

Last week, we announced the HDF 3.1 Release and commenced the HDF 3.1 Blog series. Earlier this week, in part 2 of the blog series, we introduced the new HDF component called Apache Nifi Registry which allows developers to version control flow artifacts to meet their SDLC enterprise requirements.
Today, in this third part of the series, we discuss Apache Kafka 1.0, that was introduced in the 3.1 release, and the powerful HDF integrations that customers have asked for.
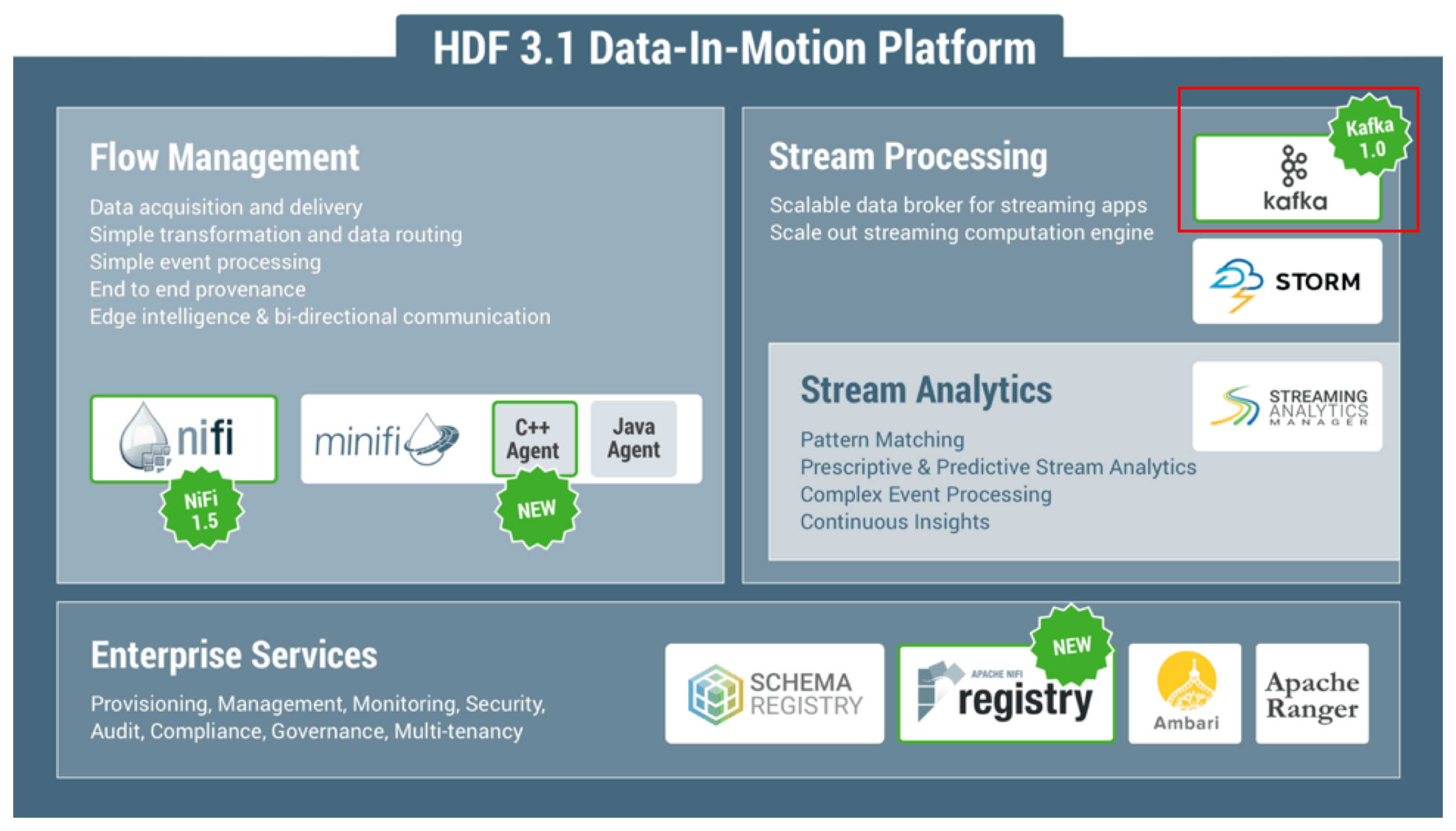
Apache Kafka .11/1.0 has some powerful new features and improvements including support for key/value message headers, improved messaging semantics (e.g: transactional support) and major performance enhancements. For details on these new features, see the following:
In this blog, we will highlight the HDF integrations that our customers have asked for with Kafka 1.0 to meet their enterprise requirements. We will showcase these integrations in the context of a streaming analytics use case.
Streaming Use Case with Common Kafka Requirements
The fictitious use case centers around a trucking company that has a large fleet of trucks. Each truck is outfitted with two sensors that emit event data such as timestamp, driver ID, truck ID, route, geographic location, and event type. The geo event sensor emits geographic information (latitude and longitude coordinates) and events such as excessive breaking or speeding. The speed sensor emits the speed of the vehicle. The trucking company wants to build real-time data flow apps to ingest the streams, perform routing, transformations, enrichment and deliver them to downstream consumers for streaming analytics.
Working with customers implementing streaming analytics use cases similar to this one, we are seeing Kafka play a crucial role in their architectures. In fact, the use of Kafka has been so prevalent that there are a common set of features that our customers are asking for that typically come from three different teams in the enterprise.
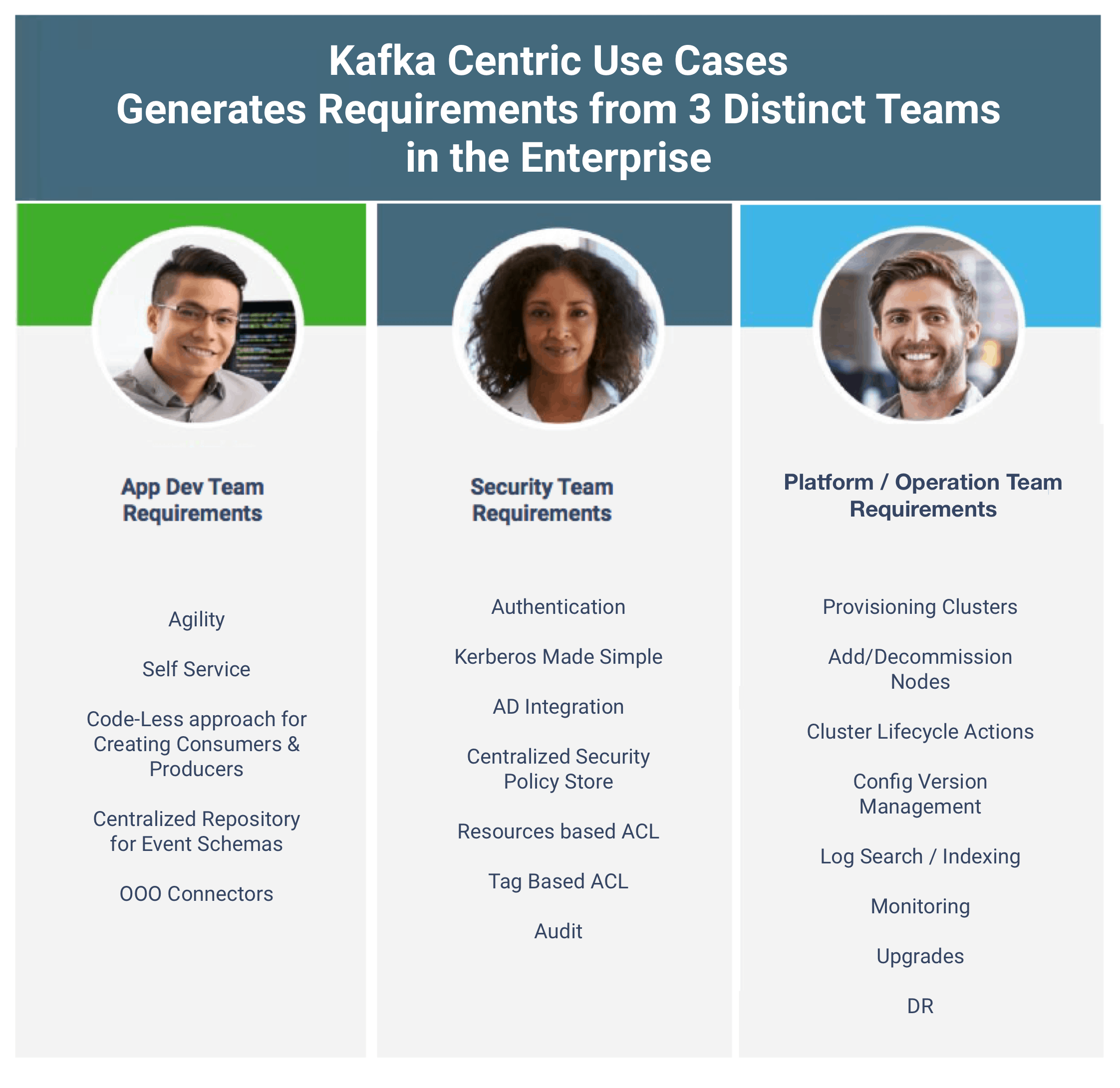 In the subsequent sections, we will talk through these requirements and how the new HDF 3.1 features address them.
