

Insurance carriers are always looking to improve operational efficiency. We’ve previously highlighted opportunities to improve digital claims processing with data and AI. In this post, I’ll explore opportunities to enhance risk assessment and underwriting, especially in personal lines and small and medium-sized enterprises. Underwriting is an area that can yield improvements by applying the old saying “work smarter, not harder.” To me, this means that by applying more data, analytics, and machine learning to reduce manual efforts helps you work smarter. According to a recent McKinsey report, digitized underwriting can improve loss ratios three to five points. It’s not easy, but it can be done in pragmatic steps to yield results. Progress fortunately does not require a major multi-year renovation project, but can be realized with an iterative, learn-as-you-go approach.
Step one: gather the data
Utilizing a variety of data sources creates a more accurate picture of risks. This is done by providing additional insights on behaviors while at the same time providing degrees of risk to assess the total exposure. This approach does not by definition mean that we need great quantities of data sources, just that we need the right ones. For example, alternative data sources such as fitness trackers offer lifestyle indicators. Combining this data with more classical information such as annual checkups and medical records provides better insight into risks related to health, disability, and life insurance. IoT examples such as telematics-based travel or car insurance enable a very personalized insurance policy (more on this in a prior post).
There are many third-party data options in today’s marketplace to further enhance underwriting, so it is important to select the ones that add the most value to risk assessments. Currently we see a lot of emphasis on location and weather data, as well as pictures and video. These data points complete risk profiles and enable improved decisioning on wordings and conditions, features, and rates. Depending on risk appetites, these new data sets may be weighted higher or lower in the underwriting process, but making this data available offers another data point that helps risk assessment, especially as more automation is deployed.
Incorporating these new data sources into the underwriting process does not have to be a massive overhaul of infrastructure that takes years to roll out. To support the collection of the right data sources—real-time or batch—more quickly into an organization’s process flows, Cloudera supports the concept of universal data distribution (UDD). Simply stated, this approach enables data to be collected from any location and reside in any location for analytics to then be performed. You can read more about UDD here. To make a long story short: this exciting approach enables you to more quickly utilize these data sources to help with your underwriting.
Step two: expand machine learning and AI
Once you have access to additional data in your underwriting processes, the real advancements in efficiency occur using machine learning (ML) and AI. Here too, I recommend an evolutionary, stepped approach for advancing your capabilities while learning as you go. Enabling production ML and AI starts with enabling quality reporting—gaining a better understanding of insured risks, exposures, and prospects. The next step leads to performing exploratory, descriptive analytics, “why is this happening,” and so on. Finally, the end goal is to enable proactive, predictive analytics—“what if”—using applied ML and AI to better predict what will happen and recommend actions to prevent or manage activities as necessary.
Each of these advancing phases of ML and AI incorporate additional data sources as illustrated in the diagram below.
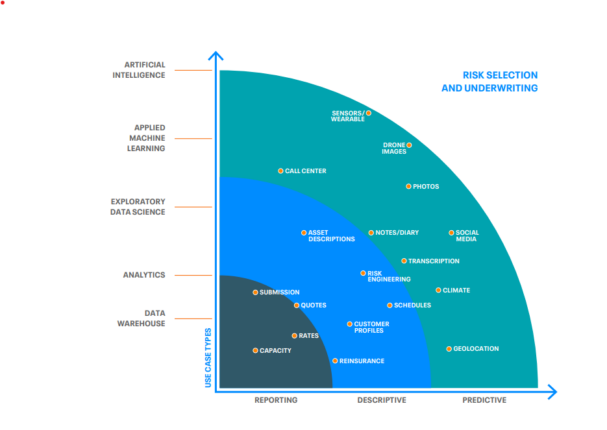
This diagram reflects a large selection of data sources, but it is more important to focus on the specific data that will provide the most value rather than a huge variety. An example of using a subset of this data in a commercial lines example is reflected in this ebook. Enhanced underwriting evolves with the choice of the data selected and the maturity of analytics applied. For example geolocation, asset descriptions, climate/weather data, and loss history may be evaluated and provide insight on future risk selection. Adding interactive safety work programs coupled with Iot data tracking improves the risk profile while geolocation attributes allow a much more finite calculation of risk.
Within the scope of underwriting, the specific business use case will determine the data to be most relevant. Risk assessment and categorization will vary from customer segmentation, which will vary from related entity analysis. Be clear on the goal and use the most appropriate data sources.
Step three: consider your data platform
Finally, for you to enhance your underwriting in just two steps, you’ll need a strategic data approach. The approach can consist of multiple solutions from multiple providers that need to be integrated. Alternatively, a hybrid data platform that supports the various data capabilities – from data collection to ML and AI. Cloudera Data Platform (CDP) is such a hybrid data platform. CDP empowers insurance providers to take these incremental steps to get clear and actionable insights from their data. Effective underwriting, digital, touchless claims, customer service—it all requires a modern, flexible approach to manage customer profiles and risk appetite variables. Cloudera helps insurance providers modernize their infrastructure to better use this data in an incremental, achievable way. Learn more and hear about some cool customer examples in our underwriting eBook.
Editor's Choice

