

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is part seven of an on going series about the Open Hybrid Architecture Initiative. You can learn more about the vision, key tenets, real-world use case, new storage environment of O3, participation in the Cloud Native Computing Foundation, and running stateful containers on YARN by reading blogs from earlier in the series.
In today’s day and age, data is an extremely important resource for enterprises. As organizations work to get maximum insights from data in near real time use cases, the legacy architecture and experience needs an update. It needs a user experience that is driven by customer insights, validation and feedback. A robust design thinking process to get close to a solution that is delightful to the customer.
The proliferation of the cloud with its flexibility emphasizes a need to bring the benefits of the native cloud architecture to on-premise setups. An enterprise ready hybrid experience involves bringing the best of both worlds – on-Premise and multiple cloud to power use cases such as deep learning and predictive analytics.
The Cloud Native journey will not be complete without a powerful but easy to use consistent experience and interaction model across different environments. The Open Hybrid Architecture Initiative is an effort to provide this modern architecture & experience no matter where the data resides – On- prem, cloud or the edge. Enterprises can now leverage the power of Big Data to access an enterprise ready agile architecture with a unified experience for different personas.
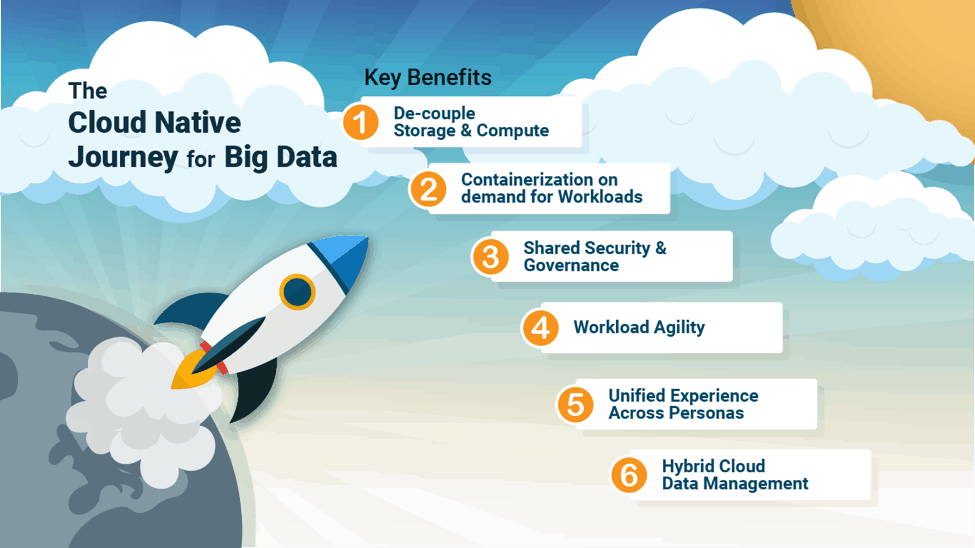
As we began the process of designing the user experience of this new architecture, one of the key things we kept in mind was the audience we were designing for. Hadoop has come a long way. In the early days, users were satisfied with a barebones experience as long as the tech was strong and the features worked. As time went on and more and more people adopted Hadoop, the users shifted from the early adopters to the general audience. It became imperative to provide a more streamlined experience with substantial thought given to solving the problem in the right way with a focus on usability and ease of use.
The OHAI is not a simple one team project. It is a broad effort across multiple open source communities, the partner eco-system and the Hortonworks Platform in order to bring the cloud architecture on-prem in a consistent manner. As such, it involves bringing multiple initiatives into one cohesive platform so that the users experience is seamless.