In the subsequent sections, we will talk through these requirements and how the new HDF 3.1 features address them.
App Dev Kafka Requirements

Implementing App Dev Kafka Requirements with HDF 3.1
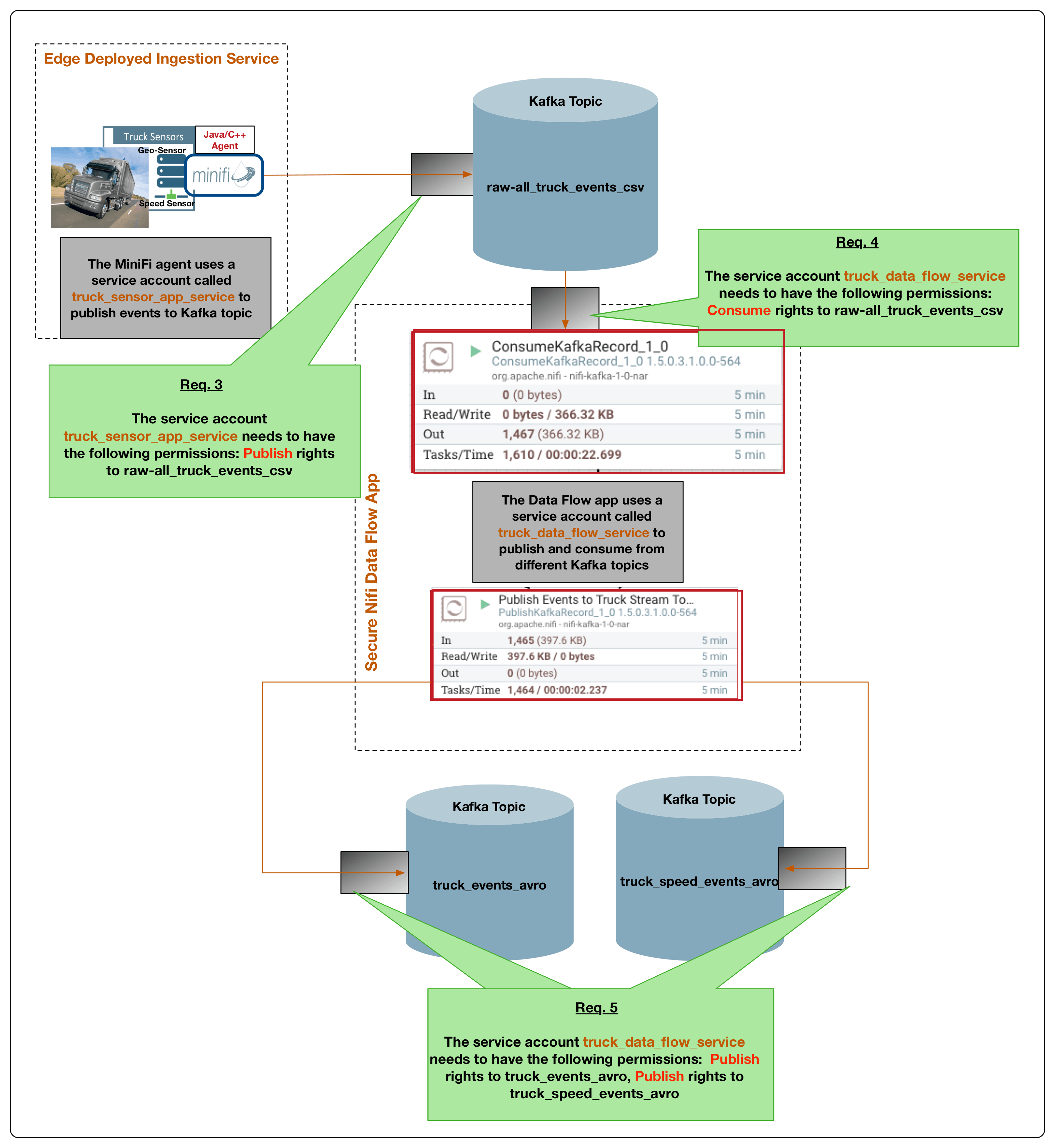
The below diagram illustrates how requirements 1 through 5 are implemented with HDF 3.1 using Apache Kafka 1.0, Apache Nifi, Apache MiNifi and Schema Registry.
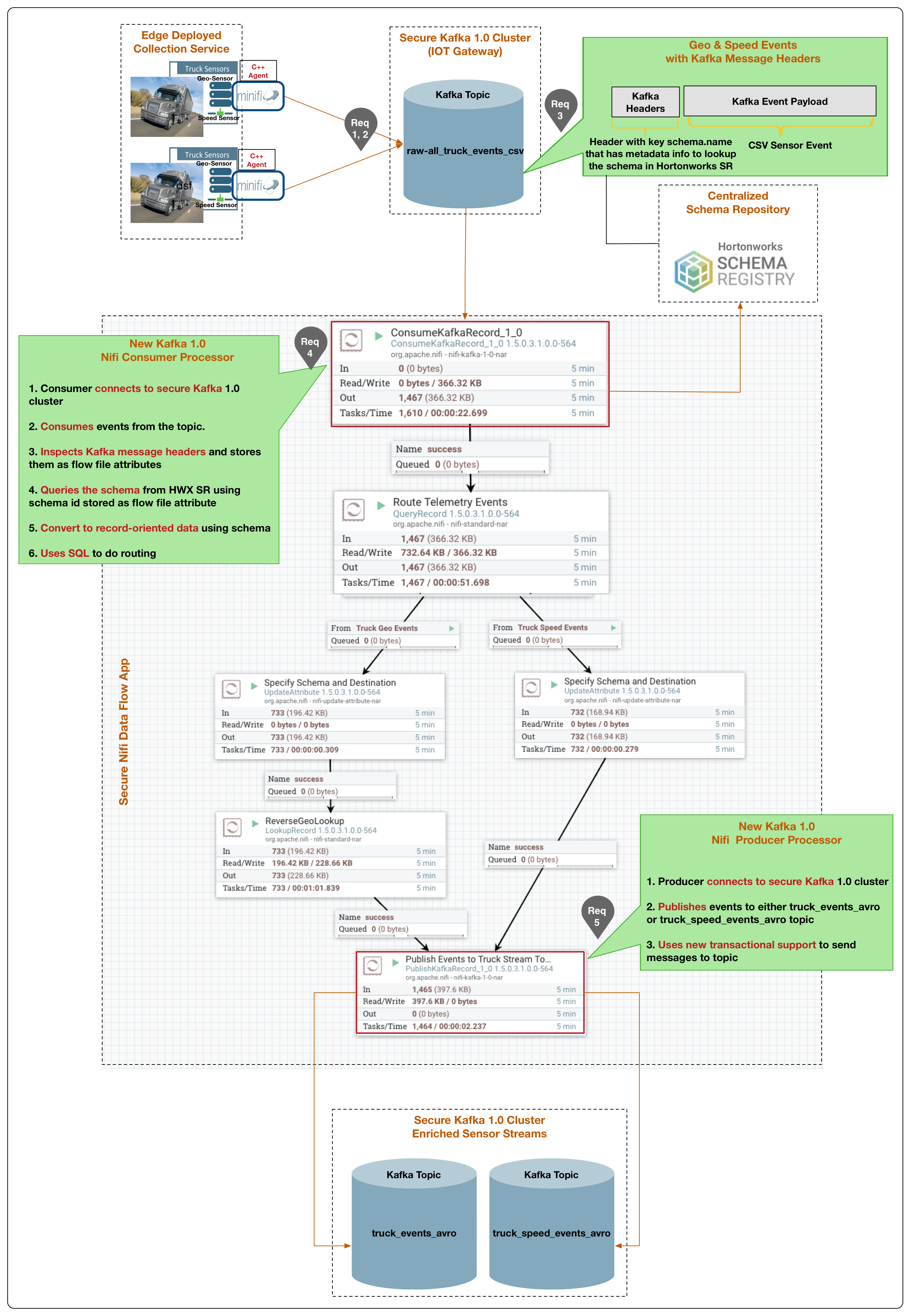
The following summarizes the above diagram describing how requirements 1 through 5 are met:
- With the introduction of MiNifi C++ agent, customers have more options to deploy edge collection agents (future blog will walk through details of this C++ agent). A MiniFi agent is deployed on the telematic panel of the truck and collects the data from the two sensors. (Requirement 1)
- The C++ MiNifi agent publishes the streaming sensor data to an IOT gateway powered Apache Kafka 1.0. The MiNifi agent will publish events in csv format and using Kafka 1.0’s new message header support, each event will be accompanied by message headers that store the schema key which is a pointer to the event schema in the Hortonworks Schema Registry (Requirements 2, 3).
