

Introduction
In the last few years, IT security threats to enterprise systems have increased, which has necessitated installing log ingestion and analysis solutions in any enterprise network.
This blog post illustrates how Cloudera built its own scalable solution for log ingestion and analytics using Apache Spot and Cloudera Altus. By leveraging transient workloads in the cloud, Cloudera reduced the solution’s operational costs by 50% when compared to traditional, persistent cluster approaches.
Use Case
At Cloudera, the Infosec team needed to build a centralized log ingestion and analytical solution to monitor all key systems in the company for anomalous security events. The Infosec team chose to build their solution on Apache Spot, as Cloudera was one of the founding organizations of that project. The first iteration was deployed using persistent cloud-based infrastructure, however this turned out to be rather costly due to the bursty resource utilization profile of this use case. To address this, a new deployment of Apache Spot was moved to a cloud-based infrastructure — using transient clusters — that better matches the resource utilization profile, resulting in lower operational costs.
Introducing Apache Spot
Apache Spot is a community-driven cybersecurity project that brings advanced analytics to system, network, and application logs in an open, scalable platform. Instigated by companies including Cloudera, Intel, StreamSets and others, Apache Spot was first released as open source in 2016.
Spot aims to gain insights from network flow and packet analysis. Spot expedites threat detection, investigation, and remediation using machine learning techniques and consolidates all enterprise security data into a comprehensive IT telemetry cluster based on open data models.
The Cloudera Infosec team’s cluster needed to ingest and process the following types of logs:
- Amazon AWS VPC Flows logs
- Web Server access logs
- Cloudera Navigator logs
- Syslogs from cluster nodes
All of these logs are loaded to Amazon S3.
The team chose to use the SPOT-181_ODM branch of the Spot project, which includes the new Open Data Model feature. Using this, Apache Spot can handle multiple types of logs in the same table. Moreover, this branch uses StreamSets to ingest event data instead of Apache Kafka. Therefore, users can use a graphical interface for mapping the source data structure to ODM schema. Read more about Spot here.
Spot has the following modules:
- Ingest module: In the Cloudera Infosec deployment, this phase uses StreamSets to load logs from row format into the oni.event Hive table. Here Spot maps raw log formats to the Open Data Model schema. Read more about StreamSets here.
- Machine learning module: Spot uses the LDA model to find anomalies in the system by analyzing logs using Apache Spark 2.
- Operational Analytics (OA) module: An additional processing step after machine learning, including noise filtering, whitelisting, and heuristics-based analysis.
