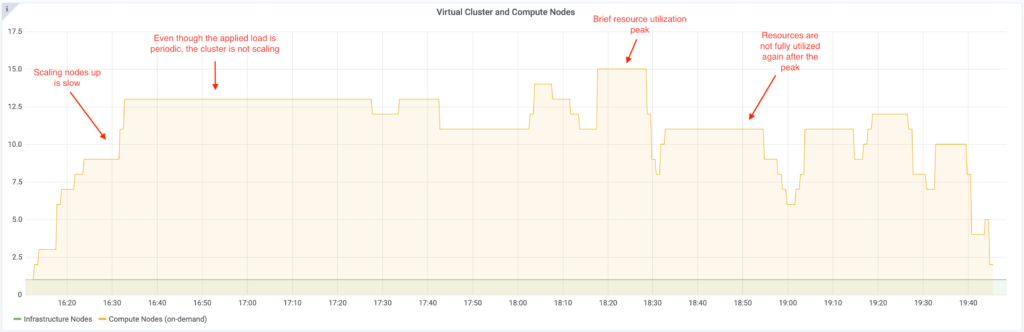
With these results we identified that there was significant room for improvement.
Why Gang scheduling and bin-packing?
Gang scheduling is a scheduling mechanism that ensures all or nothing allocation for a distributed job. Gang scheduling makes sure the job gets its minimal number of allocations so the job can process its compute logic.
Gang scheduling has many added benefits to our workflows. Currently, we are using enhanced FIFO scheduling to avoid the race condition that prevents us from starting only driver pods if there are a lot of concurrent jobs. With Gang scheduling, this is further improved to only allow a fittable number of jobs in the queue without competing resources, which leads to better performance.
Additionally, Spark dynamic allocation supports defining a spark.dynamicAllocation.minExecutors parameter that declares a lower bound of the number of executors. Ideally, the scheduler should ensure the job at least has this many executors before starting them. When there are many Spark jobs submitted with dynamic allocation enabled, it is important for the scheduler to enforce this by rejecting/queuing some jobs that would overload the cluster.(1)
Enabling Gang scheduling in a CDE cluster practically means the system can utilize upfront scale ups to more closely follow load on the cluster. This gives us a performance boost when we need more resources to handle load spikes.
In order to better support node scale down, YuniKorn’s bin-packing node sorting policy sorts the list of nodes by the amount of available resources so that the node with the lowest amount of available resource is the first in the list. In a nutshell, the bin-packing policy can help nodes scaling down because the scheduler tries to “pack” the pods into fewer nodes.
This results in a node with the highest utilisation to be considered first for assigning new allocation. Resulting in a high(er) utilisation of a small(er) number of nodes, better suited for cloud deployments.(2)
Test results with Gang scheduling and bin-packing node sorting policy
We reran the same test scenario as we did with the default configuration, and as expected, the nodes followed the load much closer and we experienced tremendous improvements in how node scaling follows the overall load applied to the cluster.
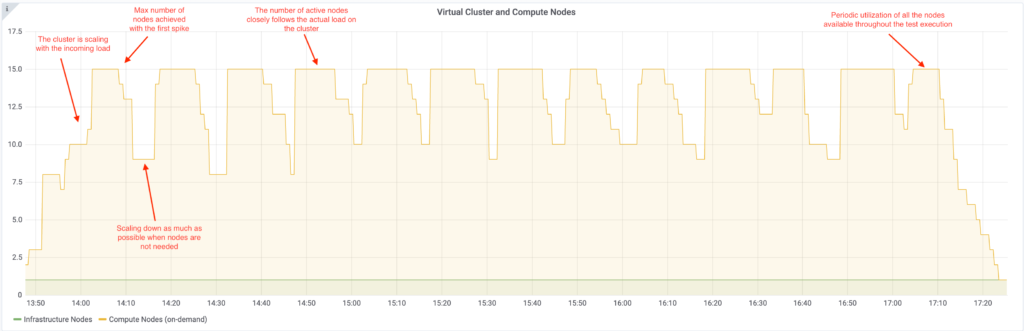
How Gang Scheduling and bin-packing improve job performance
After seeing how Gang scheduling and YuniKorn’s bin-packing policy improved the scaling characteristics of our cluster, we also wanted to see how this translates to actual computing performance.