Primary Personas
The primary personas this initiative aims to help are
- IT Operations team ( IT Adminis, Operators )
- Big Data Analytics team ( Data Scientists, Business Analysts, DevOps )
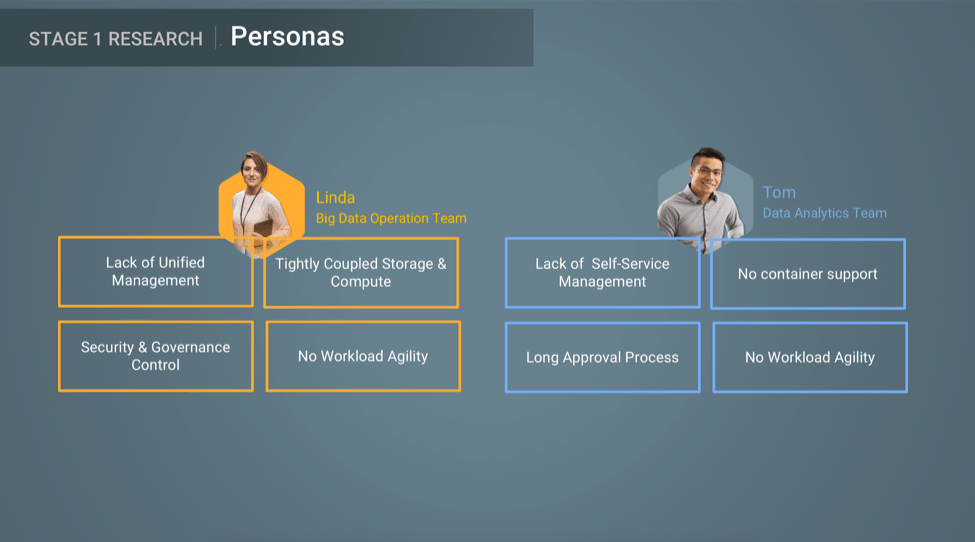
The IT operations team would like to see all the data – on-prem or cloud, in one place and be able to move data and workloads between them easily.
Being able to react quickly to business needs implies:
1. Having fine-grained control over scaling of storage and compute, and sometimes need dictates scaling one independent of the other.
2. Enterprise readiness in the form of Security, Governance, and Compliance
3. Efficient management of metadata and attaching security policies to new datasets, services, and workloads.
4. Being able to give teams the right versions of services they need when they need them – without having to upgrade everything and impact every tenant.
The tenants, on the other hand,
1. Need new versions of tools as soon as they come out without heavy wait times and ticketing processes.
2. They are familiar with developing solutions that use containers for running workloads and managing dependencies and wants a system that allows them to use this experience and existing assets.
The Experience Design Process
The experience design process began with validating the pain points with actual customers. A key tenet of the user centered design process is to involve the customer at each stage and validate often with their feedback.
A secondary goal of the process was to gain pointers on how to solve the pain points in a manner consistent with what our customers would expect and find delightful.
Step 1: User Research
The whole team came together to compile a list of questions or clarifications that were needed from customers. These were then compiled into a streamlined user interview script. The aim was to get customer feedback without asking any leading questions or biasing the users.
The research interviews involved 1 – 1.5 hour conversations with customer representatives matching our target personas. In addition to these internal SMEs from different industry verticals were interviewed covering different use cases. The responses were synthesised into customer research insights with the help of Engineering and PM leads.


Some of the key insights were –
- Companies use a mix of on premise, private cloud, and public cloud solutions.
- Security is hard. But it is a key requirement.
- Ephemeral clusters are needed. Storage & Compute decoupling is needed.
- A solution that boasts enterprise readiness is a key differentiator.
- Self-Service is valuable.
- Providing IT enough control in terms of security and governance but enough flexibility to tenants quickly spin up new clusters with new versions of our technology for PoC and test/validation is a big value add.
- Users need a way to control/manage costs. This seems to be important to all customers across the board as controlling costs in the Cloud is a pain point currently. Chargeback model with priority support for costing would be useful.
- Logging and error detection is not easy. Logs should be available in one place and easy to analyse.
- Need a solution that provides a single pane view of key metrics, issues, errors and ways to recover.
Step 2: Design
After consolidating information on the key personas and use cases, the next step was to brainstorm many different ways to solve the problem. A critical part of Design Thinking is to consider multiple solutions and think through the pros and cons of each without fixating on one solution. Armed with the insights from the customer interviews and a competitor landscape research, a design session called the ‘Design Studio’ was conducted. Multiple designers working on different products came together to brainstorm at high level ideas and ways of solving the pain points. These were very rough sketches. The key point was to explore multiple options before we finalised on one.