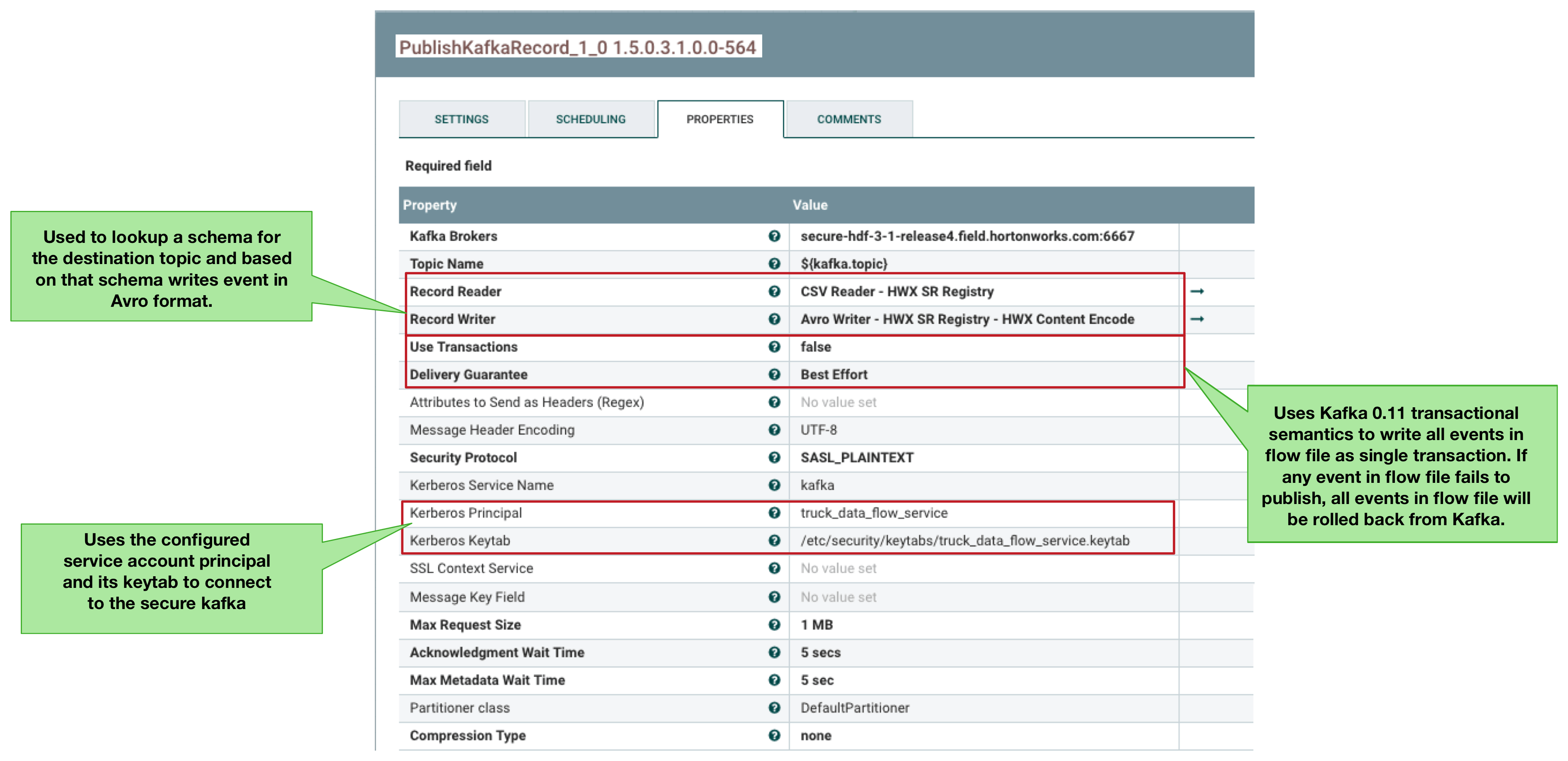
- NiFi’s new Kafka 1.0 consumer processor called ConsumeKafkaRecord_1_0 consumes the streaming csv events from the Kafka topic (Requirement 4). The processor does the following:
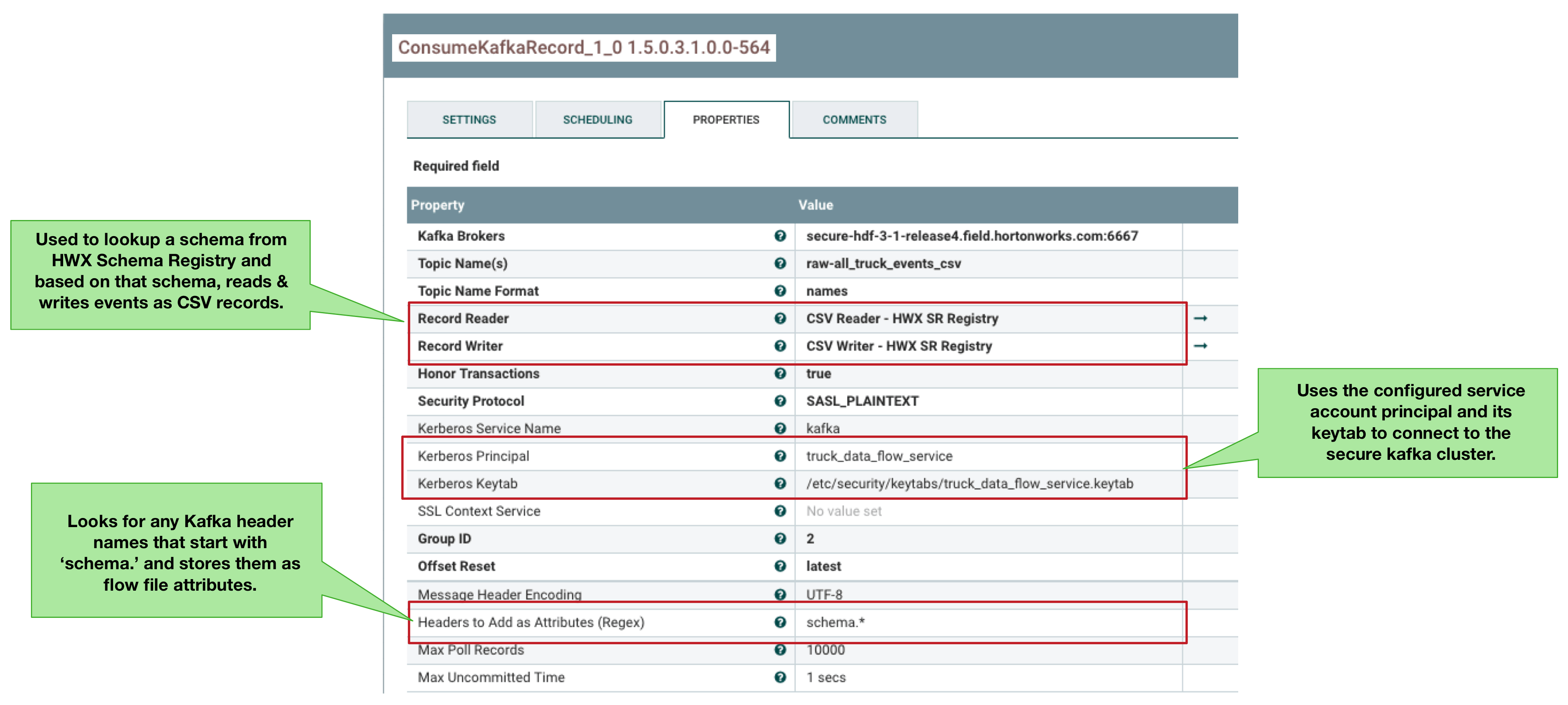
- Connects to a secure kerberized Kafka 1.0 cluster using service account ‘truck_data_flow_service’ with its configured kerberos keytab.
- Consumes events from the topic raw-all_truck_events_avro.
- Looks for any Kafka message headers with names that start with ‘schema.’ and then maps those header values as NiFi flow attributes. The schema identifier from the Kafka message header is now stored as a NiFi flow attribute.
- The configured RecordReader and RecordWriter looks up the schema from the Hortonworks Schema Registry. Using this schema, it creates schema based, record oriented data records for downstream components.
- The ‘Route Telemetry Events’ QueryRecord processor uses SQL to route speed and geo streams to different paths.
- Using the LookUpRecord processor, the geo stream gets enriched with geocode information.