- Visualization module: The Cloudera Infosec deployment uses Arcadia Data (a BI tool for big data) to visualize Spot data.
Initial Approach: Persistent Cluster
A block diagram of the initial solution looked like this:
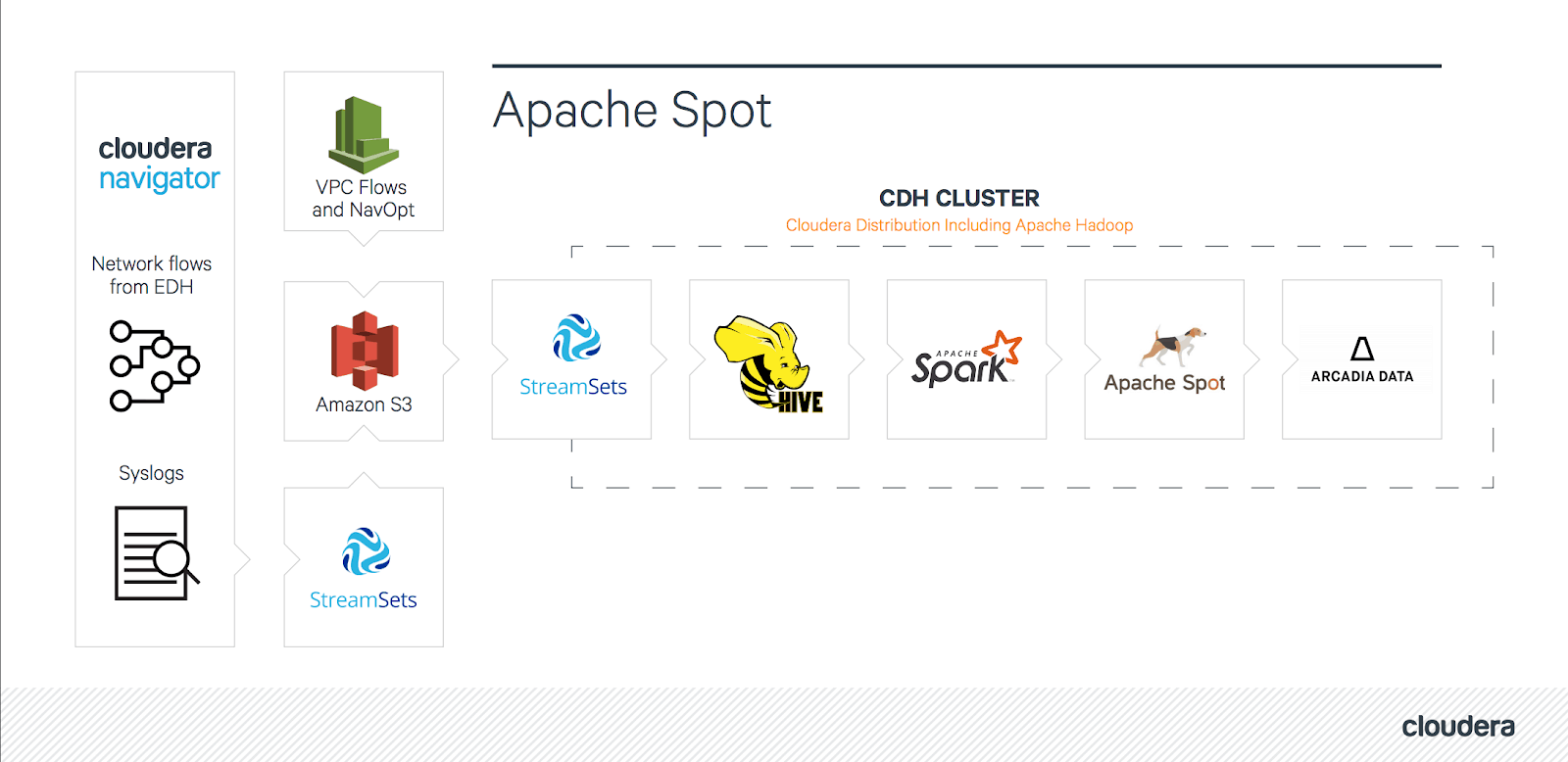
High-level diagram of initial approach
As this diagram shows, the deployment includes multiple log sources. The dashed rectangle is the CDH cluster that contains all phases of Spot. This approach uses different StreamSets instances inside and outside the Spot cluster.
To meet the needs of this project, a few other minor changes were required on the SPOT-181_ODM branch. For example, the partition columns on the oni.event table were changed to fit the partitioning to the Cloudera dataset in order to get faster response times. The implementation also creates multiple pipelines for StreamSets to ingest datasets—like Cloudera Navigator logs—into Spot.
Challenges
Although this initial solution functioned, the cluster had to be permanently sized to support the resource-intensive machine learning (ML) and log ingestion phases, despite the fact that these jobs run for only a small part of the day. Furthermore, there was a need for the visualization functionality to be up 24/7. Thus Cloudera needed to develop a solution that could allocate extra resources to the system on the fly when executing ML jobs, but use a smaller cluster to serve the visualization needs the rest of the time.
Transient Workloads with Cloudera Altus
The easy compute resource provisioning capabilities of the public cloud made this environment ideal for addressing the requirements previously described, and Cloudera’s cloud-native platforms made deployment of a solution to meet these needs extremely straightforward.
Cloudera has multiple, powerful tools to enable the creation of Apache Hadoop clusters in the cloud. Cloudera Altus Director provides a flexible, self-service deployment tool for self-managed, cloud-based clusters. This option allows for maximum flexibility in deployment and configuration options, but requires more hands-on management. For a more fully-managed experience, Cloudera offers Cloudera Altus Services, including Cloudera Altus Data Engineering, a managed service for running large-scale data pipelines in the public cloud. The Shared Data eXperience (SDX) capabilities in Altus provide persisted metadata and data context in a multi-cluster system of transient clusters used for one or more data analysis tasks. This combination allows for the creation of multiple specialized, out-of-the-box clusters with one shared Hive Metastore.
Learn more about Cloudera Altus Data Engineering
Cloudera SDX enables multiple clusters to share the same consistent view of enterprise data and metadata hosted on Amazon S3 and Microsoft Azure Data Lake Store (ADLS). At the heart of SDX on Altus is a repository of attributes describing locations and structure of data, access rights, business glossary definitions, lineage and more.