To achieve this, a new virtual cluster with 200 r5d.4xlarge nodes was used. To measure the throughput, the number of jobs run in parallel was fixed to 15 for a 1 hour duration. The jobs were TPC-DS queries similarly to the previous scenario.
Summary of Workload Performance Results
There were a few key takeaways from the increased node count and fixed load that relate to scaling and overall performance.
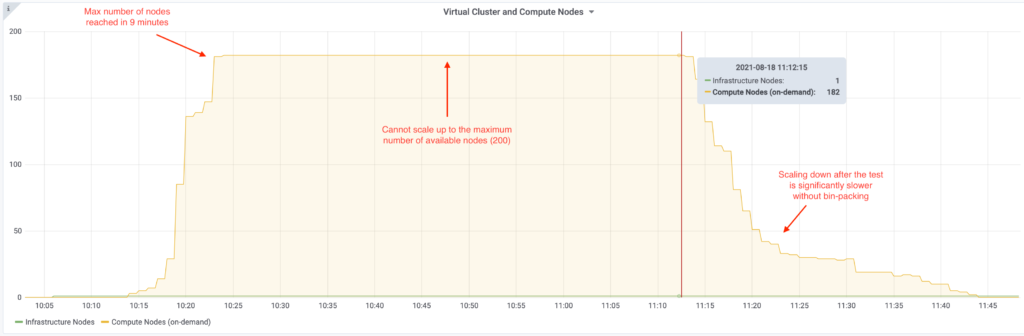
Here is what the run with the default YuniKorn configuration looked like:
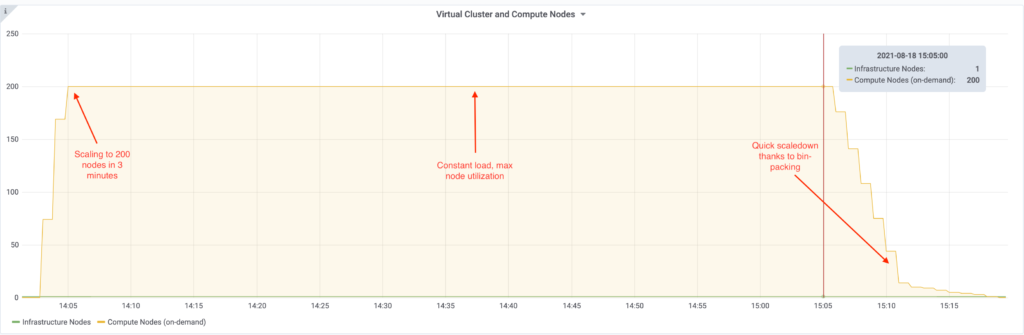
And here is the graph for YuniKorn with Gang scheduling and bin-packing:
The key aspects are labeled on the graphs, but their importance is only really revealed when given context about the differences:
| YuniKorn w/ default settings | Yunikorn w/ Gang scheduling and bin-packing | Improvement | |
| Max number of nodes | 182 | 200 | 10% more nodes |
| Scaling from 0 to Max nodes | 9 minutes | 3 minutes | 3x faster |
| Scaling from Max to 0 nodes | 30 minutes | 10 minutes | 3x faster |
| Number of queries completed | 168 | 285 | 1.7x throughput |
| Average query runtime | 358.60 seconds | 183.71 seconds | 2x faster |
Looking at the results, it’s apparent that Gang scheduling and bin-packing bring some serious improvements to the table when it comes to scaling and cluster performance. The less time that is spent on waiting for resources to become available, the more one can utilize a cluster to do meaningful work. Similarly, after finishing a job, having significantly faster scale down means unused resources do not consume money unnecessarily.
What’s next
As our testing revealed, the combined approach of using Gang scheduling and bin-packing configurations provided a more agile scaling setup for virtual clusters running dynamic Spark workloads at scale in the cloud.
Starting with our August release, CDE will provide this configuration as the default for our customers to enable vast improvements in scalability, and with it, performance and cost.
In future blogs we will explore larger scale tests to profile the performance and efficiency benefits at 500+ nodes.
Sources
(1) Gang Scheduling | Apache YuniKorn (Incubating)
(2) Sorting Policies | Apache YuniKorn (Incubating)
Editor's Choice