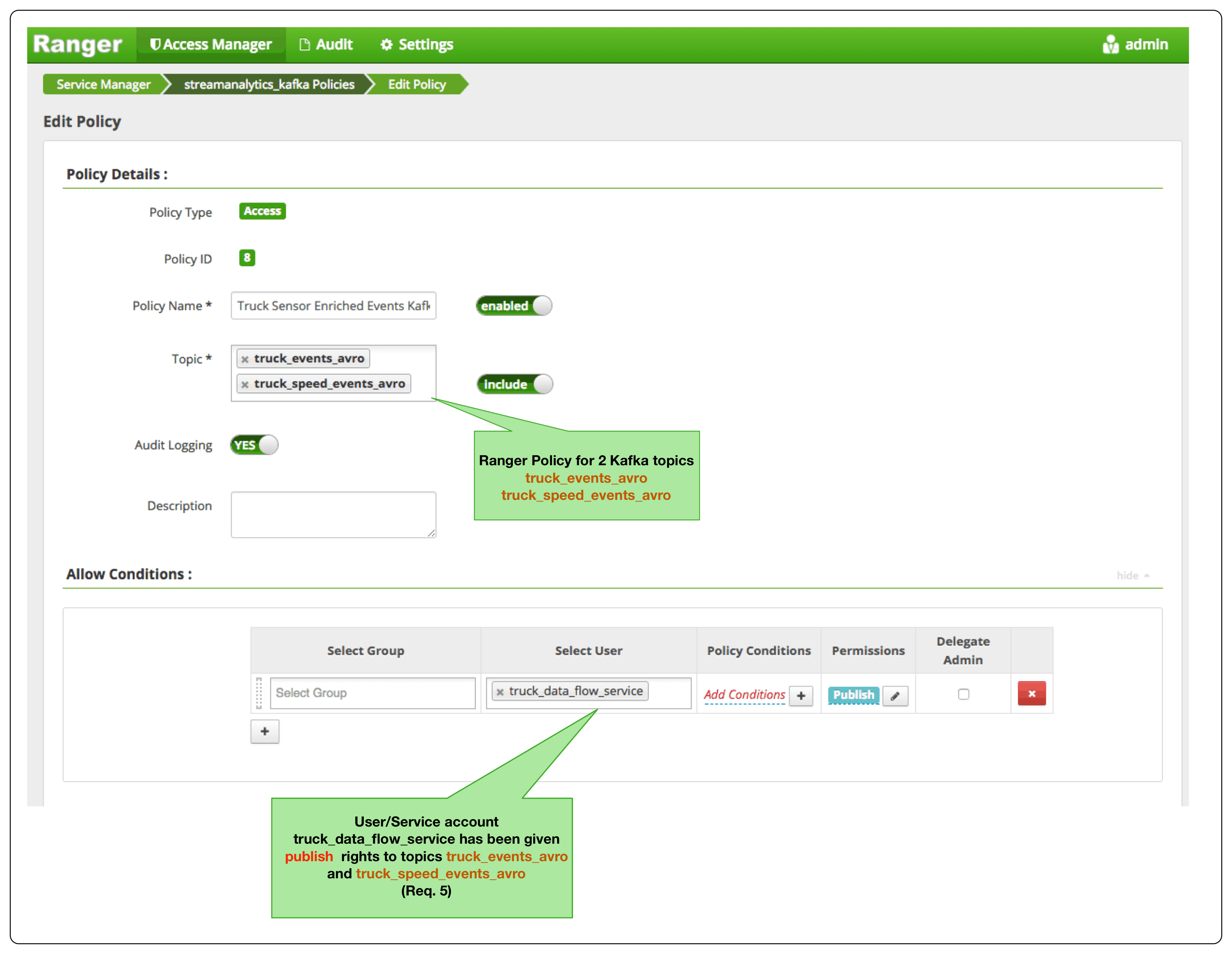
- NiFi’s new Kafka 1.0 PublishKafkaRecord_1_0 processor sends the geo and speed streams to its own respective Kafka topics (Requirement 5). The processor does the following:
- Connects to a secure kerberized Kafka 1.0 cluster using service account ‘truck_data_flow_service’ with its configured kerberos keytab.
- Uses the configured Record Reader and Writer to lookup the schema for the destination Kafka topics and using that schema, converts the csv events into avro.
- Publishes avro formatted events to topic truck_events_avro for geo stream and topic truck_speed_events_avro for speed stream.
- Converts any configured flow file attributes to Kafka message headers.
- Using the new transaction semantics introduced in Kafka .11, it sends all the events in a flowfile to kafka topic in a single transaction. If an event in the flowfile fails, all other published events to kafka within the transaction is rolled back.
Requirement 6 is about agility and self service. Working with our large customer base, the single most asked feature centers around the following question:
“How can we make our app-dev and dev-ops teams more agile? We need them to deliver features faster to the Business.”
As the above diagram illustrates, NiFi’s key value proposition is enabling developers to build complex flow apps faster. With NiFi’s Kafka 1.0 support, Kafka centric requirements like 1 through 5 can be implemented very quickly without having to write a lot of code.
