



This blog post is part of a series on Cloudera’s Operational Database (OpDB) in CDP. Each post goes into more details about new features and capabilities. Start from the beginning of the series with, Operational Database in CDP.
This blog post gives you an overview of the high availability configuration capabilities of Cloudera’s OpDB.
Cloudera’s Operational Database (OpDB) is a cluster-based software, which comes configured for High Availability (HA) out of the box.
That results in seamless and automated failover between nodes, and it makes the configuration path also resilient to failover, meaning that it can be brought back without shutting down the OpDB.
HA can be further extended with the following features:
- Asynchronous replication: locally, across data centers, between data center and cloud, and in a geo-distributed manner.
- Stretch cluster configuration: comes with network latency (recommended that link latency is < 20 ms). Distances can vary depending on network load latency and bandwidth.
- Read replicas: they provide additional resilience within the database.
Online reorganization and configuration changes
Cloudera’s OpDB allows database reorganization without shutting down the OpDB. That is because Namespaces are roughly equivalent to DB and they can be assigned to different sets of servers in the cluster without shutting down the cluster.
Namespaces can be moved between nodes in a cluster or restricted to a subset of nodes through region server groups regardless of the physical location of the nodes within the cluster or if the cluster spans datacenters in a stretch cluster configuration.
Index reorganization is also supported. Most indexes, such as the near-real-time indexes, can be created, modified or dropped in a live system. Other indexes can be created or dropped online, but not modified.
It is also possible to change the configuration without stopping the OpDB. Nodes, tables, and columns can be added and deleted in a live system, and SQL engines and supplementary components can also be added without downtime.
Configuration changes for multiple instances on the same DB also supported without shutting down. For example, it is possible to add a new column in the Column Family and also change the application to use that new column.
Upgrade
Cloudera Manager automates the process of upgrading the various components in the OpDB through releases and maintenance patches.
Cloudera Manager handles the following processes in an automated manner:
- Installing the release or maintenance patch
- Managing the configuration
- Rebooting process for each of the impacted components
Cloudera’s OpDB offering is a cluster-based offering, therefore upgrades and patches all span multiple nodes.
Application upgrade without downtime is also supported. Neither storage engine has to be turned off while user applications are being upgraded.
Replication
All Data Replication (DR) combinations are supported:
- hot-hot
- hot -warm
- hot-cold
- hot-warm-cold
- other permutations of these configurations
The direction of replication can be uni-directional, bi-directional or multi-directional replication through advanced geo-distributed topologies.
The database maintains a minimum of three copies (more can be configured) of the data within the cluster to prevent an outage in a hot DR environment. However, if such a thing is desired, multiple mechanisms are provided to allow copies of the data to be created in a hot environment:
- Snapshots
- Replication
- Export
- CopyTable
- HTable API
An Active-hot DR site can be used for all forms of access including read-only, read-write, write-only, etc. Multi-directional replication can be used to keep the data in sync and can be setup at the database (namespace) level as well as at the table level.
Warm and cold DR sites are also supported in the same manner as Active-hot DR sites. All sites are licensed in the same manner without consideration for the type of site.
Asynchronous replication
Cloudera’s OpDB platform supports near-real time asynchronous replication of data between instances of the same OpDB with minimum effect on performance.
Asynchronous replication has two consistency modes: eventually consistent and timeline consistent
There are multiple ways to achieve asynchronous replication.
Storage layer-based approach
A storage layer-based approach to achieve asynchronous replication is to asynchronously replicate the data between multiple clusters.
Cluster replication uses an active-push methodology. A cluster can be a source cluster (also called active, meaning that it writes new data), a destination cluster (also called passive, meaning that it receives data using replication), or can fulfill both roles at once.
This asynchronous cluster replication refers to keeping one cluster state synchronized with that of another cluster, using the write-ahead-log (WAL) of the source cluster to propagate the changes.
Replication is enabled at column family granularity. Column families are column groupings that are defined at table creation in contrast to columns that do not have to be defined at table creation as they can be created dynamically at the time of insertion.