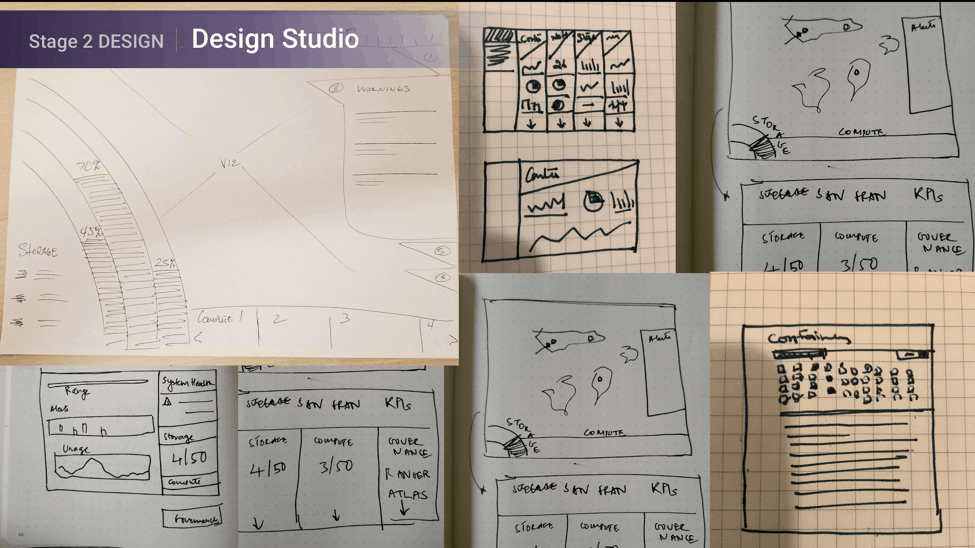
Based on these the final design concept was chosen and worked upon by the lead designer and the product team.
The results of this process were as below.
Keeping in mind the customer pain point of a single pane of glass to see their entire system and details associated with it, a simple dashboard was designed that shows all the environments in the customer’s system.
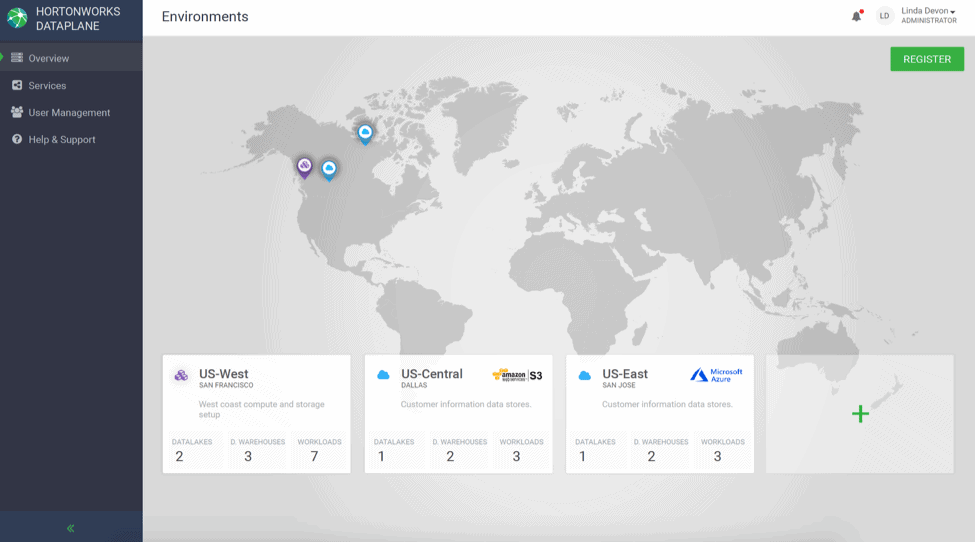
The environments page allows the administrator to see all the environments in one place. This is a good way to view the entire ecosystem while allowing quickly access to specific environment details and monitoring workloads running in that Environment.