The following show the configuration of the ConsumeKafkaRecord and PublishKafkaRecord processor that make this possible.
Security and Audit Kafka Requirements

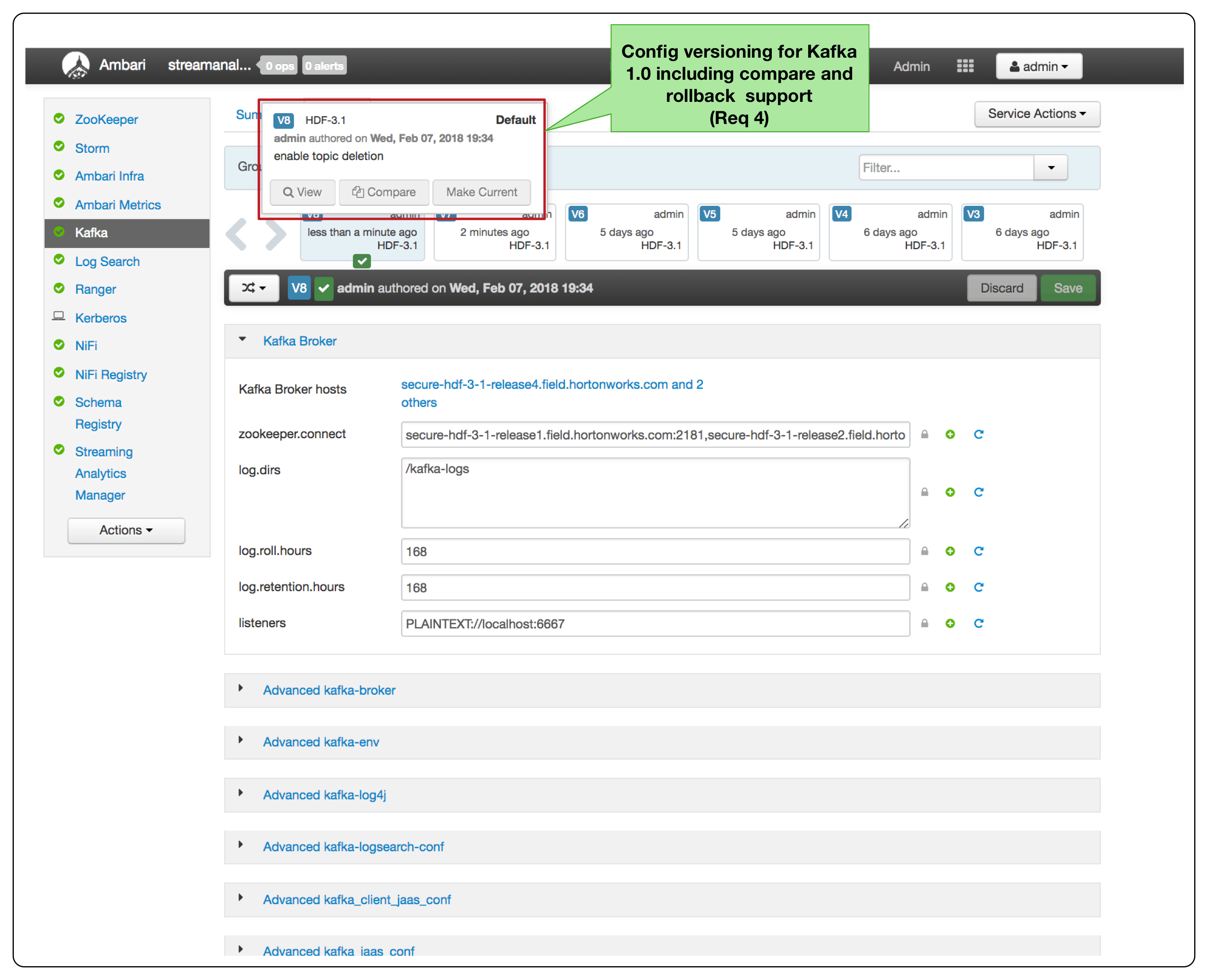
Implementing Kafka Security and Audit Requirements with Apache Ranger and Ambari
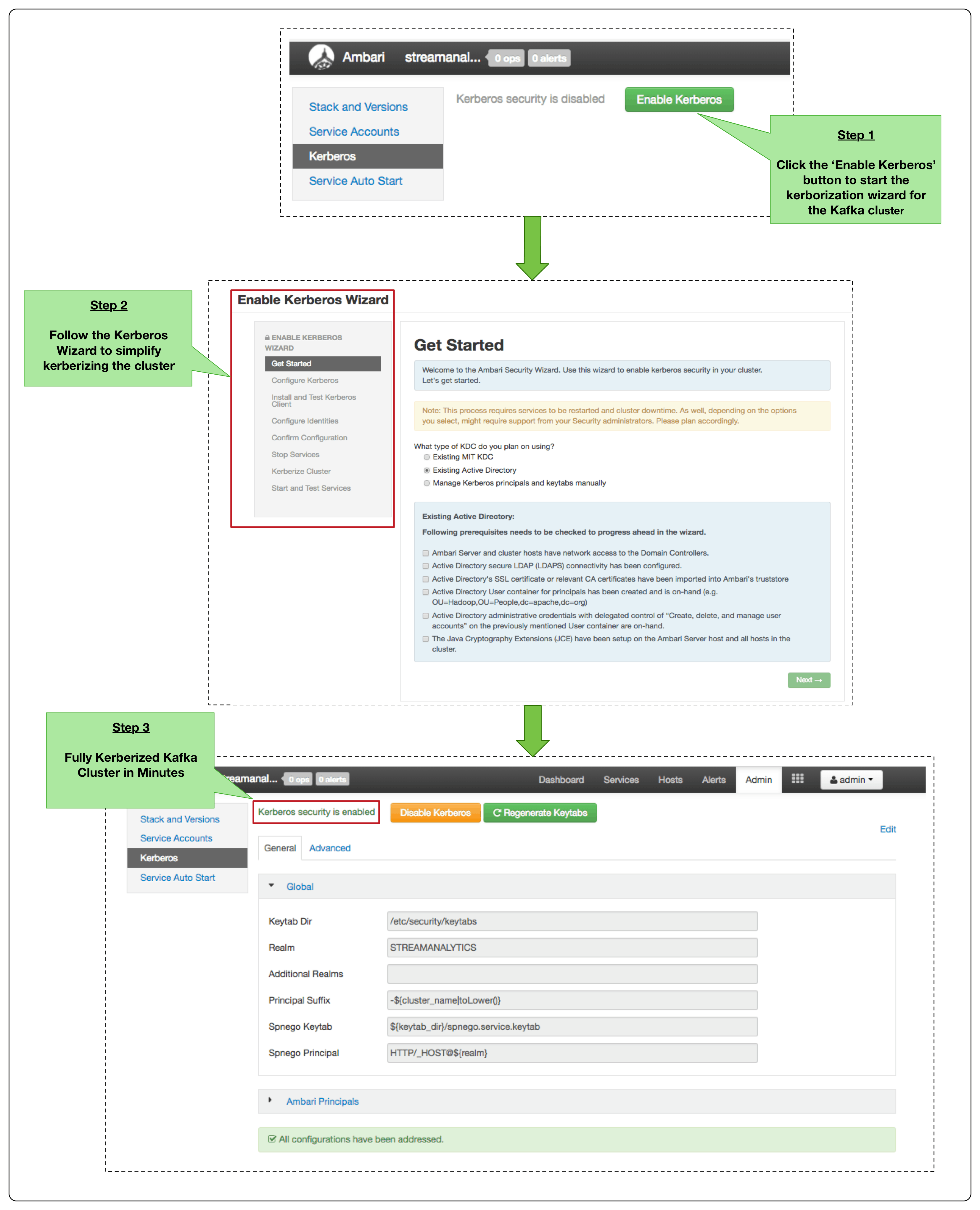
A majority of our customers’ Kafka production deployments are Kerberized with AD integration to support their enterprise security requirements. Apache Ambari makes this painful kerberization process considerably easier. Ambari provides a kerberization wizard that automates all of the details required to kerberize a multi-node Kafka cluster. See the following diagram for more details about how Req 1 is implemented via Ambari.
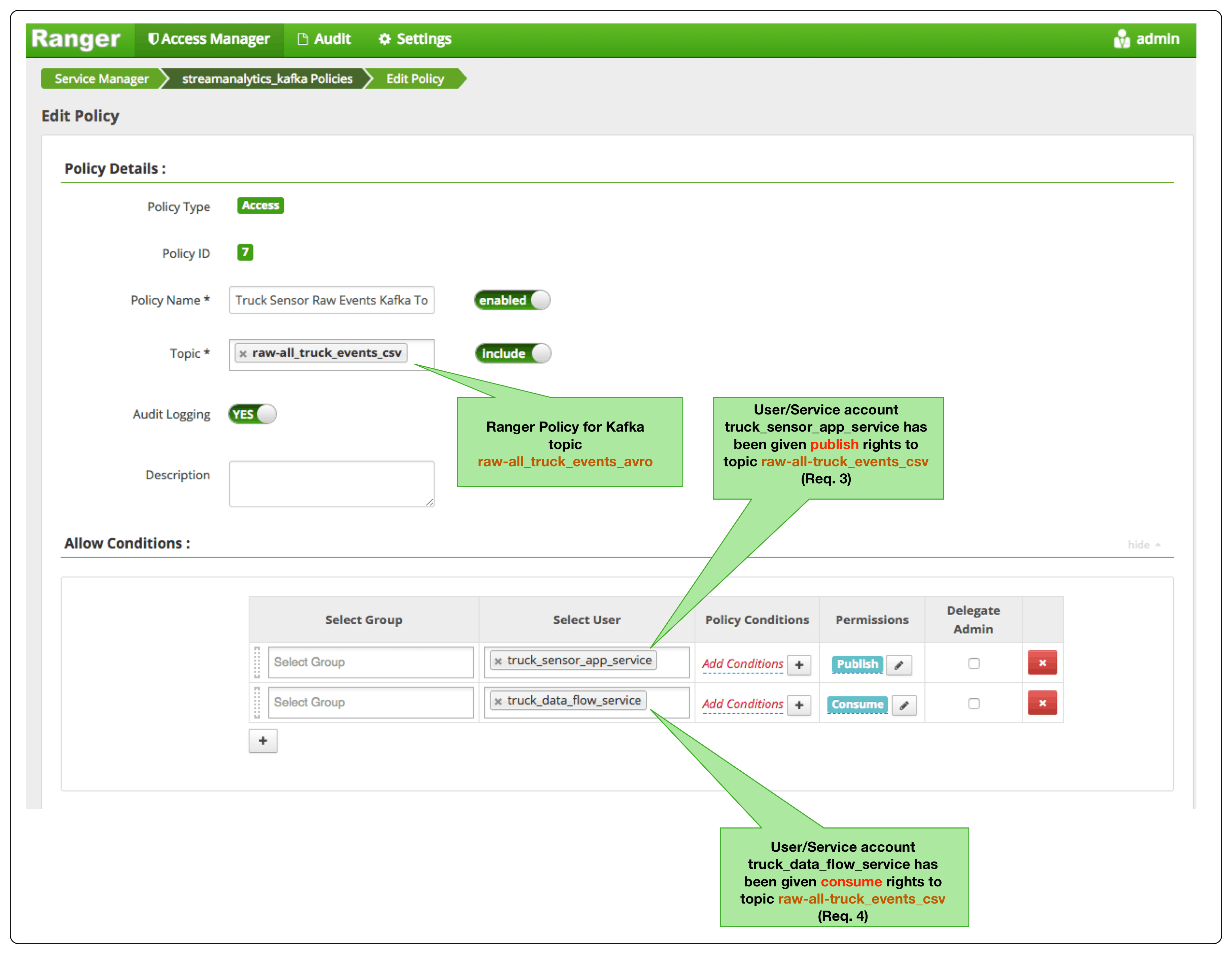
Apache Ranger is another key component of the enterprise services that power HDF. Ranger provides a centralized platform to define, administer and manage security policies for Kafka. A majority of our customers use Ranger to meet requirement 2 as well as the access control rules described in requirements 3 through 5. The below diagram illustrates these ACL requirements.
The following illustrates how to implement ACL policies for requirements 3, 4 and 5.
