

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
If data is the new bacon, data stewardship supplies its nutrition label!
This is the second part of a two-part blog introducing Data Steward Studio (DSS) which covers a detailed walkthrough of the capabilities in Data Steward Studio
With GDPR coming into effect in May 2018 and California legislature signing California Consumer Privacy Act of 2018 (CCPA) that grants California residents a broad range of rights similar to what GDPR requires when it comes to their personal information (PI), businesses need comprehensive solutions in order to understand how personal data flows through their systems and processes. For example, they need to be able to provide chain of custody information, inventory and classify data assets, secure access to personal data and monitor usage of such data. Having a comprehensive data inventory, managing trust and veracity of data, and proving that businesses have appropriate operational controls and safeguards for processing sensitive data have become paramount in the increasingly complex hybrid and multi-cloud enterprise data universe.
In April, we unveiled Data Steward Studio (DSS) at DataWorks Summit in Berlin which addresses several key areas of data management challenges faced by enterprises that are extremely relevant to hybrid data management under the regime of such new regulations. DSS has been released and is generally available to Hortonworks customers since May 2018 and is the second service to be generally available on the DPS platform. DSS addresses many key data management challenges faced by enterprises today:
- Proliferation of data types and sources
- Expensive and time-consuming process of discovery, organization, and curation of data,
- Need to gain global visibility of business context, usage, and trustworthiness of data
- Need to centralize data and metadata security controls and access monitoring
In this blog we will walk you through the key features of DSS that empower businesses to understand the data and get a comprehensive view of their data in their hybrid data lake environments. DSS empowers enterprises to precisely identify and evaluate trust levels of their data, to collaborate securely, and to democratize data across the enterprise confidently so that they can derive value from the data in their data lakes – whether these data lakes are located in on-premise data centers or in the cloud or across multiple cloud provider environments.
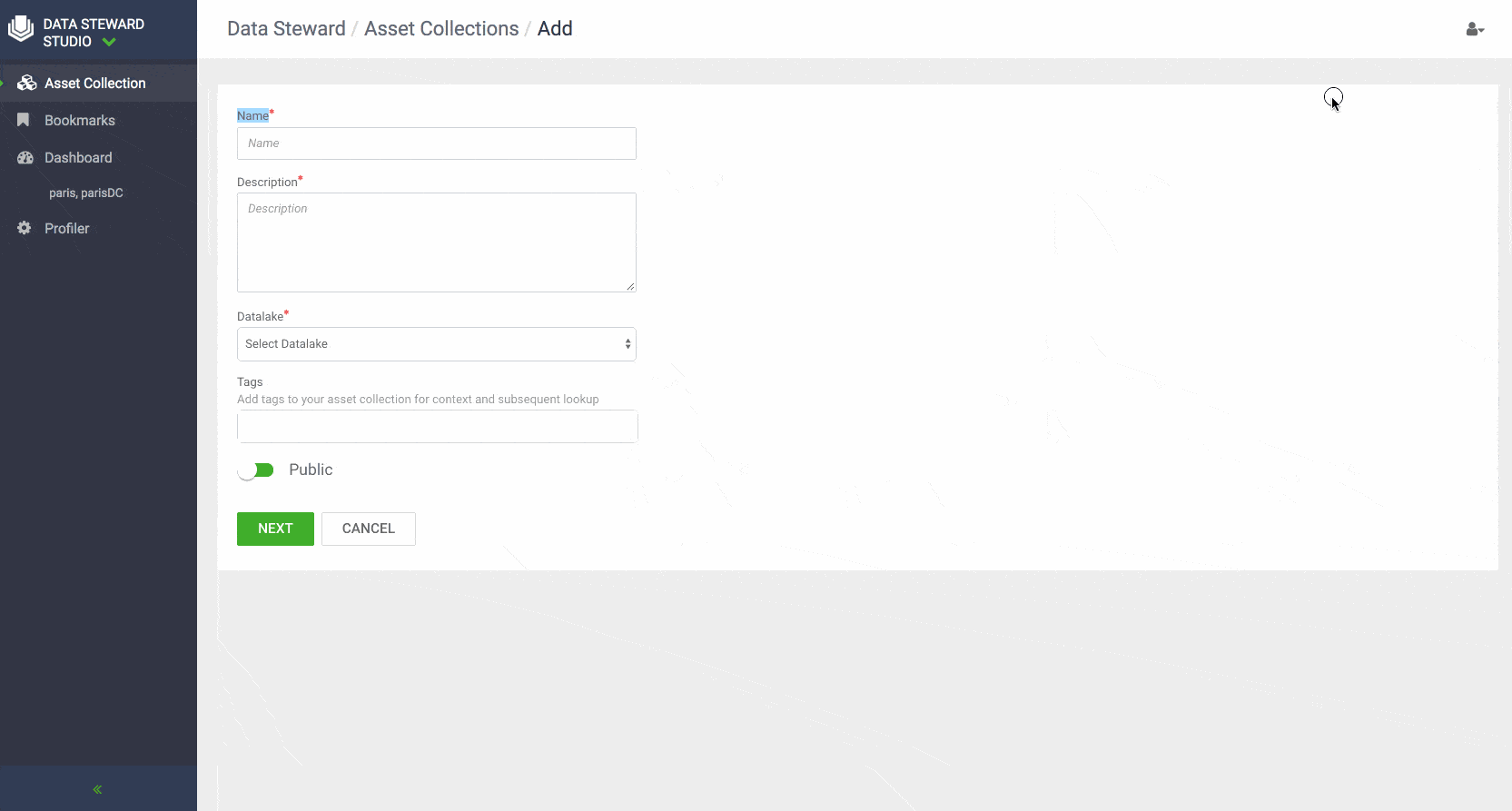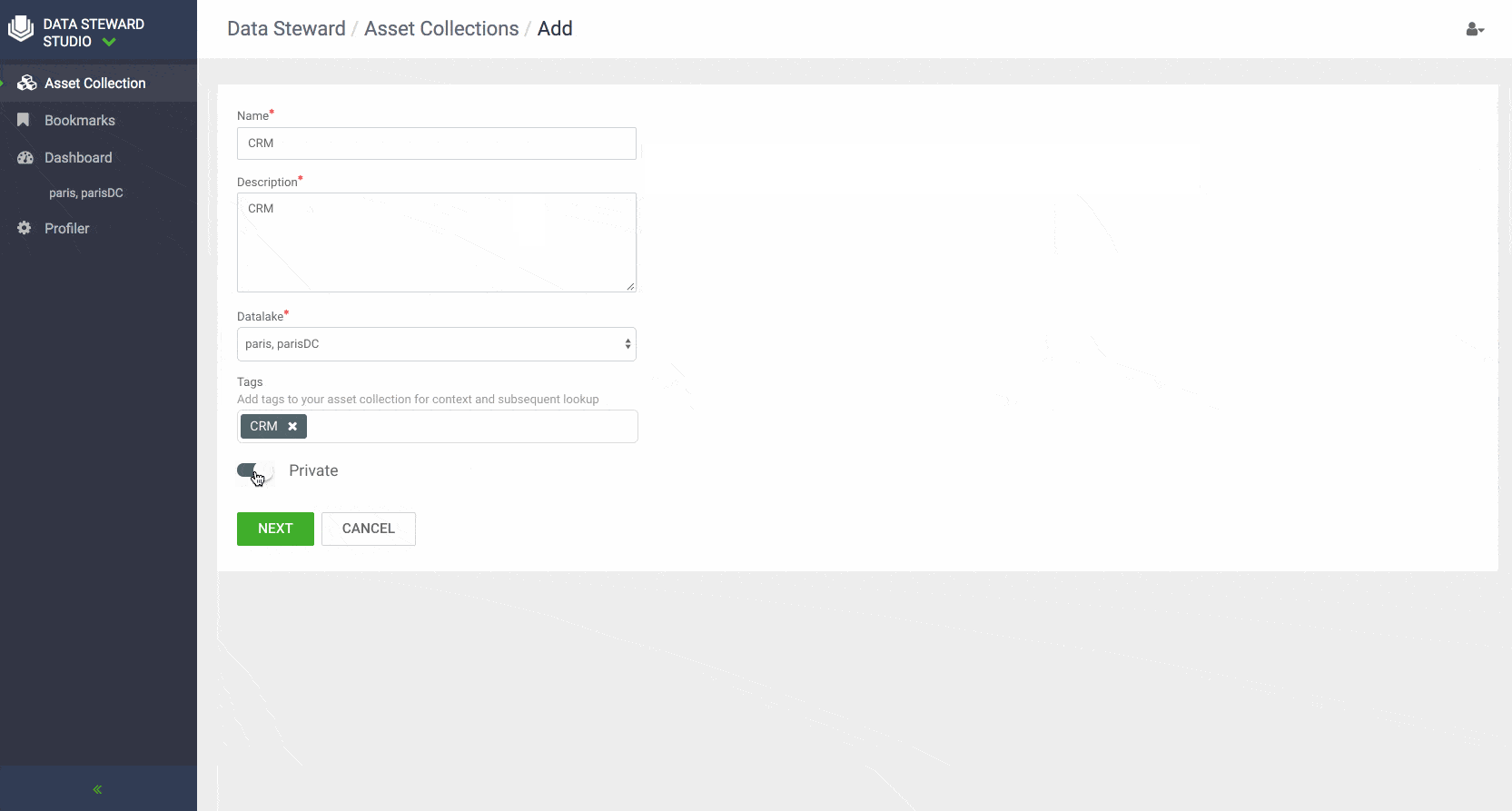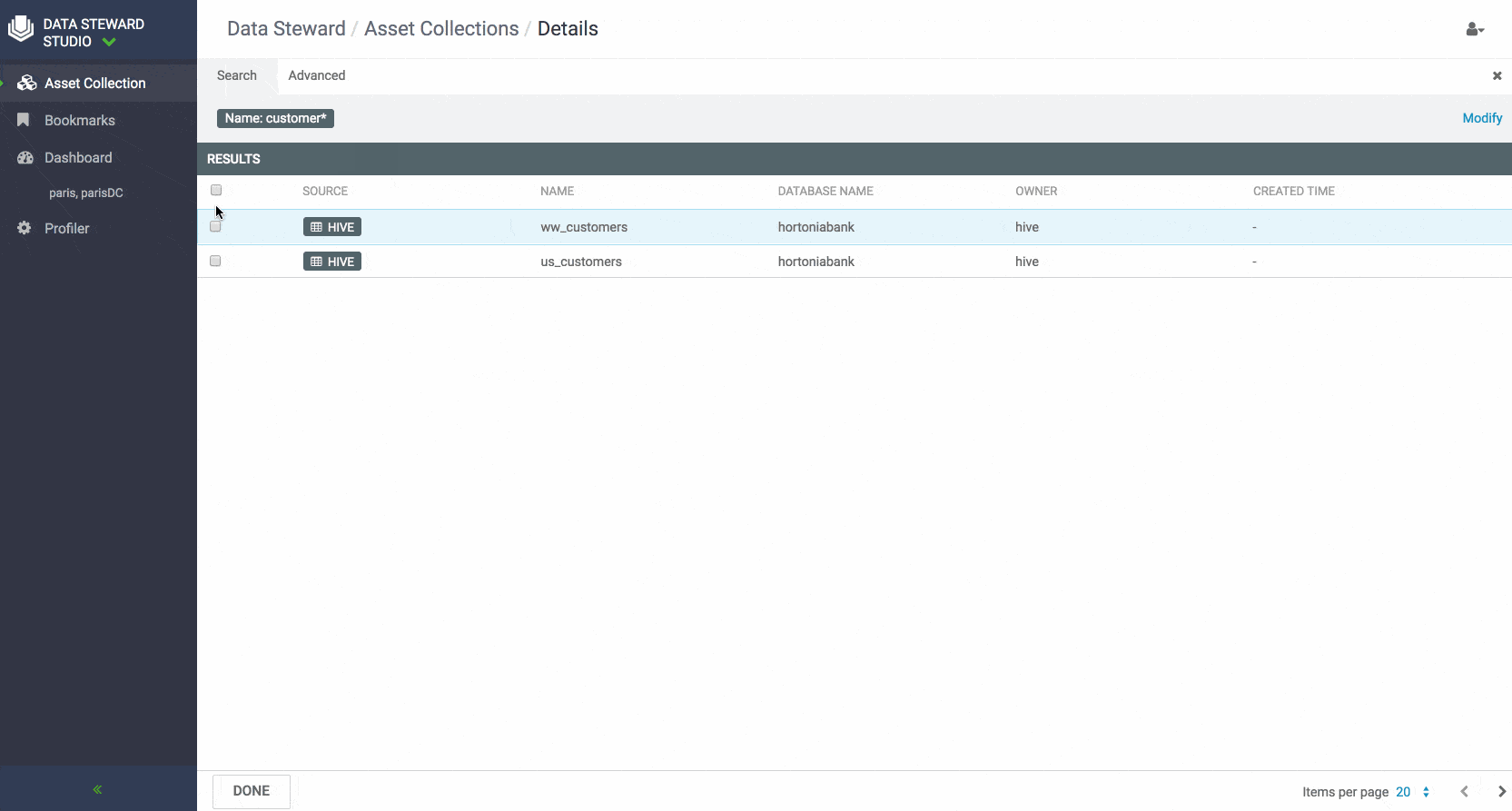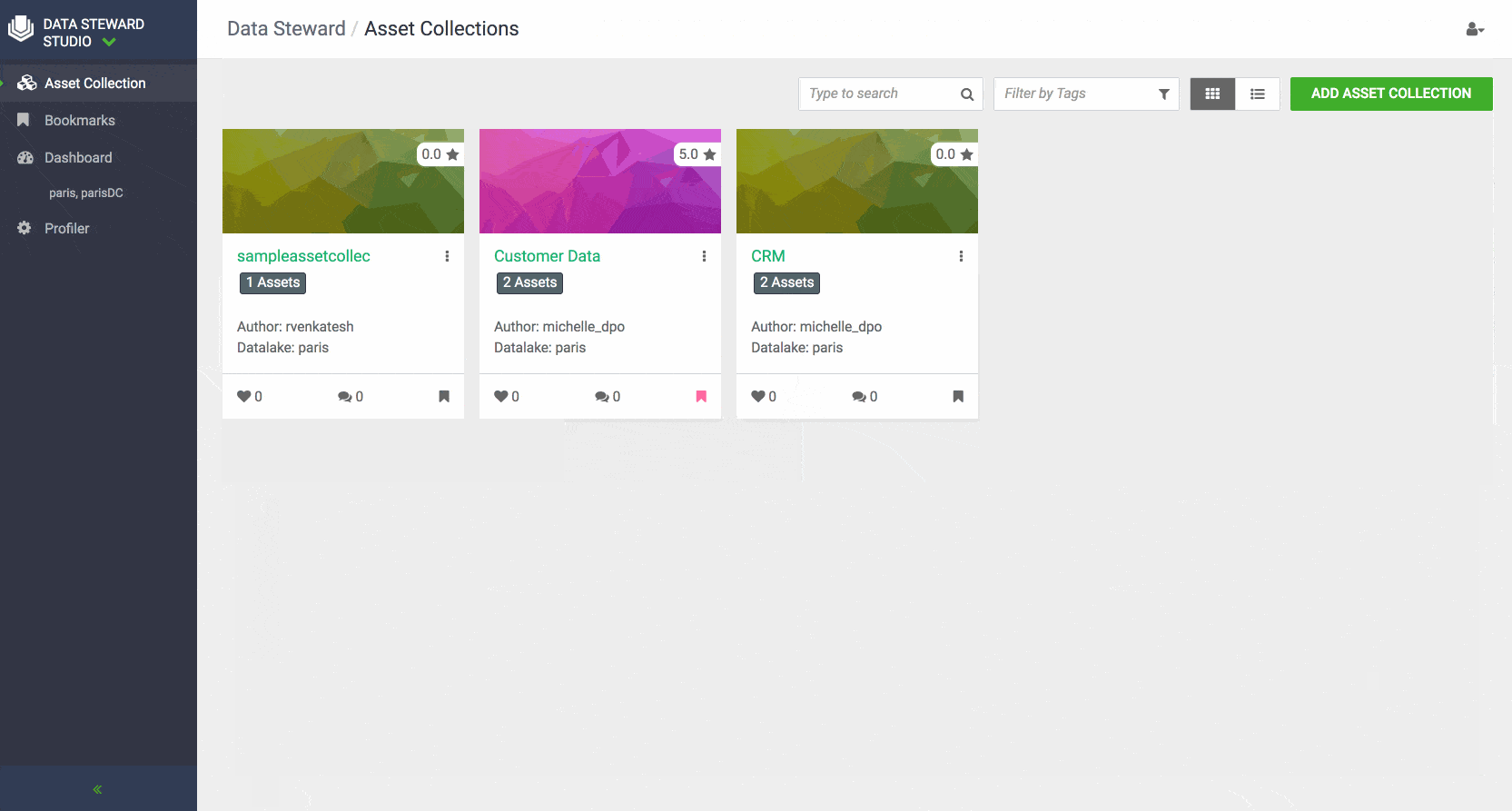
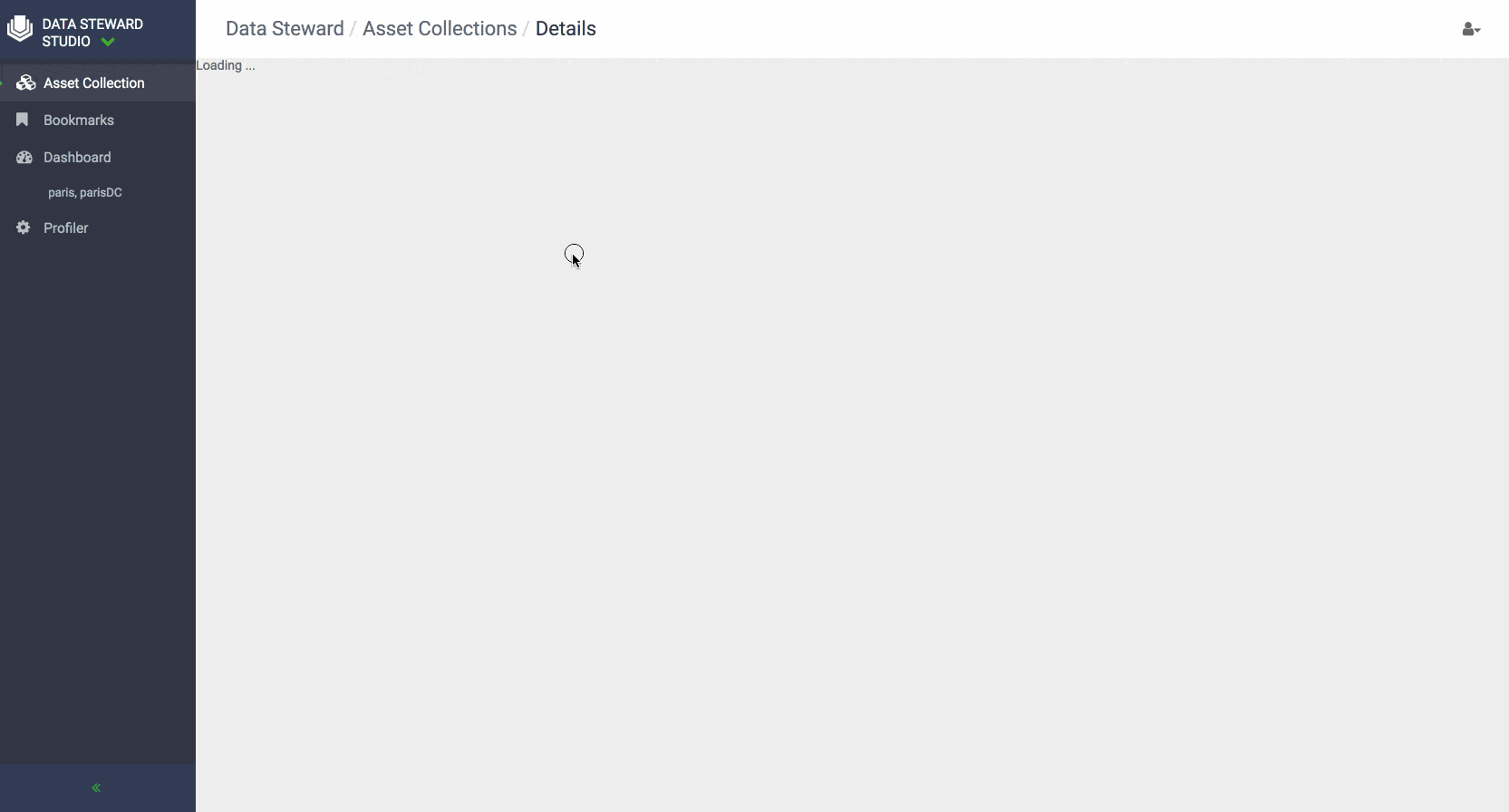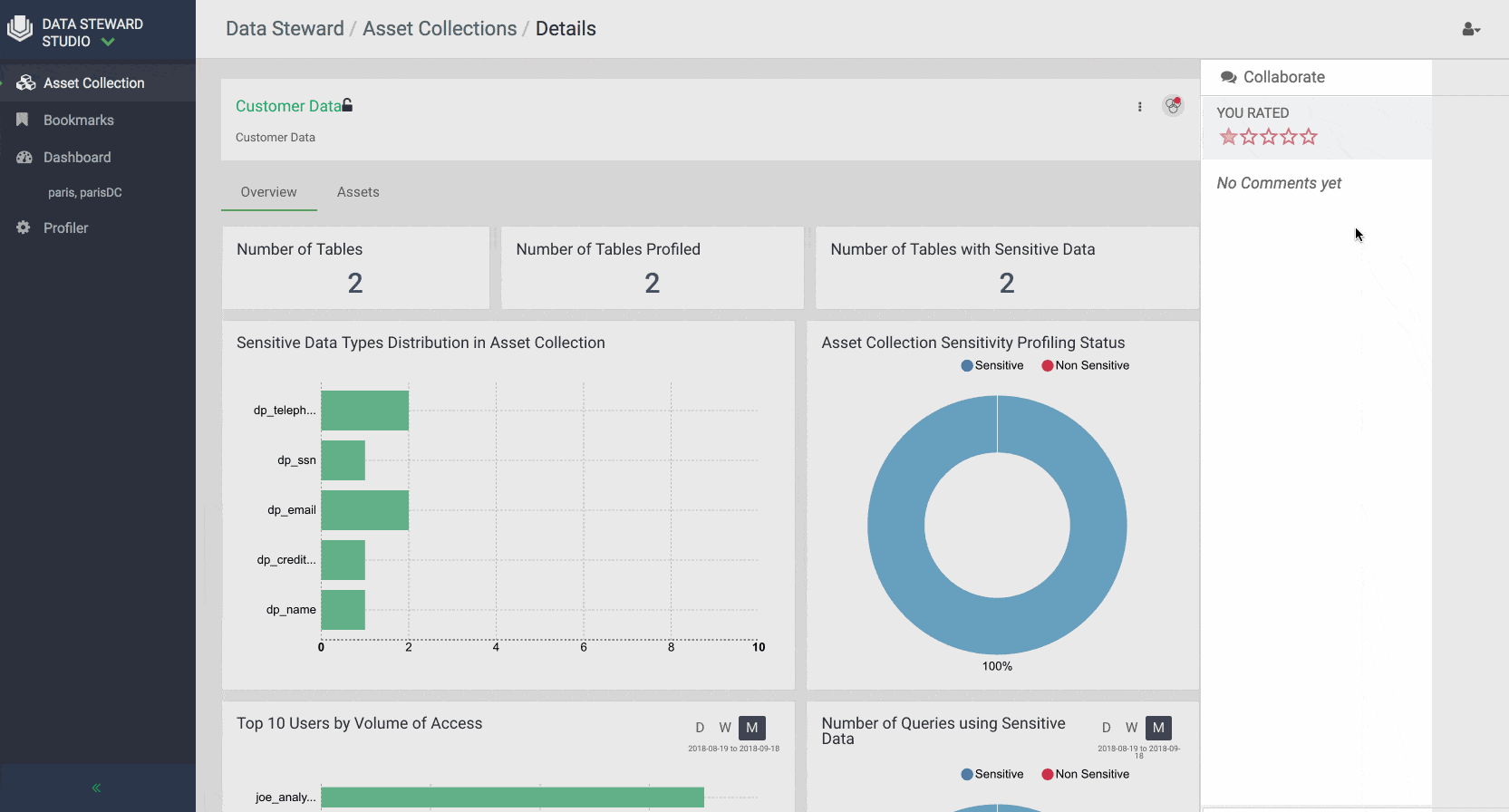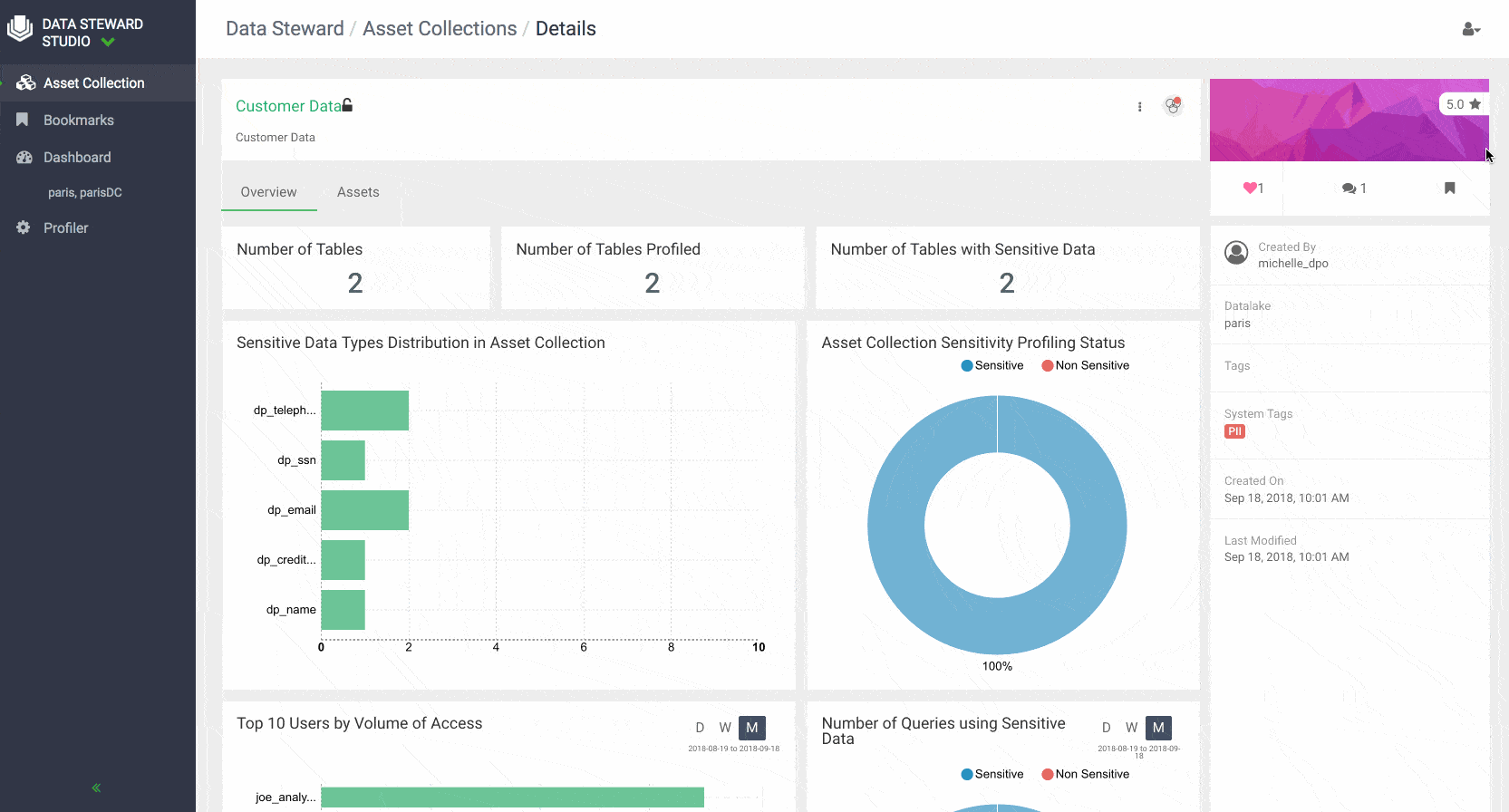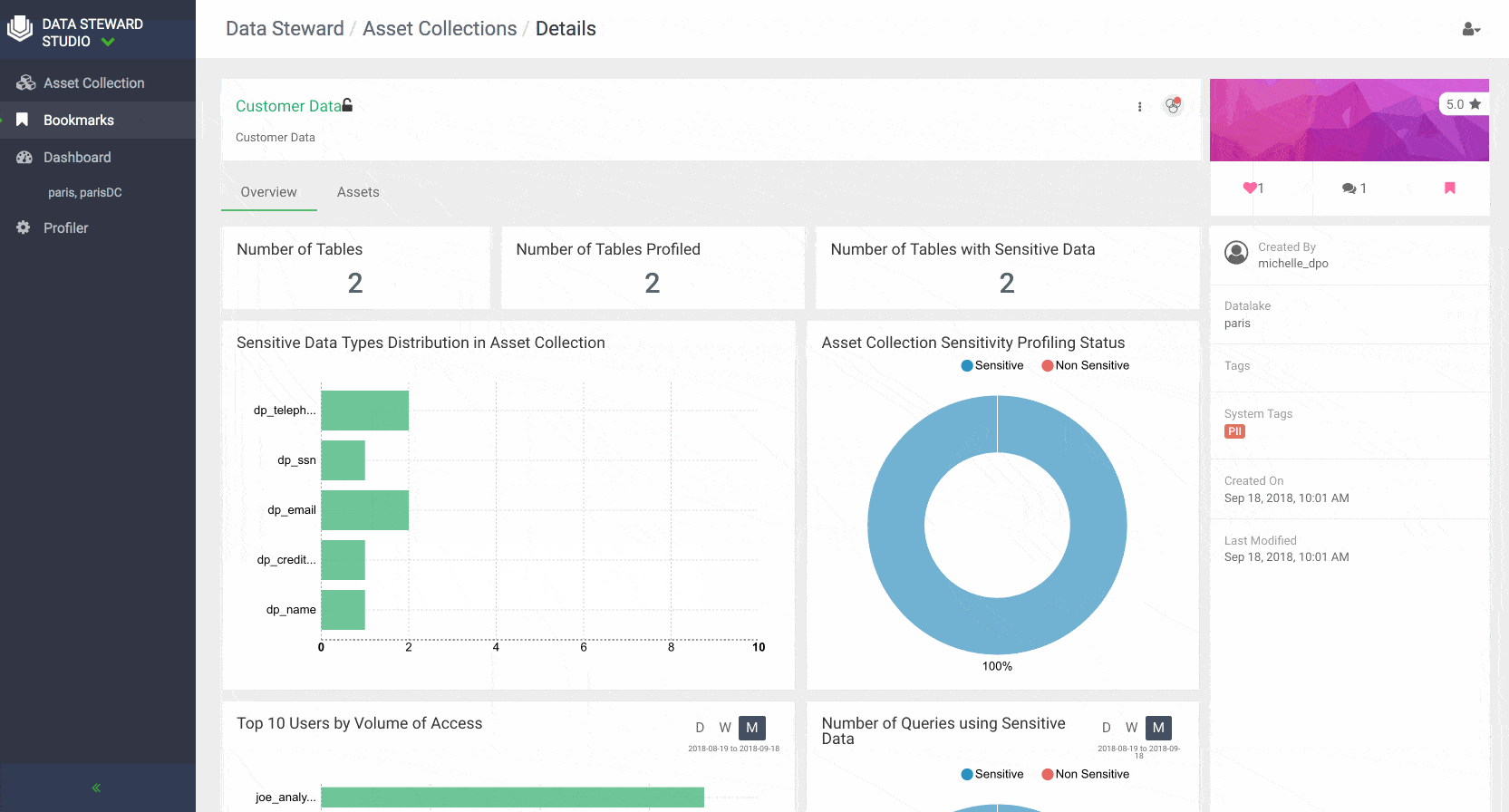