Selecting an environment shows a detailed screen with information about the workloads, overall compute, storage and workloads associated with this Environment.
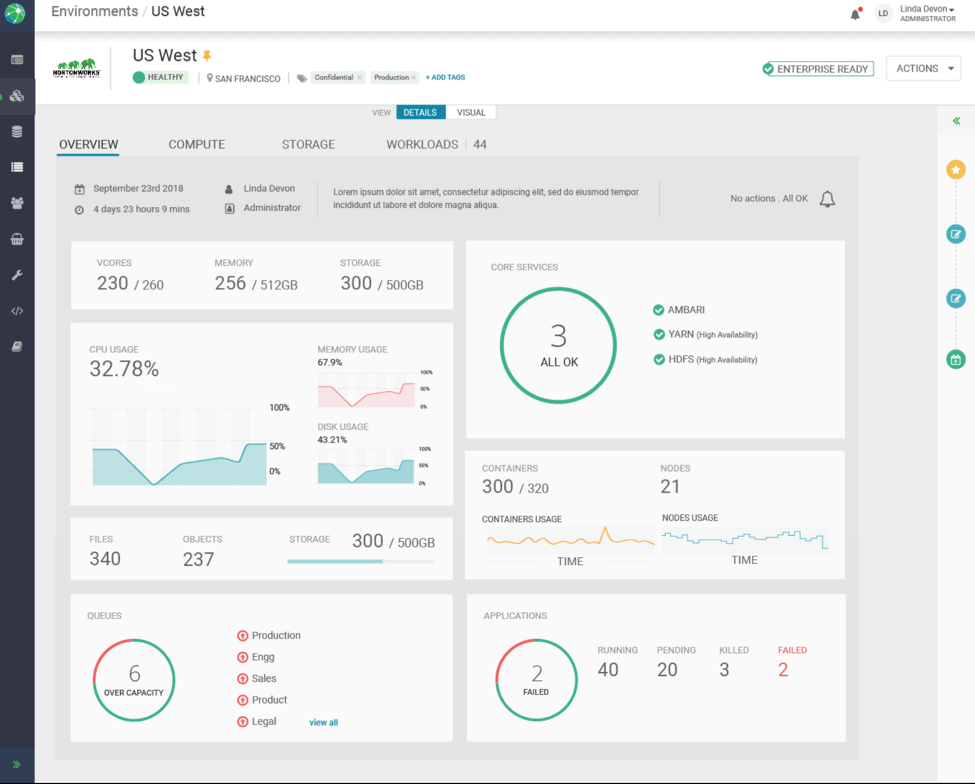
This image shows how each pain point is addressed by this new design.
Each Environment can be associated with one or more Datalakes. A Datalake gives a shared and persistent security and governance layer to enforce access control and data governance centrally.
In addition each tile on the dashboard gives the customer insights about the overall Containers, Core Services, Storage, Compute and Queues which can then be used to manage these resources.
Each Datalake can be associated with multiple workloads. By associating a Datalake with a Workload, that workload automatically is attached to the security policies and metadata within it. This association makes it very easy to quickly spin up new Workloads without having to duplicate or redefine security policies and key schemas and metadata.