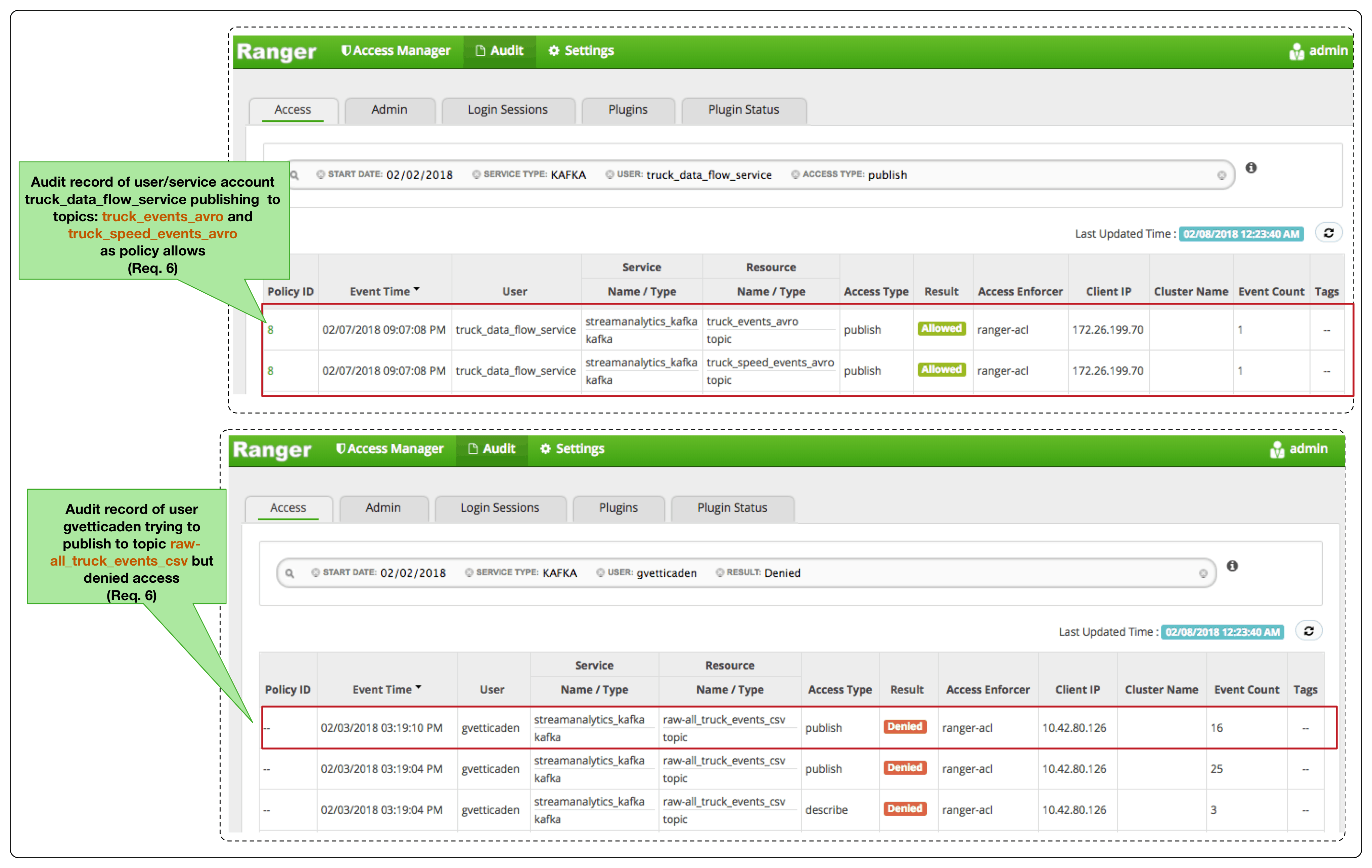
 Ranger, in addition to providing a centralized policy store, also provides comprehensive audit services that captures and indexes all authorized/unauthorized access to Kafka resources. With Ranger, the audit requirement 6 can be met as the following shows.
Ranger, in addition to providing a centralized policy store, also provides comprehensive audit services that captures and indexes all authorized/unauthorized access to Kafka resources. With Ranger, the audit requirement 6 can be met as the following shows.
Platform/Operation Kafka Requirements

Implementing Platform Requirements with Ambari
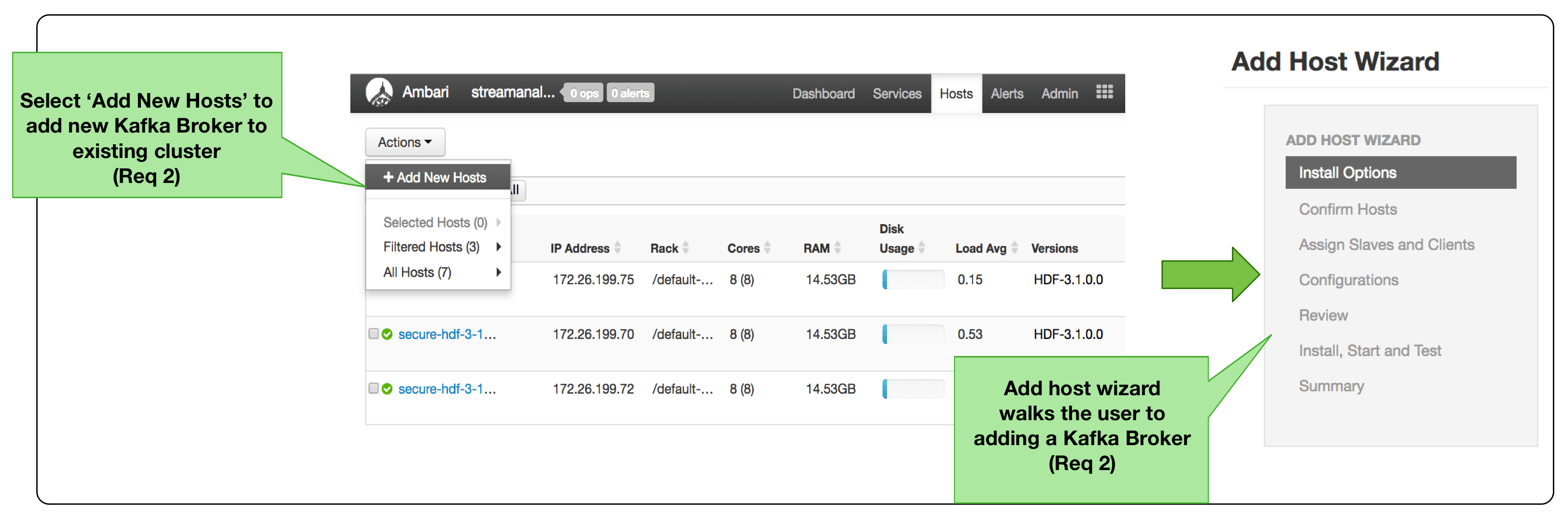
Apache Ambari, which is part of HDF enterprise management services, provides all the capabilities to fulfill requirements 1 through 8 above. The following shows Ambari meeting Req 1 and 2.
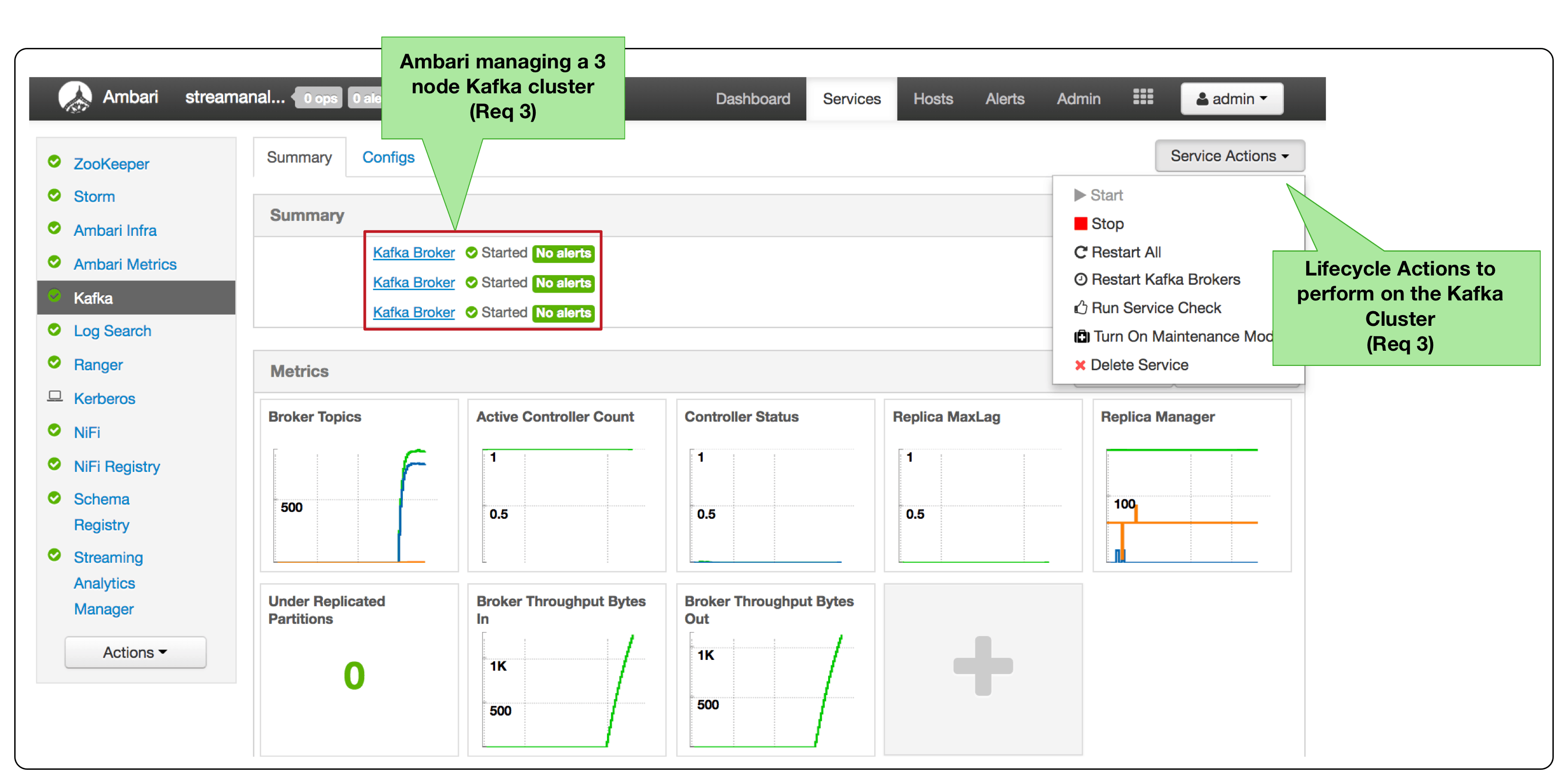
The following shows Ambari meeting Req 3 and 4.