When data is replicated from one cluster to another, the original source of the data is tracked with a cluster ID, which is part of the metadata. All clusters that have already consumed the data are also tracked. This prevents replication loops.
Common replication technologies:
- A central source cluster can propagate changes to multiple destination clusters, for failover or due to geographic distribution.
- A source cluster can push changes to a destination cluster, which can also push its own changes back to the original cluster.
- Many different low-latency clusters can push changes to one centralized cluster for backup or resource-intensive data-analytics jobs. The processed data then can be replicated back to the low-latency clusters.
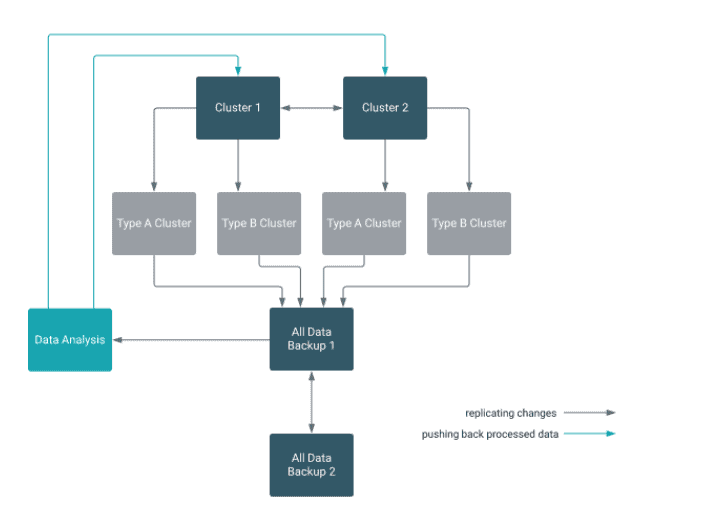
Multiple levels of replication can be chained together to suit your needs.
Dual write paradigm
Another approach to achieve asynchronous replication is to use a dual write paradigm, where the client can either write data into our persistent message queue and have it write to two instances of the database.
This approach works for some use cases where eventual consistency is sufficient for writing.
Synchronous replication
Cloudera’s OpDB supports synchronous replication of data between nodes of the same cluster as a non-optional default.
Each write is replicated to a minimum of three nodes before it is acknowledged back to the client. You can configure the number of nodes to which the write is replicated.
Heterogeneous replication
Heterogeneous OpDB replication allows OpDB to replicate between disparate OpDB vendors. This is important when multiple disparate OpDB engines are used in an organization or during a migration process to a new OpDB platform.
Cloudera provides multiple tools to enable heterogeneous OpDB replication at no additional cost. For example, Nifi is provided to enable streaming ingestion and export from any relational DBMS to Cloudera’s OpDB.
Read-only replica
It is possible to create a read-only replica, meaning that it does not support updates, deletion or creation of objects. This type of replica is suitable for read-only workload distribution and business continuity planning.
You can create a read-only version in two different ways:
- Replicate the database to a second cluster which is marked as read-only.
- Use the “read replica’ feature where the clients send the request to all RegionServers hosting replicas of the data, including the primary. The client accepts the first response, which includes whether it came from the primary or a secondary RegionServer.
Read and write operationsRead/Write replica
Read/Write RrReplicas supports read and write operations as part of an active-active cluster with conflict resolution. This type of replica is useful when replication is used to synchronize two different clusters in a bi-directional manner. This allows both clusters to be writable in an active-active configuration.
Within the scope of a single cluster, all writes are done in a distributed nature ensuring that a minimum of three copies are written across multiple nodes prior to acknowledging the client. This is done with conflict resolution to ensure that strong consistency is provided to clients.
Error protection
OpDB also protects from user error. This capability is provided in both of our storage engines.
If the user error is something like ‘I didn’t mean to delete this record’ the users can retrieve the record record prior deleting using setTimeRange.
In addition, taking regular incremental backups or snapshots enables users to roll back to the last saved recovery point.
Conclusion
In this blog post, we looked at how you can configure and use the high availability capabilities in OpDB. In the next article, we’ll cover the data integrity capabilities of OpDB in CDP.
Editor's Choice