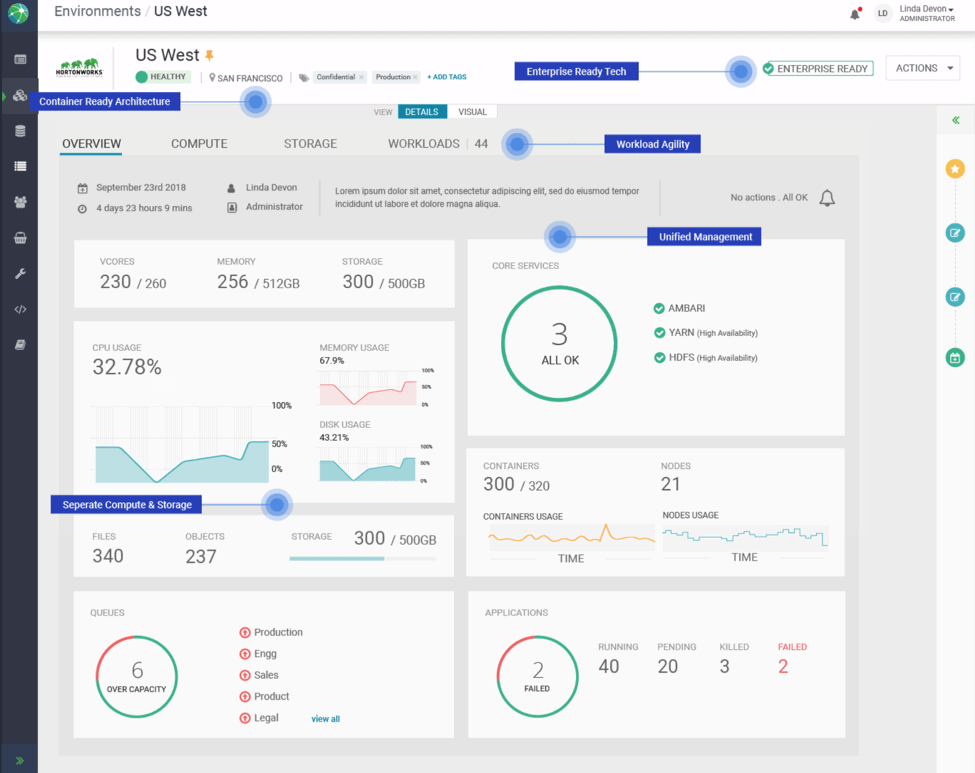
Powered by Apache Yarn, the Compute tab of the environment provides an easy way to manage compute resources. Apache YARN with its advanced capabilities can handle diverse workloads from real-time interactive queries to batch workloads at scale in an elastic manner. YARN serves as a powerful job scheduler for the hybrid environment. It complements Kubernetes, the container orchestrator, which does not have a capacity scheduler like YARN.
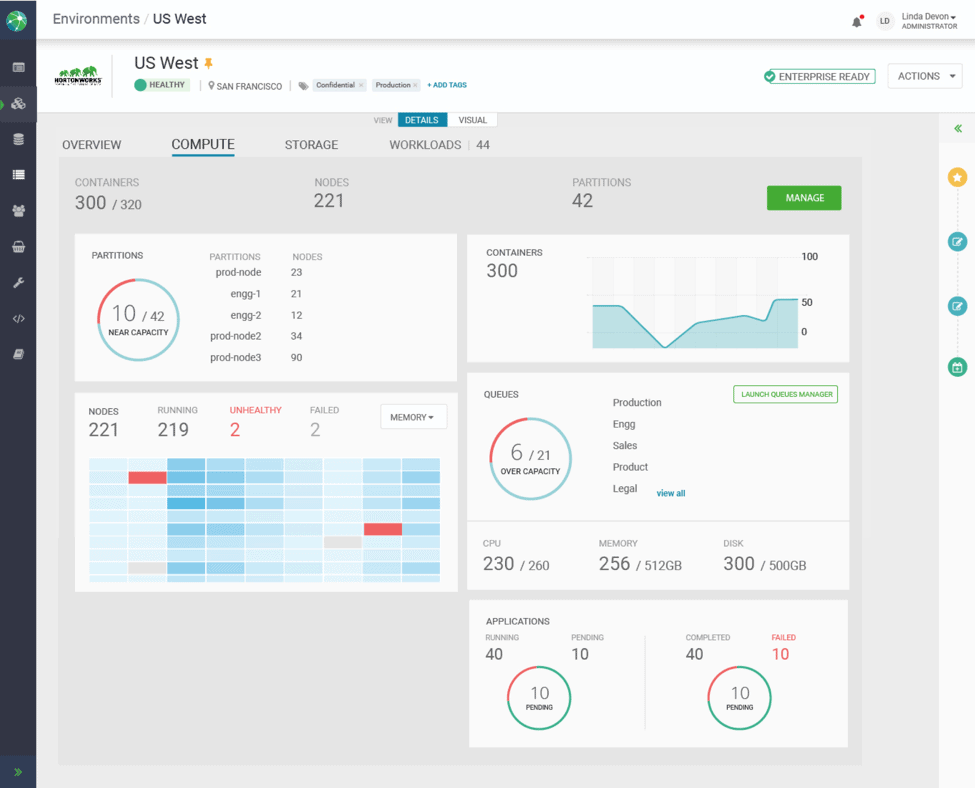
The storage is provided by HDFS and the new Apache Ozone (O3). Apache Hadoop Ozone or O3 is the next generation object storage that is the foundation of the Open Hybrid Architecture Initiative.