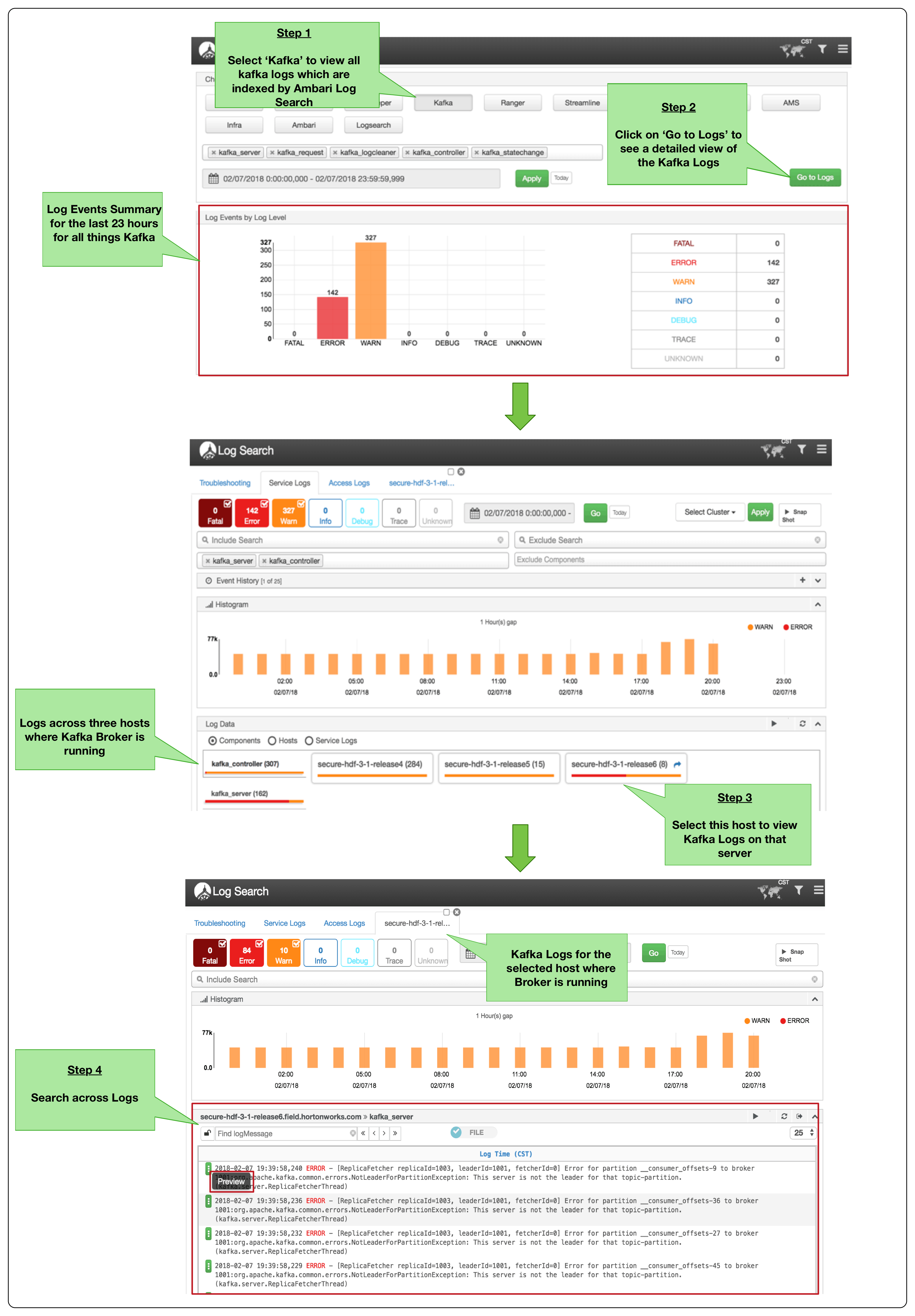
The diagram below shows using Ambari Log Search to meet the search requirement 5.
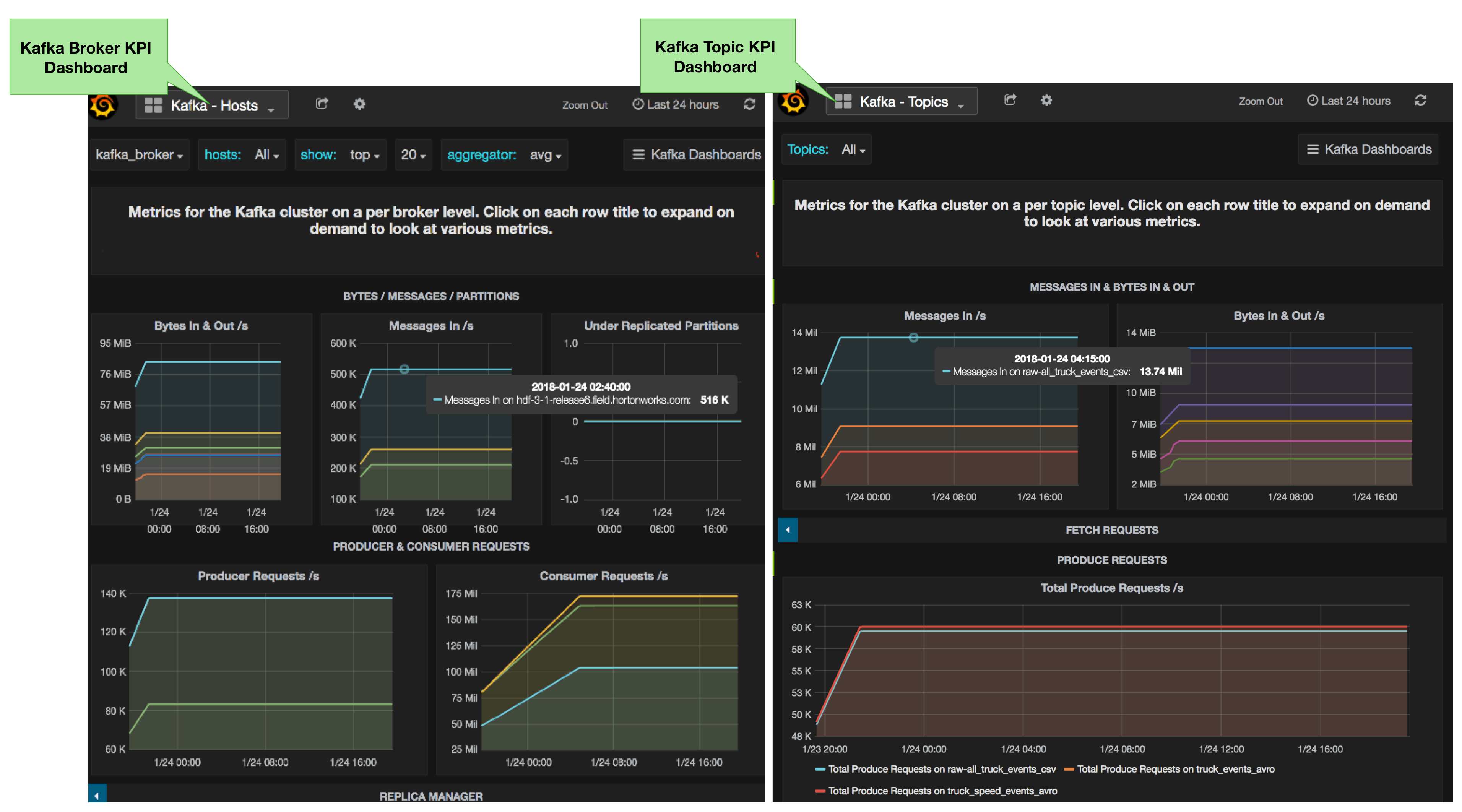
Apache Ambari and its integration with Grafana and the Metrics Server(AMS) provides critical monitoring and alerting for Kafka clusters. Ambari provides three custom Grafana dashboards that provides broker and topic level KPMs for Kafka 1.0 clusters as the below diagram illustrates.
