

Text classification is a ubiquitous capability with a wealth of use cases. For example, recommendation systems rely on properly classifying text content such as news articles or product descriptions in order to provide users with the most relevant information. Classifying user-generated content allows for more nuanced sentiment analysis. And in the world of e-commerce, assigning product descriptions to the most fitting product category ensures quality control.
While dozens of techniques now exist for the fundamental task of text classification, many of them require massive amounts of labeled data in order to prove useful. However, collecting annotations for your use case is typically one of the most costly parts of the machine learning life cycle. This is especially true in two typical real-world scenarios: emerging classes and rare classes.
Very few real-world use cases have categories that are eternally set in stone. The reality is that new classes, topics, and categories will likely emerge over time as business needs evolve. For example, a new product line is introduced that doesn’t fit with any existing product categories; or new forums and topic threads are created organically by users. These emerging categories may not contain enough examples for a traditional machine learning algorithm to learn from, making high-quality classification difficult or prohibitive.
Another fact of real-world use cases is the uneven distribution of data. For example, products on Amazon are not evenly distributed between “Pet Supplies,” “Fine Art,” and “Collectable Coins.” Instead, some categories are very popular and contain many, many products, while others are relatively obscure. Under-populated categories are another scenario in which we may not have enough examples to leverage traditional machine learning approaches. In these cases, we need a way to learn from a limited number of training examples.
At Cloudera Fast Forward, we are no strangers to learning with limited data. We’ve covered several techniques in our research, including active learning, in which humans and machines collaborate to label data in a clever way, essentially bootstrapping from a small amount of labeled data; and meta-learning, in which deep learning algorithms learn to learn. While generalizable, these approaches didn’t focus on text classification so this time we explore a classic technique with a modern twist that can perform text classification with few or even zero training examples! We’re talking about text embeddings, of course.
Text embeddings made a splash in the machine learning and natural language processing communities back in 2013 when word2vec broke onto the scene, forever changing the way researchers and ML practitioners represent text numerically. In the years since, new advances have dramatically increased the quality of these text embeddings and, by extension, the ability to use these embeddings as features for text classification.
One of the key insights to quality text embeddings, first pointed out by the word2vec authors, is that words with similar meanings tend to have numerical representations that “live” close to each other when plotted in a graph.
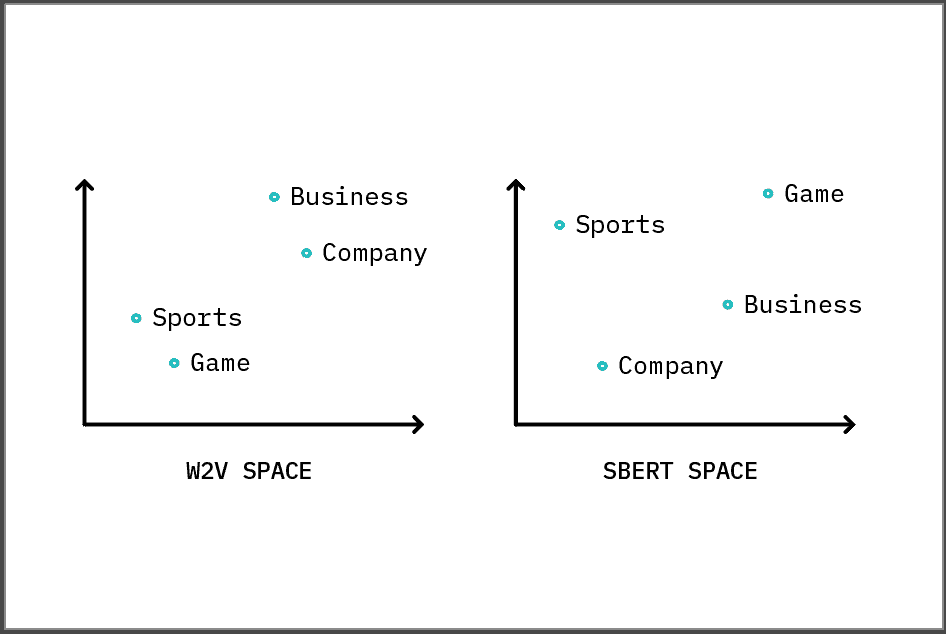
For example, if we generate text embeddings for the words “sports,” “game,” “business,” and “company,” and plot them, we might see the above figure — and a relationship between the words. A “game” is a singular event in “sports,” while a “company” is a singular entity that conducts “business.” We can then leverage the relationships between words in order to classify text. That is, if two pieces of text are close together, they are probably alike, and if we know the label for one of them, we know the label for both of them!
This is all well and good for words, but what about documents? Traditionally, embeddings for documents have been generated by first computing a word embedding for each word in the document and then averaging them all together. Unfortunately, this process doesn’t take into account the fact that many words don’t contain a great deal of meaningful information (e.g., “the,” “at,” or “it”). While this can be remedied by removing such words, these methods also struggle to take the order of words into consideration: “Dog bites man” has a very different meaning than “Man bites dog”!
That’s where modern advances come to the fore. In the past year, document embedding methods have far superseded the quality of word2vec and other word embedding methods. Document embedding methods generate a numerical representation for the document as a whole, obviating the need to aggregate individual word embeddings. One of the most promising is Sentence-BERT, a version of the BERT NLP Transformer that is specifically designed to generate embeddings for sentences and paragraphs that capture the semantic relationships between them.
In our newest research we dig into how to apply these techniques for classifying text data with few or zero training examples. We also introduce a new prototype so you can try it out for yourself!
Editor's Choice