The Cloudera Infosec Spot deployment uses the SDX shared metastore to ensure access to tables among persistent as well as transient clusters. Each cluster in the same namespace uses the same SDX to store Hive metadata, allowing for the creation of a seamless data pipeline across multiple distinct clusters.
Optimized Solution
The Cloudera Infosec team had already identified that they could lower costs by using Cloudera Altus with transient clusters, however there was still a need for the resulting data itself to be accessible at any time. To achieve these goals, the Infosec team chose to split the deployment into persistent and transient parts. The persistent cluster is smaller and used for visualization; the transient cluster is used for ingestion and machine learning. When working to determine the right type and size of the transient cluster, the Infosec team realized that splitting the transient portion of the pipeline into two separate transient clusters for ingestion and machine learning would provide an even more capable and cost-effective solution, as the resource requirements of these two tasks are totally different. In the final design, the complete solution uses three clusters: one for ingestion, one for machine learning, and one for visualization. The flexibility of the public cloud, combined with the ease of use of Cloudera Altus, allowed for rapid prototyping and testing of different deployment options to determine the ideal overall architecture, as well as the flexibility to use different instance types as appropriate for each stage of an overall data pipeline.
To further reduce management work, the persistent visualization cluster is actually implemented as an easily recreatable transient cluster, just with a long operating time. In this way, if there’s ever a need to make any changes to this cluster, it can deleted and recreated with the new configurations using scripts, all while maintaining the uptime requirements of the visualization portion of the solution.
The above implies that there will be times when there are no clusters at all, and therefore this solution cannot rely on the presence of a persistent HDFS file system. Fortunately, Apache Hive supports external tables on S3, and thus Hive/Impala tables can be used; these store data directly in S3 and metadata as well as data context in SDX. The use of cloud-native data storage combined with Altus’s ease of creating transient or persistent clusters allows for maximum flexibility.
With this, we have the following architecture:
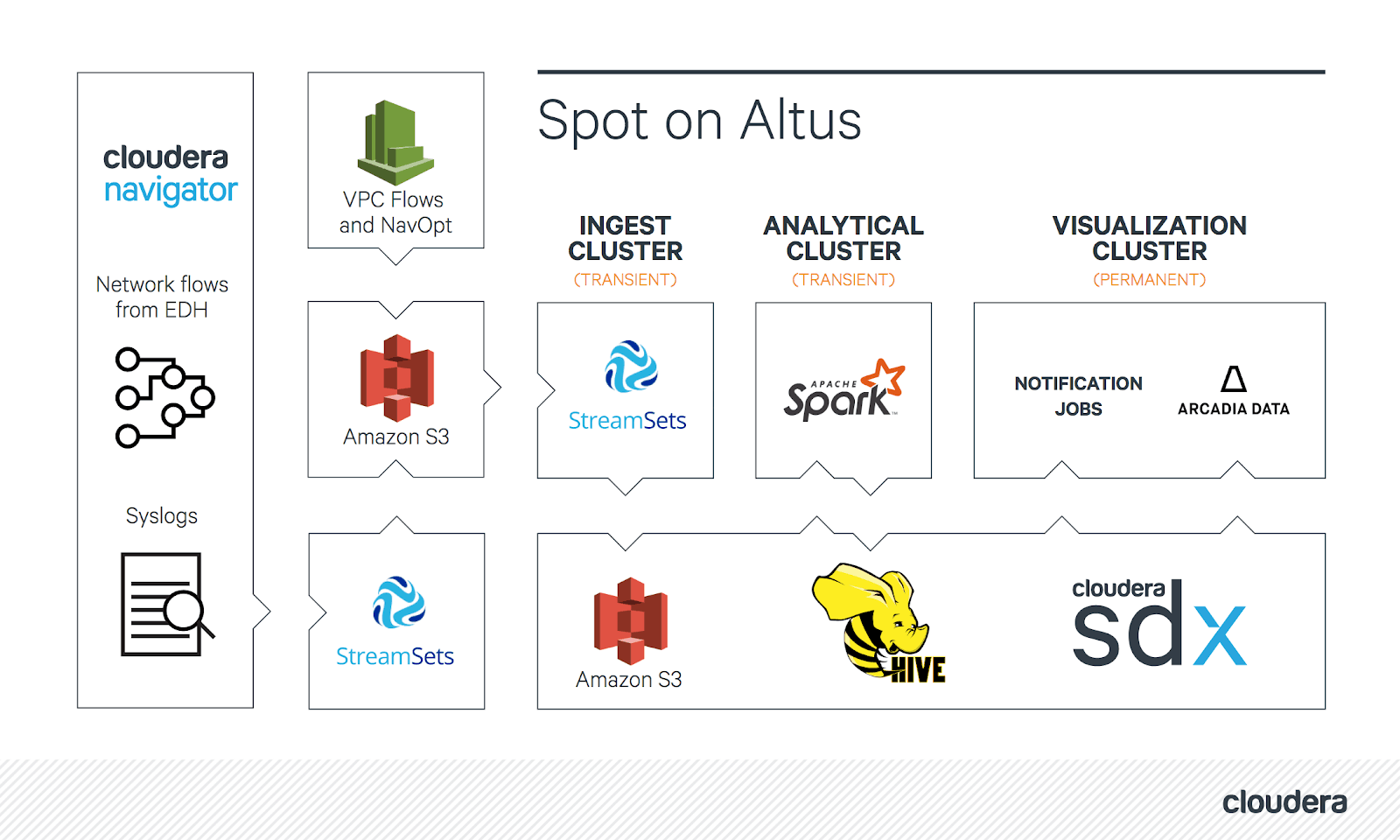
High-level diagram of Apache Spot on Altus
The Cloudera Infosec team was able to get started by using the quickstart wizard within Altus to create an Altus environment by following these instructions.
Quick Start Wizard
The Cloudera Infosec team created an SDX namespace by choosing a name; no other parameters were needed. When creating a cluster, one need only specify this namespace in order to be able to access the same shared Hive Metastore.
SDX Namespace create pop-up