- Asset Collection: To ease management and administration of data assets, DSS enables data consumers and stewards to create flexible grouping of data using the concept of Asset Collections. Asset Collection is a data organization construct designed to group heterogenous data assets in the form of a curated list based on a business definition. For example, Asset Collections can be created based on categories such as customer profiles, sales assets, financials, PII, and HR data.
Data stewards can create Asset Collections by filtering and selecting data assets in their data lakes with metadata using either contextual attributes such as name, description, owner, data lake or system attributes such as version, date on which asset was created or modified or the person who created or modified the data asset. Business users and data stewards can also search for assets using above-mentioned attributes or free text, view personalized dashboard and delete/ update data asset collections.
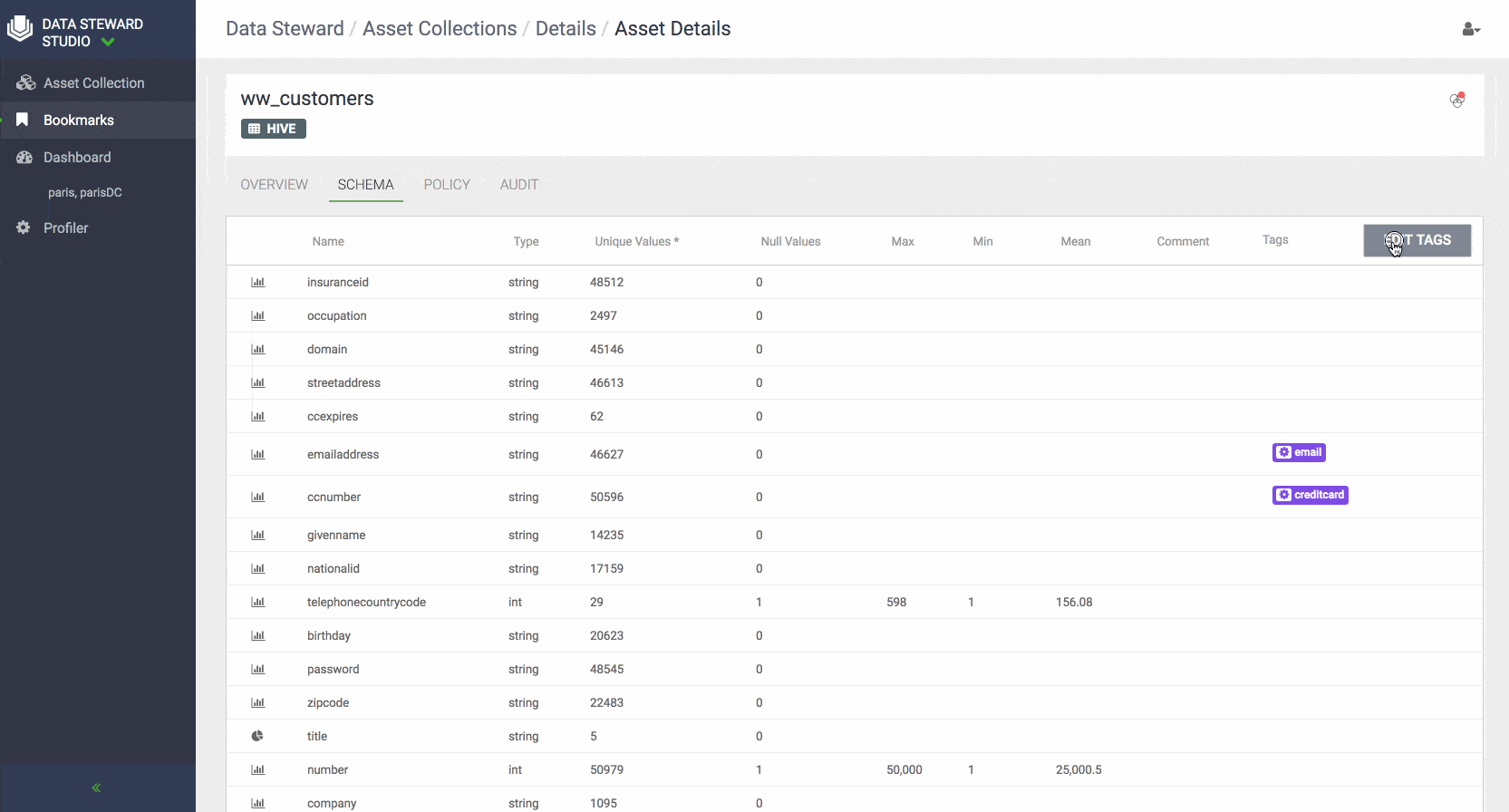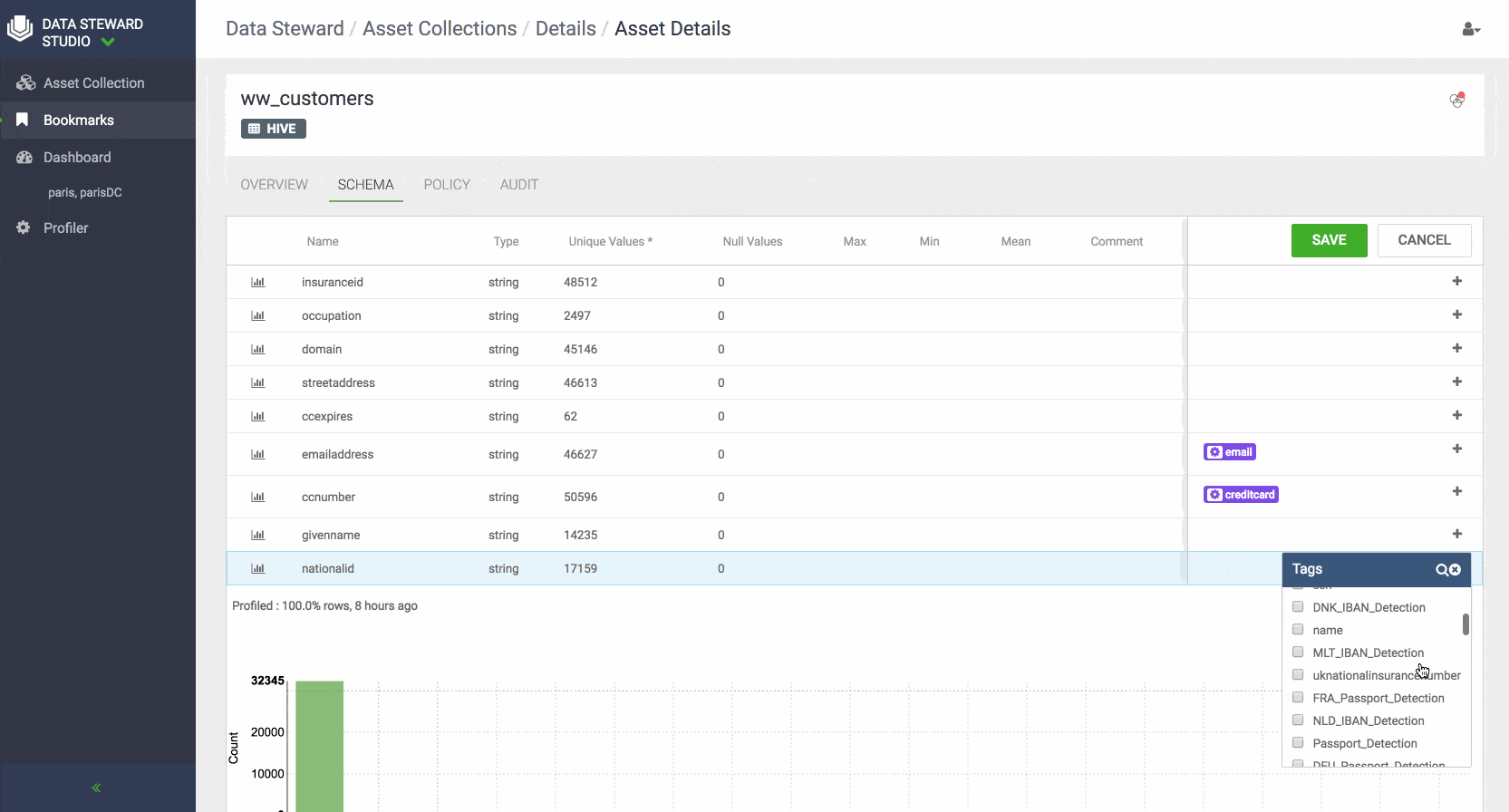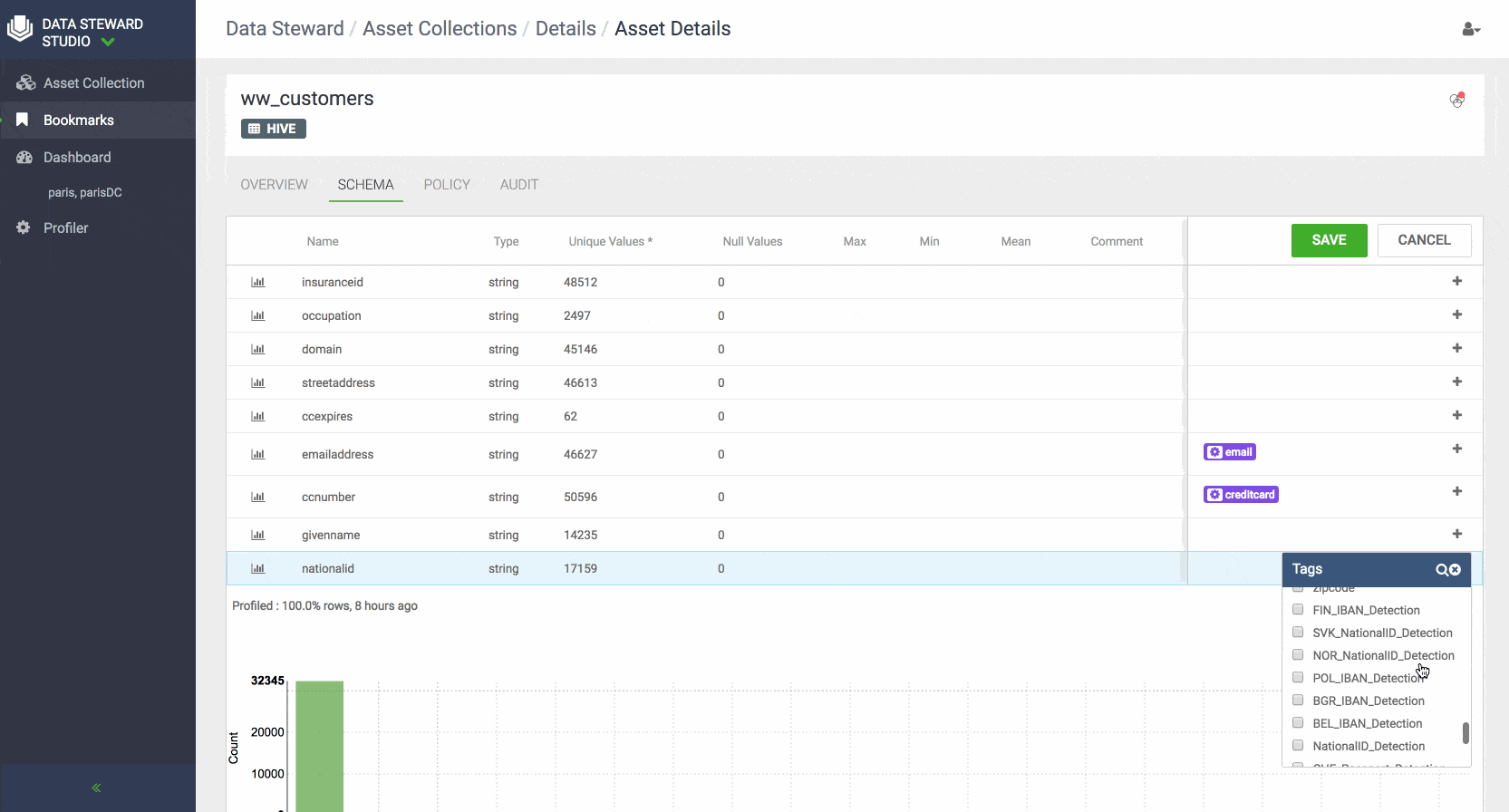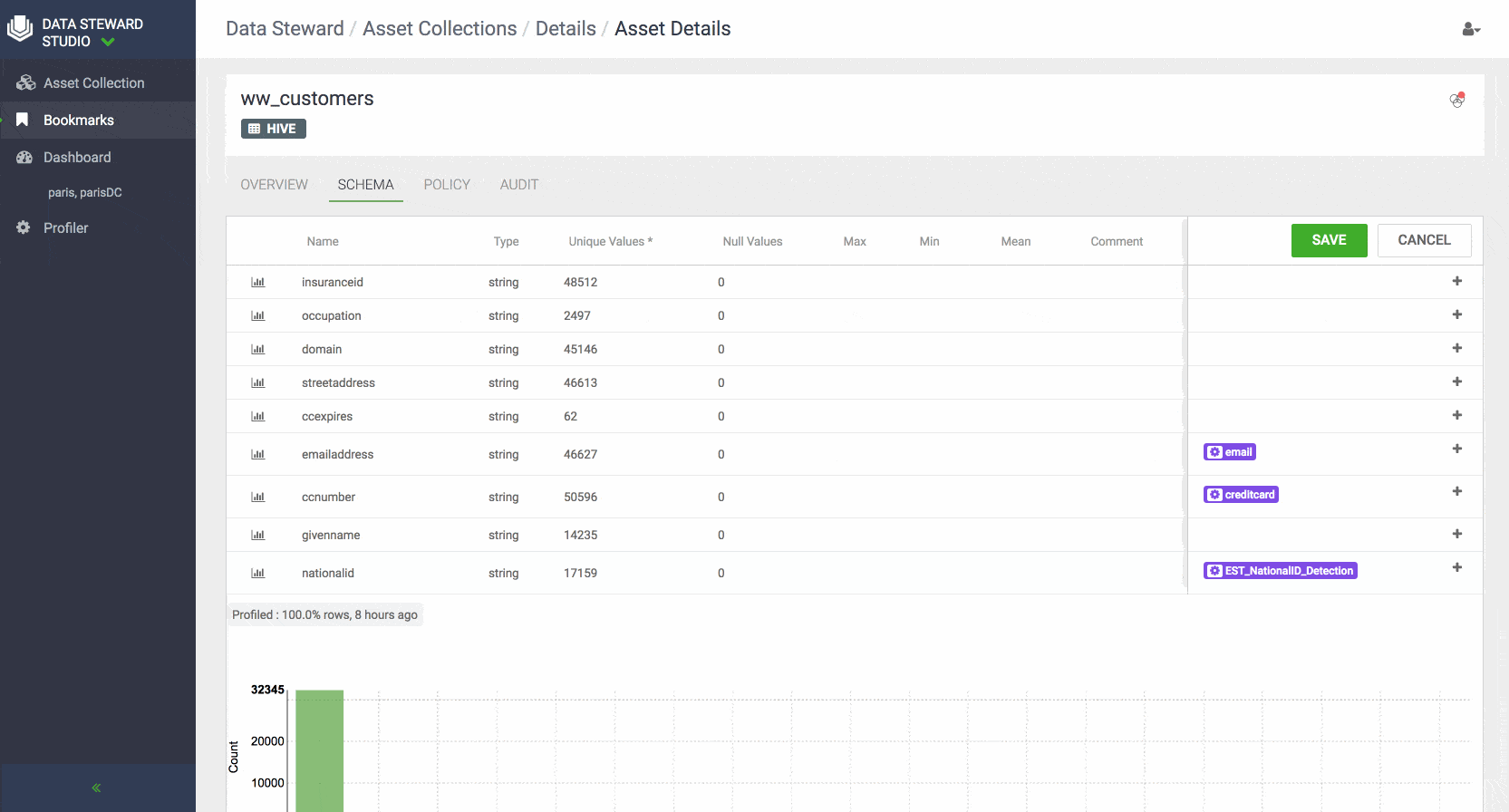
- Built-in Data Profilers: With DSS, personal or sensitive data can be easily discovered and tagged so that it can be classified and searched by data consumers such as business analysts and data scientists. DSS includes a robust, scalable, and extensible data profiler framework based on Apache Spark that can be easily customized and extended to create a pipeline of content and metadata profiling operations on data located across multiple data lakes. With a focus on automation, DSS features four out-of-the-box profilers that can be run at scale leveraging Apache Spark technology. Customers can install the profiler agent in a data lake and set up a specific schedule to generate various types of data profiles that summarize, classify, and provide information about sensitivity and statistical summaries that include distribution of values, cardinality, completeness, and shape of data. Data profilers generate metadata annotations on the assets for various purposes that are persisted locally on the data lake either in Apache Atlas or locally in HDFS. DSS pre-built profilers include:
- Sensitive Data Profiler (SDP) automatically inspects context and content to detect various types of sensitive data elements via pattern matching and basic machine learning/NLP techniques and suggest suitable classifications or tags based on the type of sensitive content detected or discovered. DSS profilers can detect over 75 sensitive data types including:
- IBAN numbers (27 EU Countries)
- Credit Card Numbers
- Passport (12 EU Countries)
- Telephone (EU, AMER)
- Swift code
- IP Address
- URL
- National ID (19 EU countries)
- Australian Drivers License
- Australian Passport
- Australian National ID
- Ranger Audit Profiler enables administrators to view who has accessed which data from a forensic audit or compliance perspective, visualize access patterns, and identify anomalies in access patterns.