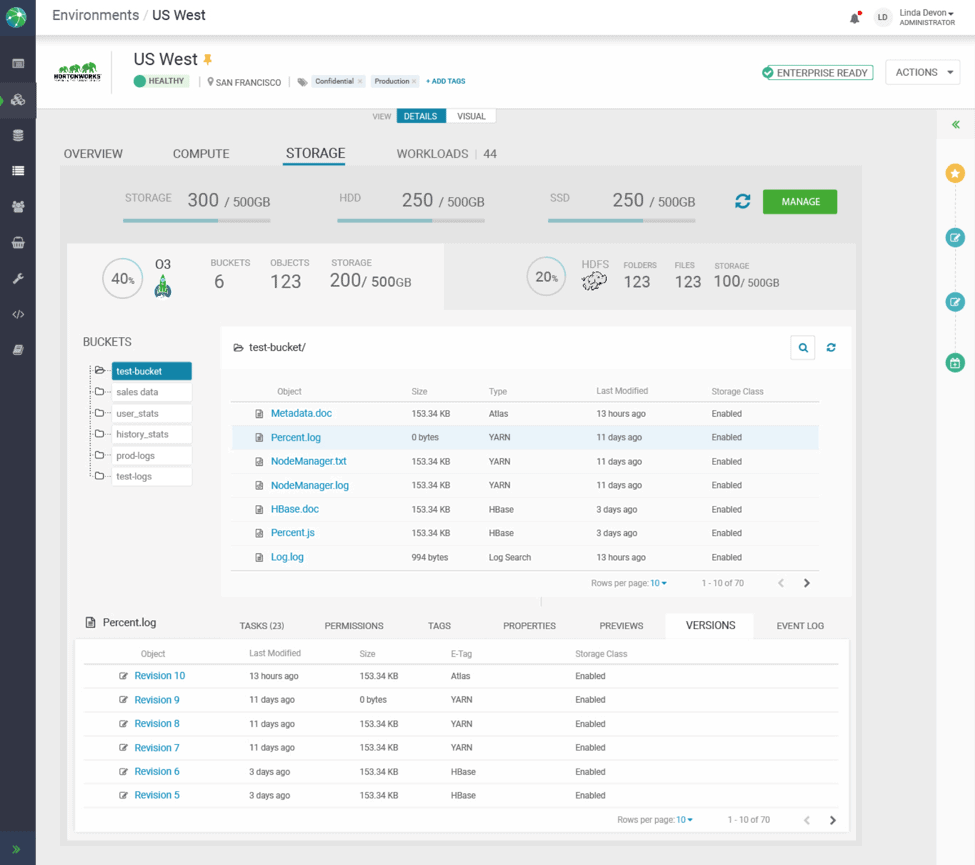
With all of these concepts in place, an admin can quickly provision a Workload (Data Science, EDW) in a few minutes.
The admin can choose from multiple available versions for each Workload as soon as a new version becomes available, all integrated with Security & Governance services a reducing the time to deployment from months to minutes.
The Open Hybrid Architecture Initiative is our effort to bring all the innovation we’ve done in the cloud down to the on-premise environments with a consistent delightful user experience to match. Powered by a robust design thinking process we hope to deliver a best in class solution that our customers will enjoy using.
Read More about the Open Hybrid Architecture Initiative
Editor's Choice