The Cloudera Infosec team uses the following Altus CLI command to create the cluster for the machine learning portion of the pipeline (see more details here).
altus dataeng create-aws-cluster --cli-input-json '{"clusterName":"Spot-test-ns",
"cdhVersion":"CDH514",
"instanceType":"r4.large",
"serviceType":"SPARK",
"environmentName":"<crn>",
"workersGroupSize":3,
"instanceBootstrapScript":"",
"computeWorkersConfiguration":{
"groupSize":0,
"useSpot":false,
"jobs": [
{ "name": "Spot-Prepare",
"failureAction": "NONE",
"pySparkJob": {
"mainPy": "s3a://myspot-scripts/<file>.py",
"pyFiles": [],
"applicationArguments": [],
"sparkArguments": ""
}},
],
"publicKey": <public key>
"namespaceName":"myspot-namespace"
}
Because Altus jobs creates the Analytical Cluster, the cluster will automatically terminate after the (py)Spark jobs are completed.
In order to adapt the solution to work with transient clusters, the following code changes were required:
- StreamSets pipelines originally worked continuously, so the pipelines had to be changed to daily batches. The biggest challenge was that StreamSets was designed for continuous deployment. Fortunately, StreamSets has a feature called “Pipeline Finisher Executor,” which can detect when the ingestion has finished, and stops the pipeline. This was a straightforward solution to implement a batch mode of operation.
- The create table SQL scripts used in the first version of the solution had to be adjusted to allow the use of S3 for storing data.
- After some initial testing, it was discovered that loading data directly from S3 on Arcadia Data was not performant enough to meet our visualization serving needs. To address this, the team created a local cache of the log event S3 table in HDFS/Impala. This cache is populated each day with the last 30 days of log events. Use of this cache resulted in a significant performance improvement.
To coordinate the creation of transient clusters, a control script was created using the Altus CLI. This script is executed from a cron job in order to run on a schedule, and it creates and stops all of the transient Altus clusters and jobs. This cron job runs on another ec2 instance in the same VPC where the clusters are running.
The last task was to determine the optimal cluster sizes and instance types. After some testing, the following instance types were determined to be ideal for this use-case:
- Ingest Cluster: m4.large
- Analytical Cluster: r4.2xlarge
- Visualization Cluster: r4.xlarge
The number of nodes used in the cluster is adjusted based on the size of the data set.
Result
Over the course of development, the Cloudera Infosec team found many benefits of Cloudera Altus, but perhaps most notably among these was rapid prototyping. Because of the ease of deployment facilitated by Cloudera Altus, overall development time of the solution was dramatically reduced, as well as enabling rapid determination of the optimal instance profiles for each stage of the data pipeline. As a result, the Cloudera Infosec team was able to deploy a low-cost, scalable solution which saves more than 50% of the cost compared to the original Apache Spot deployment.
Editor's Choice