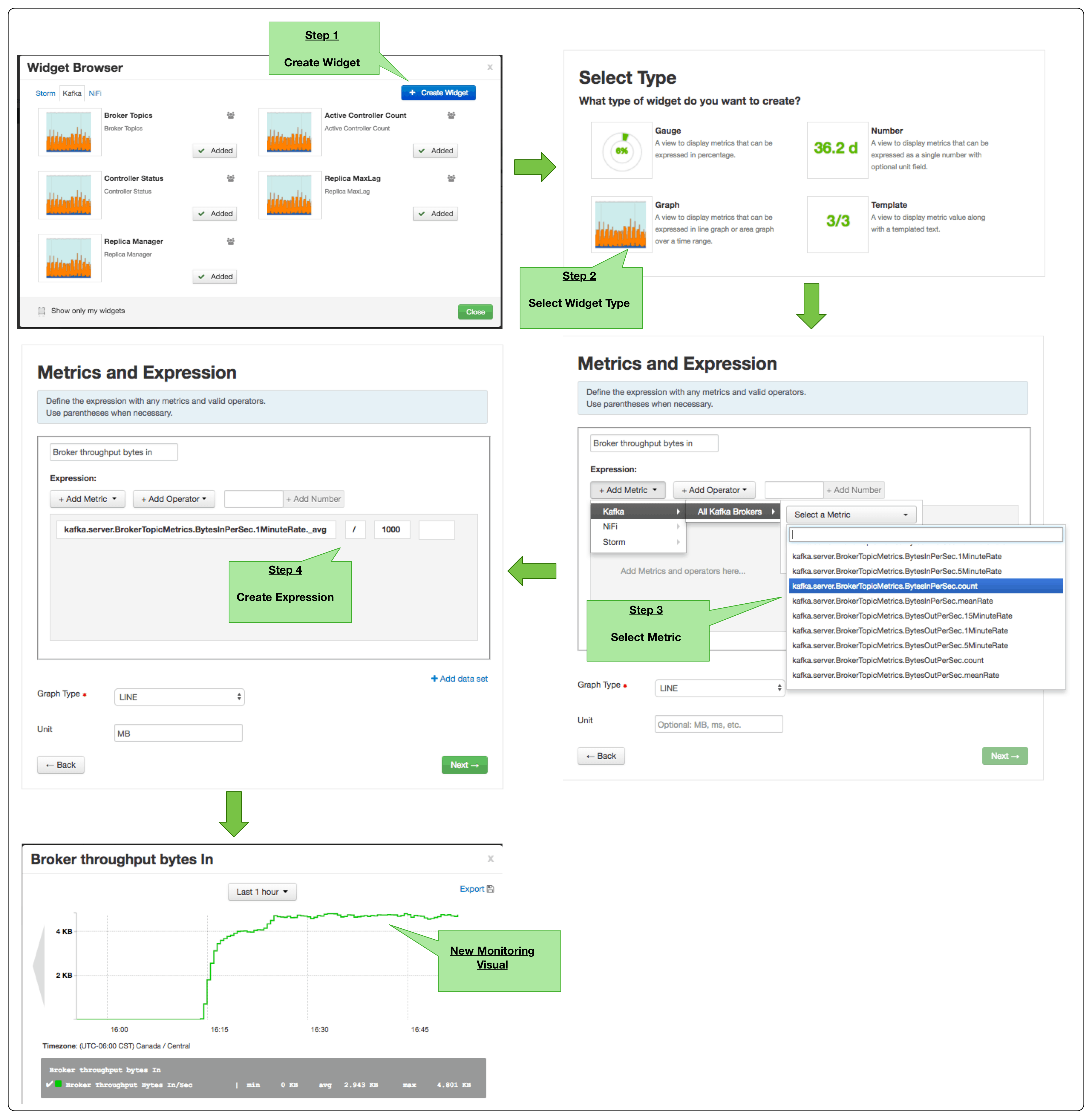
Ambari also supports creating custom visualization widgets based on Kafka JMX metrics.
From these KPM metrics, the user is able to create custom alerts in Ambari. The below shows the alert definition to determine if Kafka process is up/down.
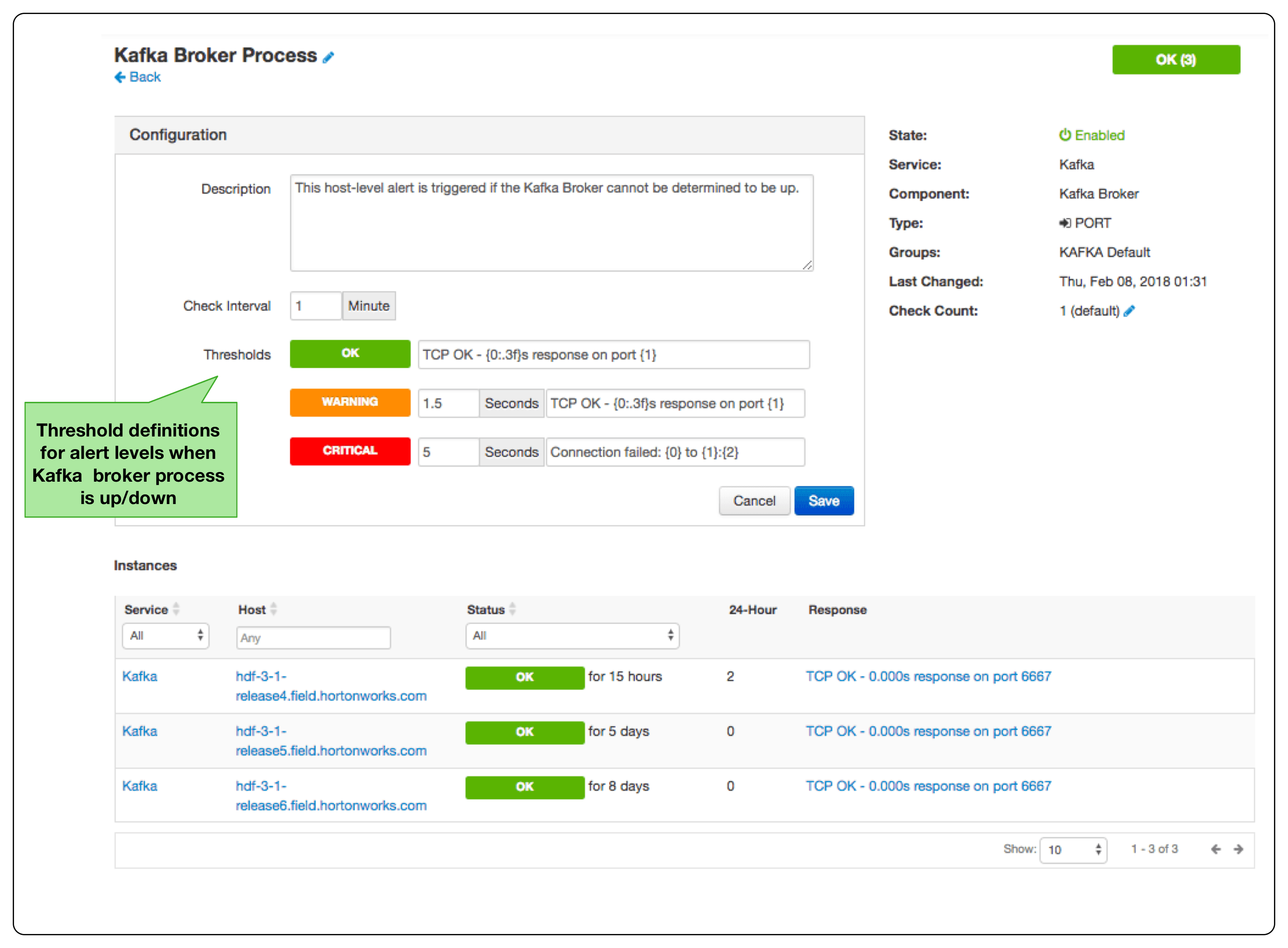
Ambari supports rolling upgrades of Kafka when upgrading from HDF 3.0 to HDF 3.1. This means that the user can upgrade Kafka 0.10.X to Kafka 1.0 without incurring any downtime using Ambari’s rolling upgrade capability.
In Summary and Whats Next?
As we have shown in detail, HDF 3.1 with Kafka 1.0 support and the powerful HDF integrations helps customers meet the enterprise requirements from the app-dev, operations/platform and security teams.

Stay tuned next week as we continue the HDF 3.1 Blog series and discuss topics around testing, continuous integration/ delivery and stream operations.
Interested in discussing further?
Join us for our HDF 3.1 webinar series where we dig deeper into the features with the Hortonworks product team. Redefining Data-in-Motion with Modern Data Architectures.
Editor's Choice