- Asset 360 Page: Asset 360 page in DSS provides all the metadata associated with a particular data asset. The Asset 360 can be thought of as a Facebook page for a particular data asset. This information within the Asset 360 Page is organized in four tabs:
- Hive Column Statistical Profiler enables users to view the shape or distribution characteristics of the columnar data within a Hive table.
- Hive Metastore Profiler scans the Hive Metastore to retrieves information about the number of hive tables that have been added, computes the number of partitions, and finds values like time created, size, number of rows, input format, output format, etc.
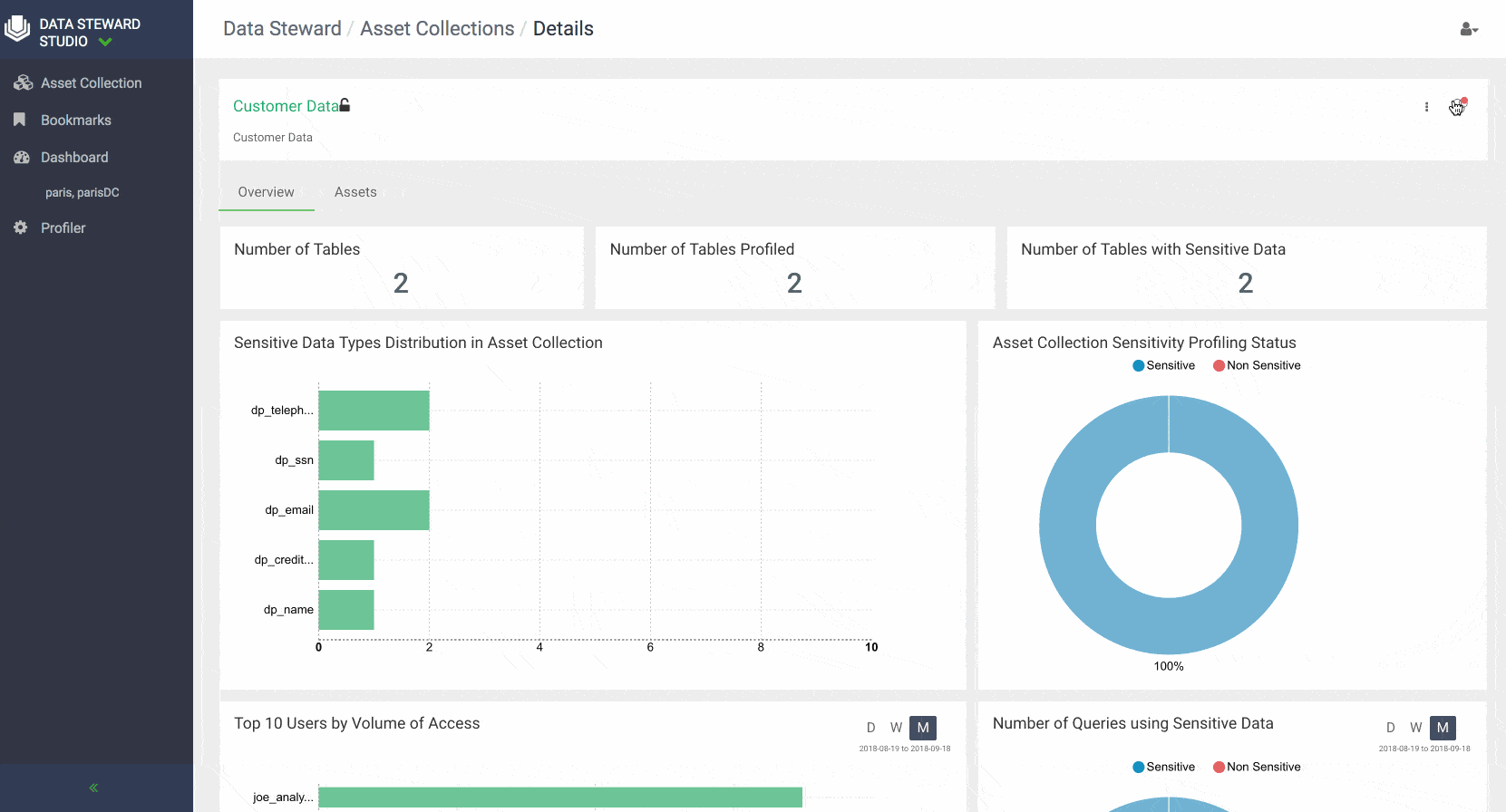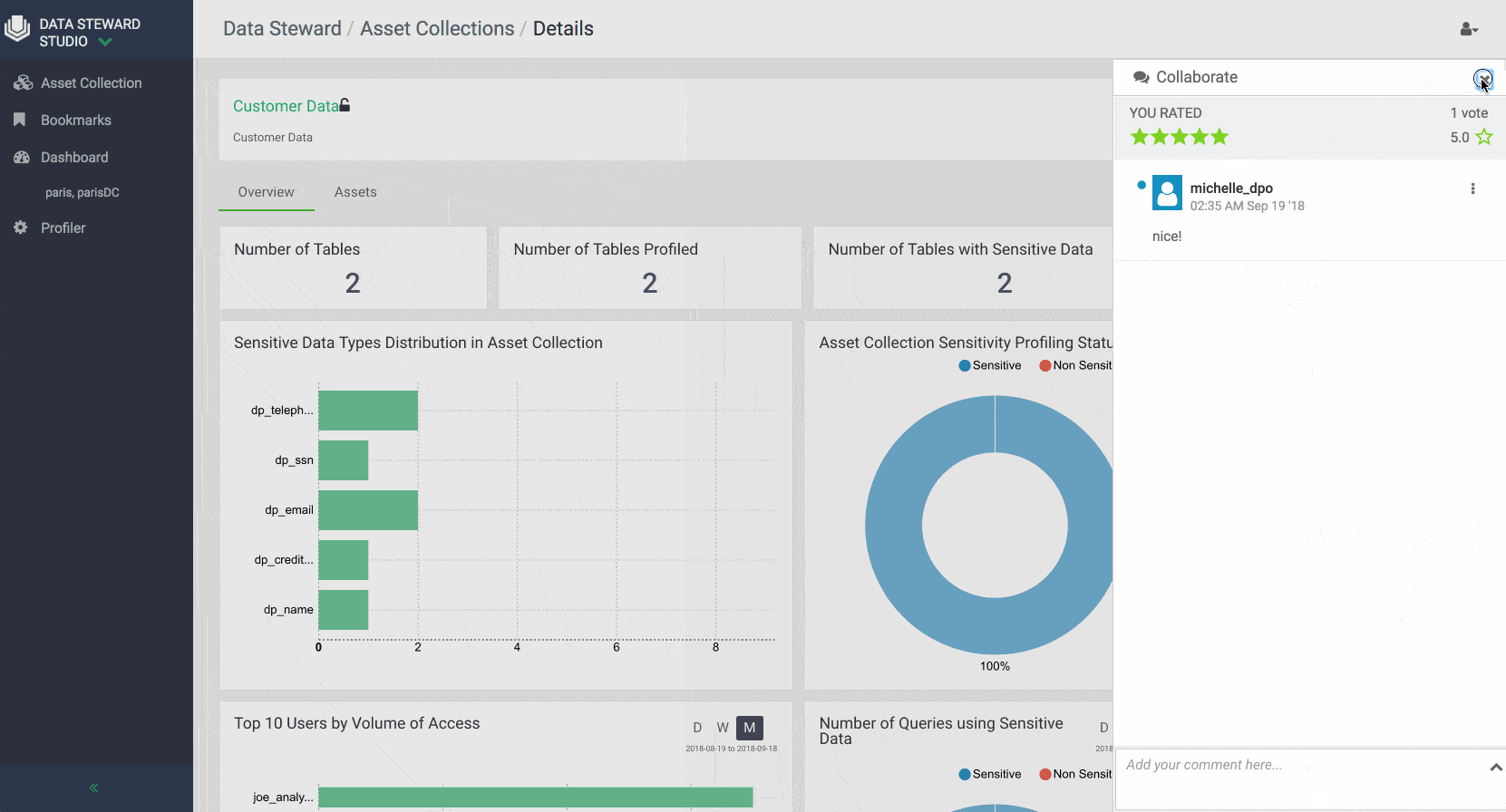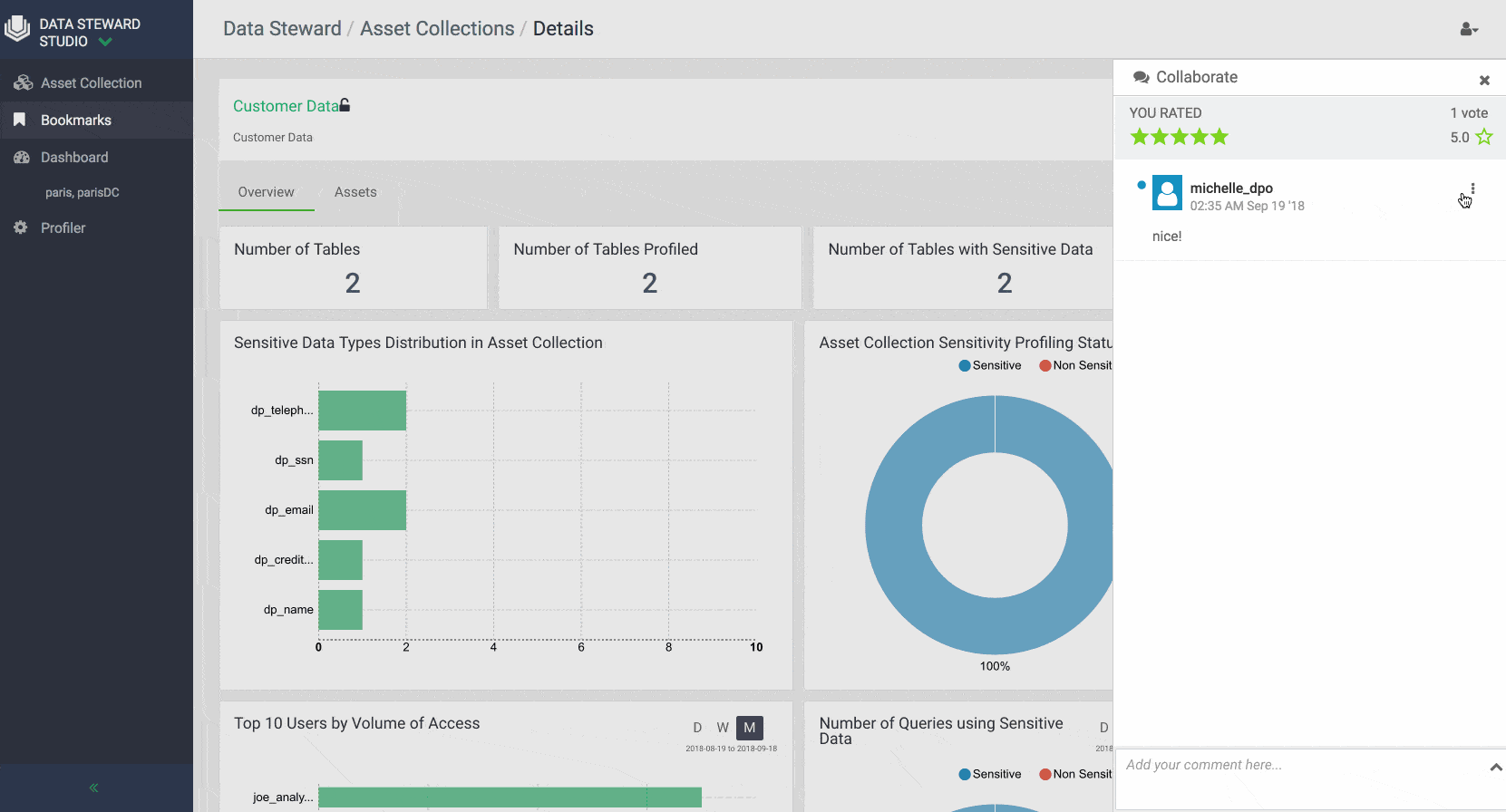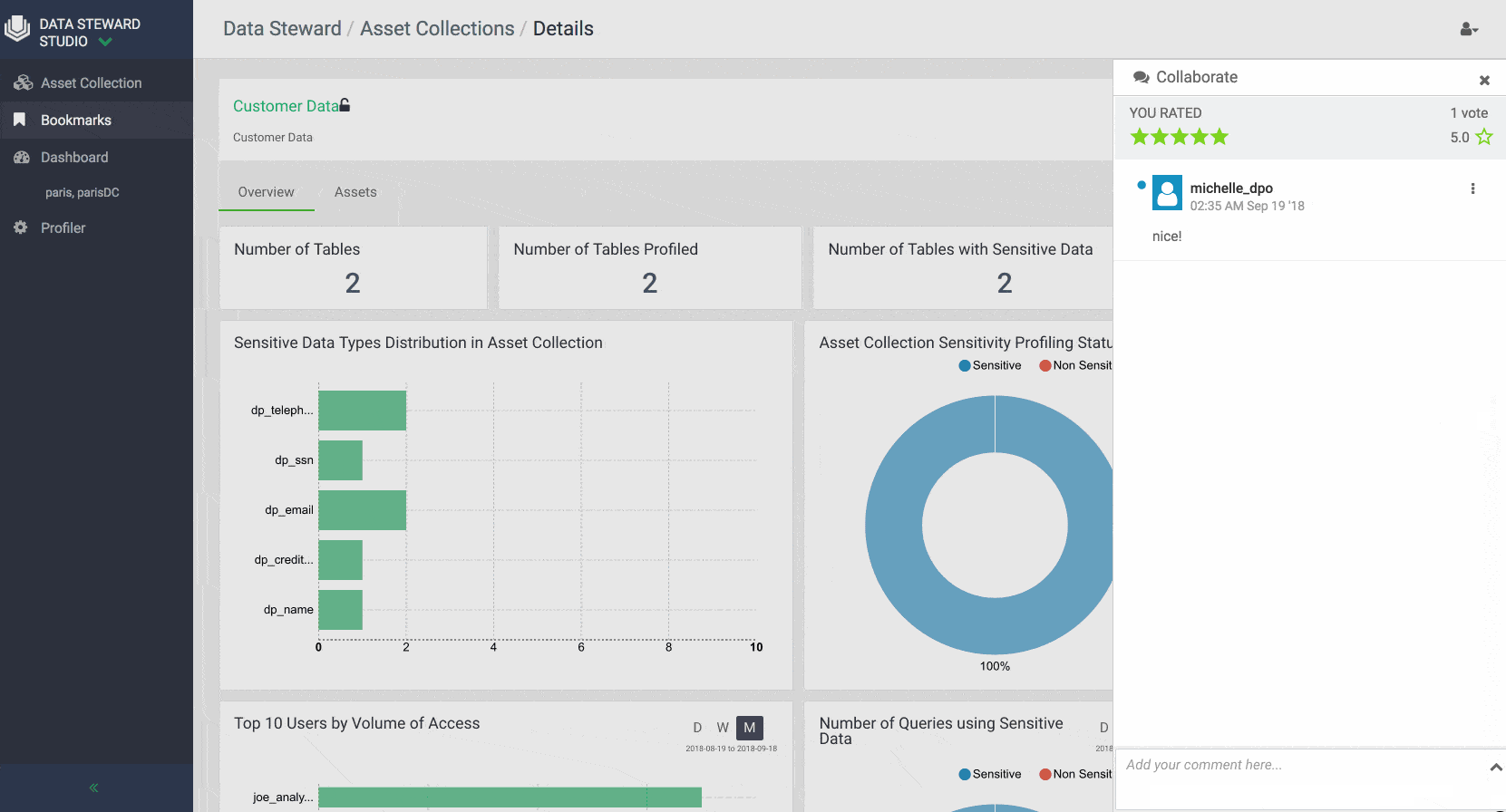
Overview: Provides metadata summary properties such as number of rows, columns, sensitive columns, number of partitions, owner, tags, profilers. Lineage shows the chain of custody for the data from relevant metadata repositories and both upstream paths (lineage) into and downstream paths (impact) out of a given asset. Usage and monitoring metadata are shown in the overview separately including widgets that display the top 10 users for the data asset and access types outlines action performed and operation type as well as trending of data access over time. System classifications generated by profilers (for example for sensitive date type classification for particular columns) and other managed classification (for example business classifications done via Apache Atlas tags) are also shown along with technical metadata and operational summaries of profiler execution.
Schema: Displays the structure and shape details schema of the data asset for structured data such as Hive tables using the relevant metadata repositories such as Atlas. You can also view the shape or distribution characteristics of the columnar data within a schema based on the Hive column profiler.
Policy: The policy view shows authorization policies defined for data assets. These policies may be defined and enforced using Apache Ranger. It includes both resource (physical asset based) as well as classification based policies
Audit: The data asset audit logs page shows both most recent access audits from Apache Ranger and also summarized views of audits by type, user, and time window based on profiling of audit data.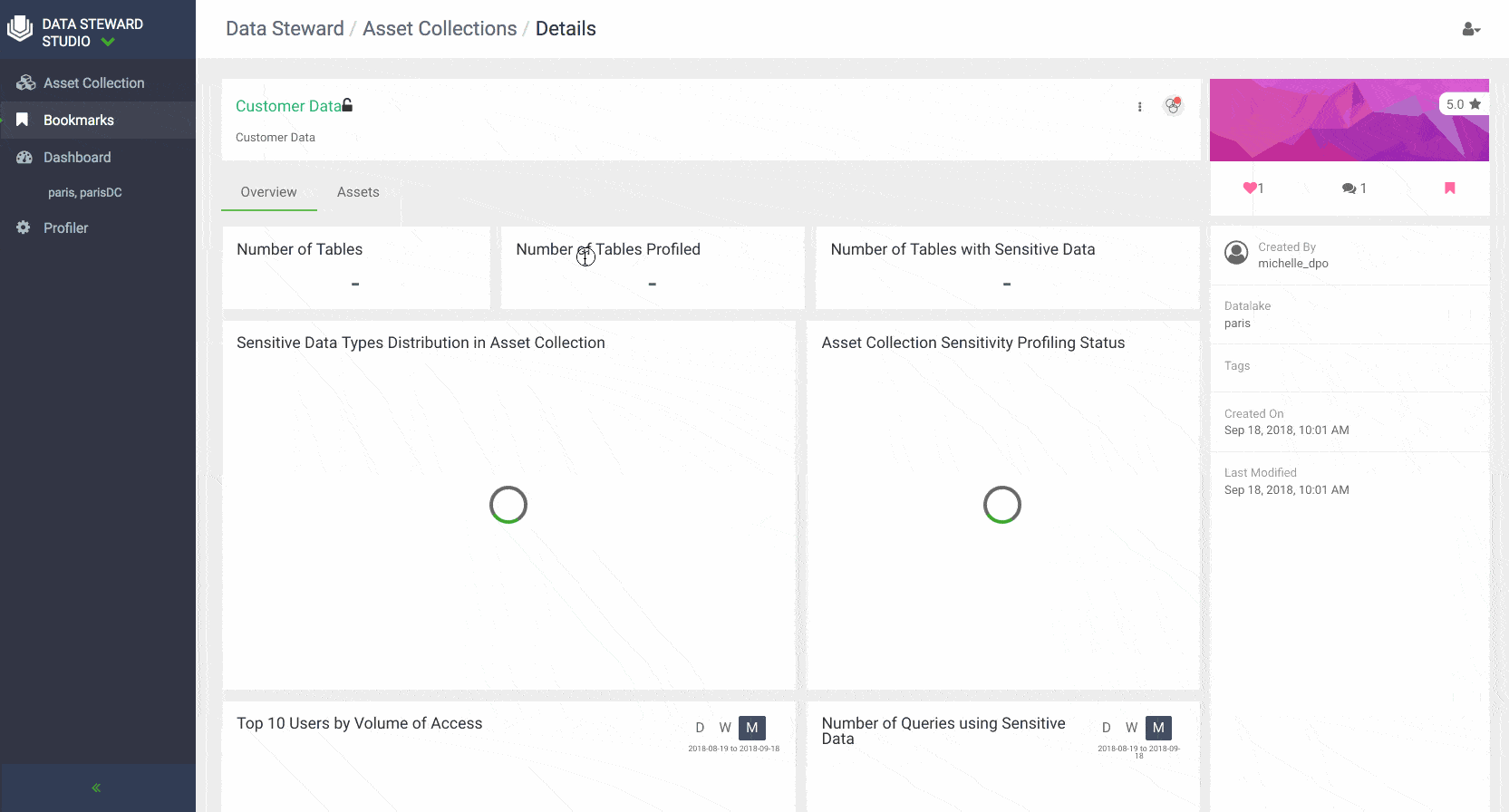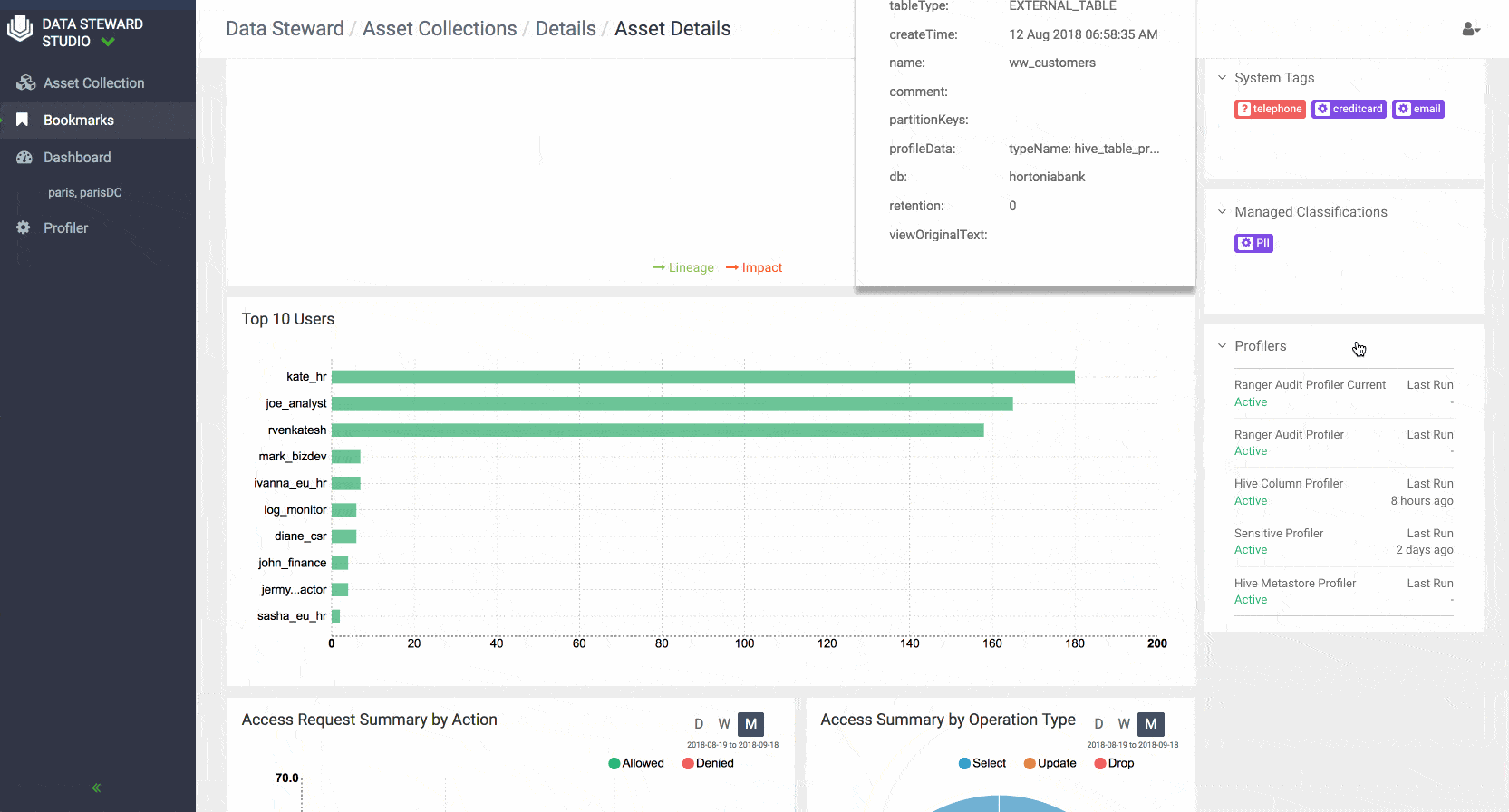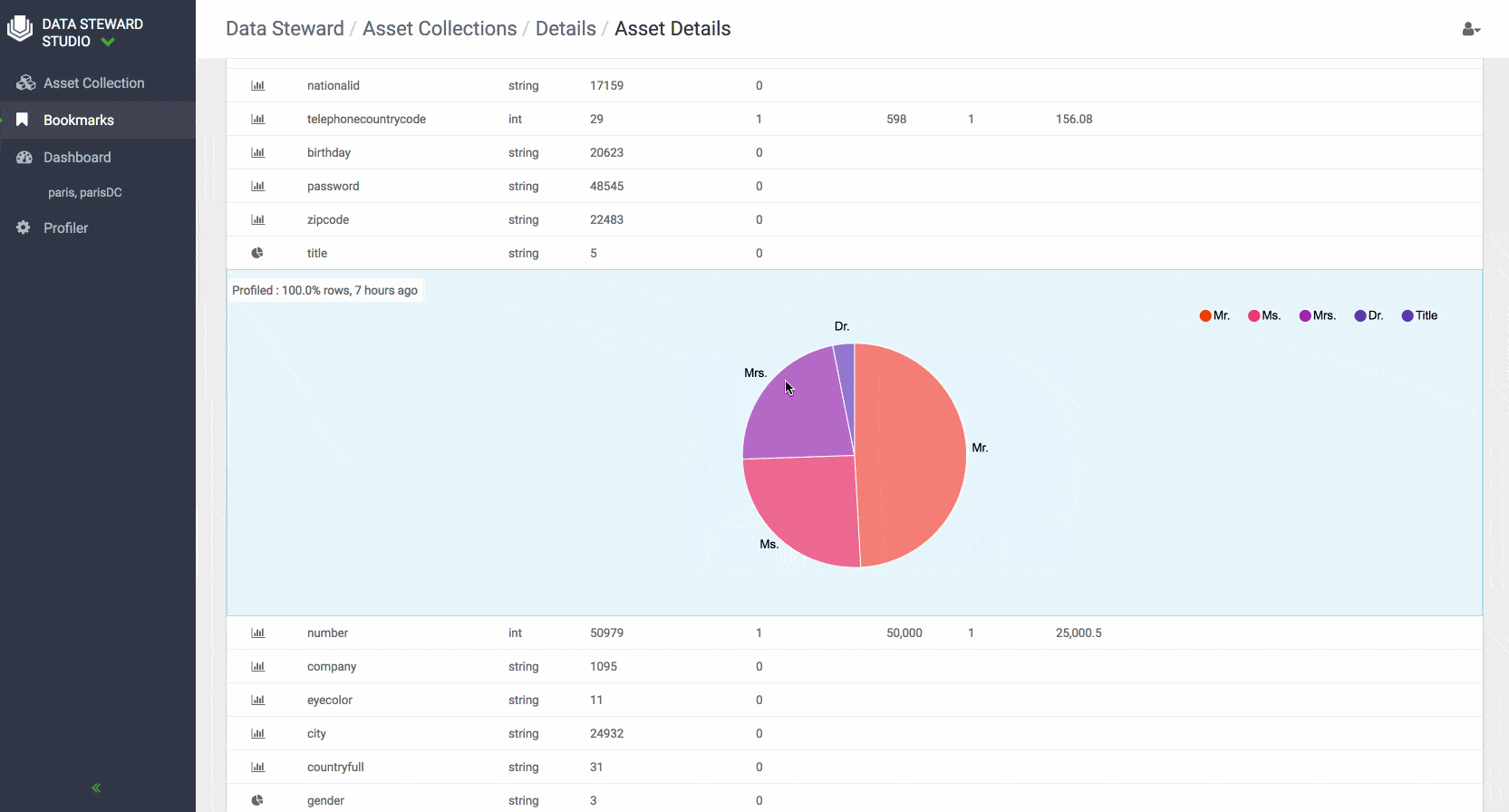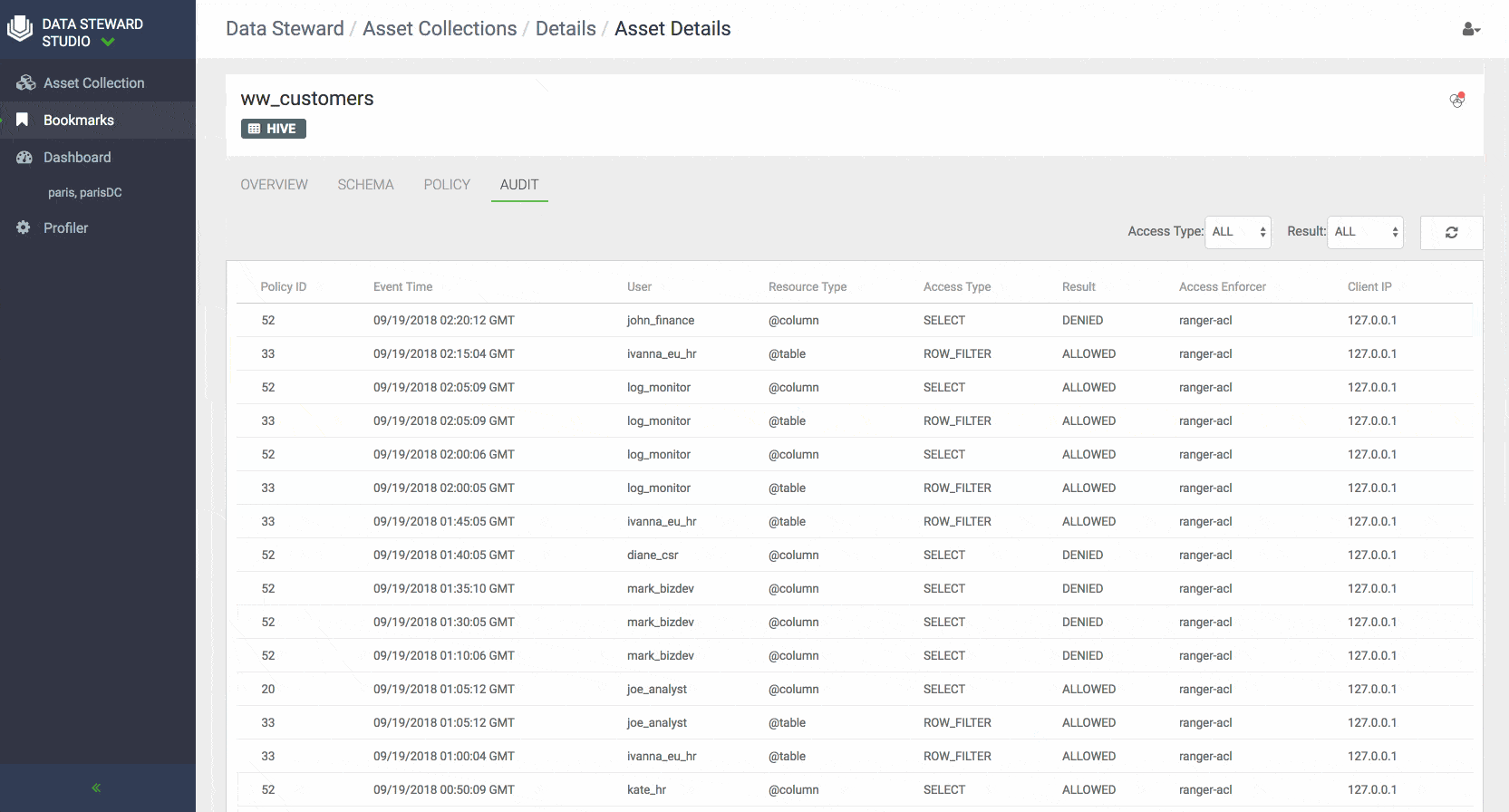
- Collaboration & Crowdsourcing
With DSS, data stewards can collaborate and share their insights with other users in the enterprise regarding various asset collections.
Data stewards can rate asset collections and view the average rating of an Asset Collection. This can help other data stewards and business users to find Asset Collections with certain trusted rating to be used in their analysis. Data stewards can also add their knowledge and insights to an asset collection by adding comments. Other users can then respond to earlier comments or add their comments about each data asset collection. Users of Data Steward Studio can also favorite and bookmark their asset collections for easy access.
- Dashboards and reports
DSS also provides a comprehensive dashboards that show at a glance the summary of data in a particular data lake or asset collection. For example, one can get an idea of how data is growing over time in terms of # of tables, how much of the content within the tables has been profiled and deemed to be sensitive, understand what are the top accessed tables in a data lake.
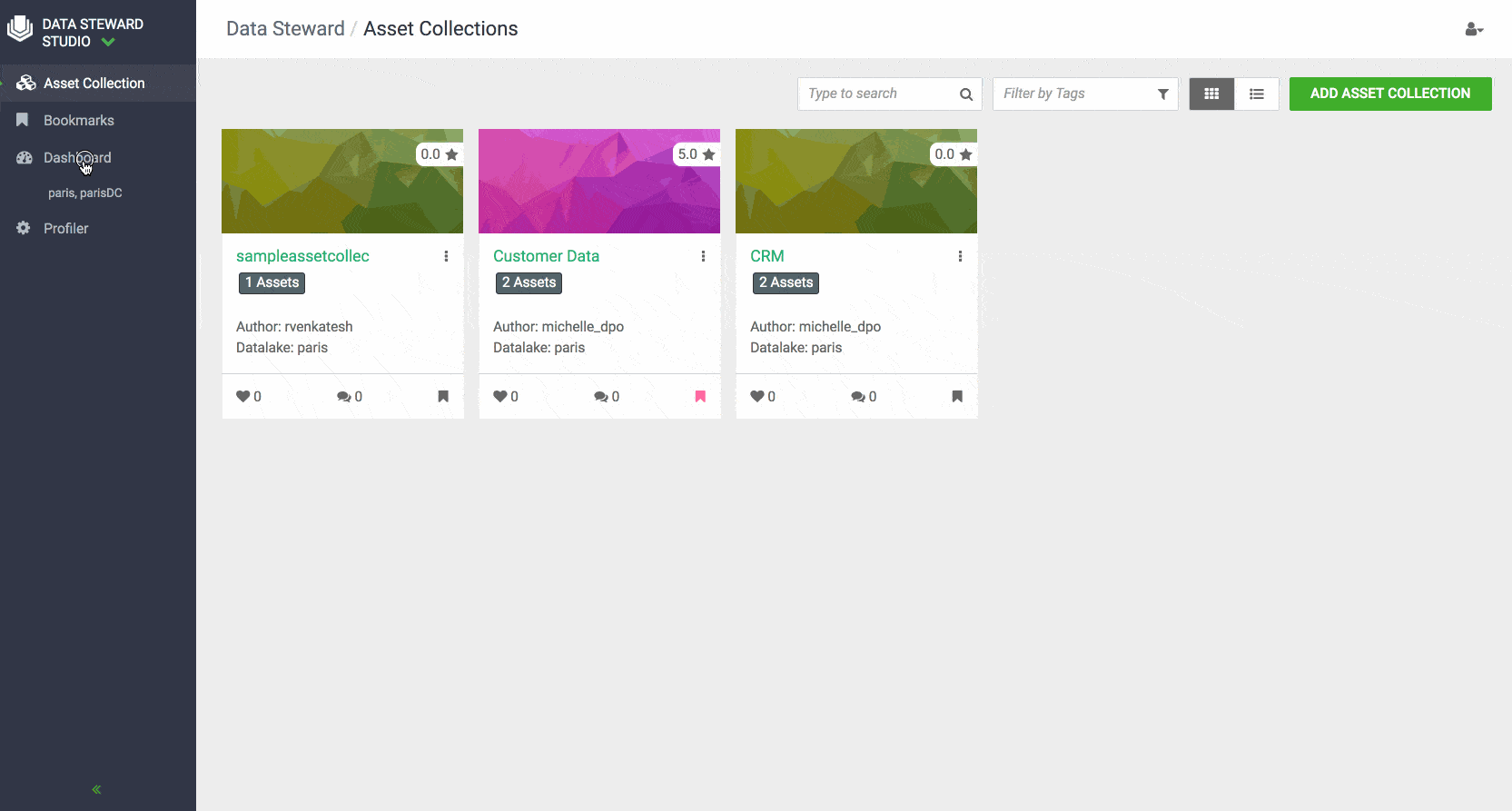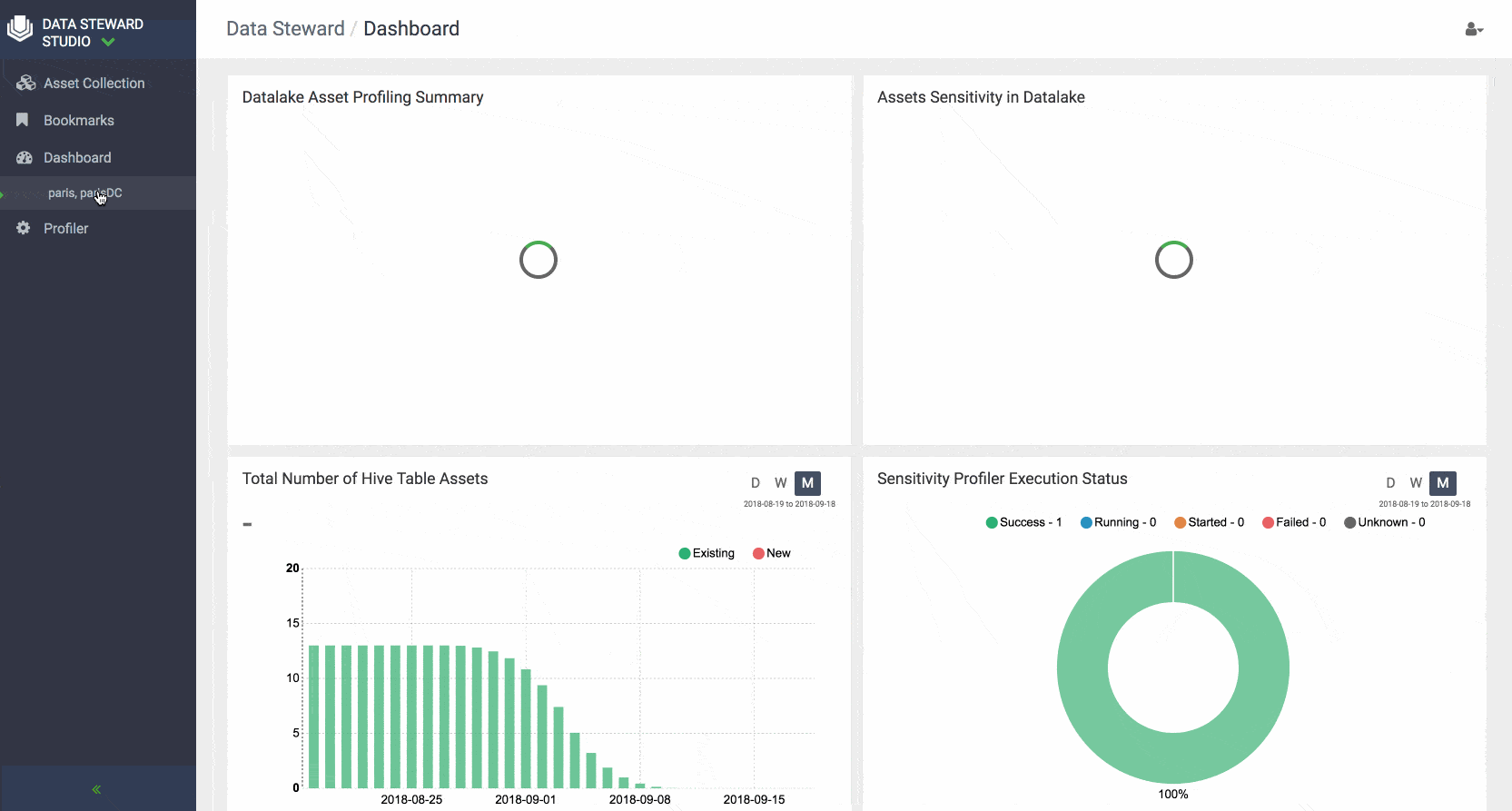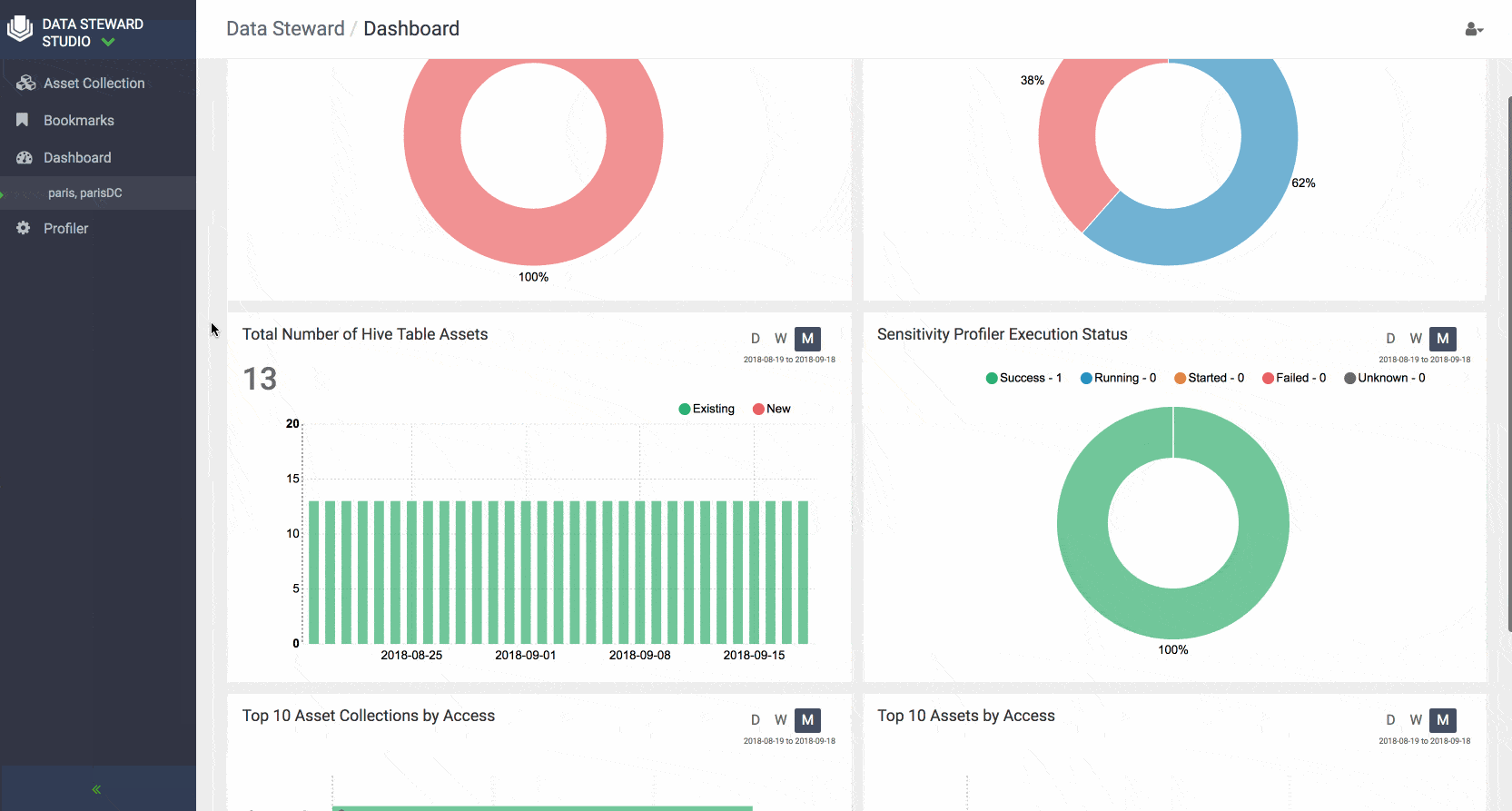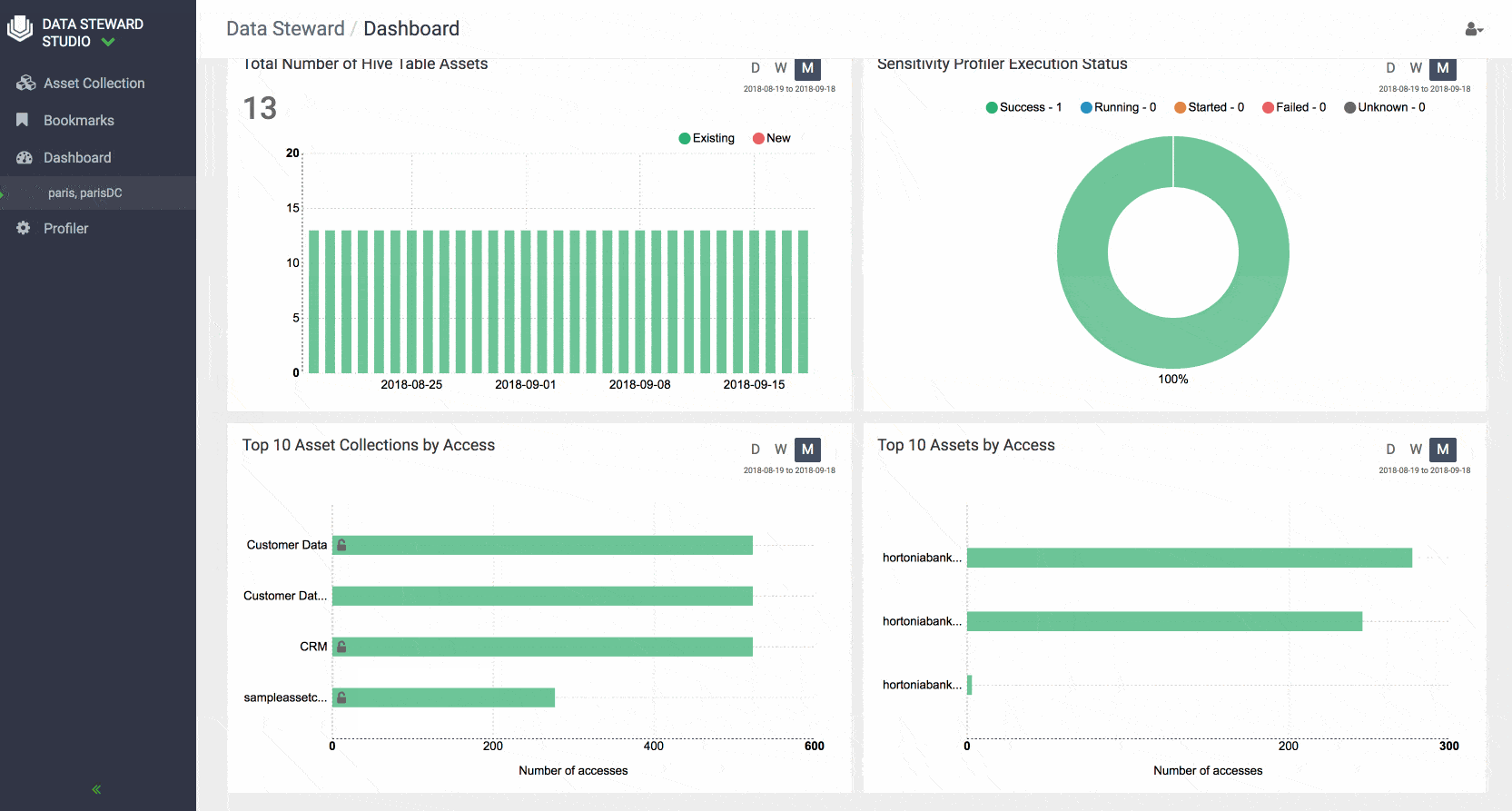
Similar dashboards are also available for every Asset Collection to give users a complete picture of the assets collection usage, contents, and help them collaborate effectively with others across the enterprise.
In summary, DSS enables enterprises to contextualize knowledge about data located across hybrid data lake platforms, take meaningful actions or generate actionable insights about their business operations, and reduce the lag between insight discovery and value creation.
See DSS in action from the keynote demo in DataWorks Summit, Berlin and conference breakout session on Security & Governance at Dataworks Summit, San Jose.
To learn more visit https://hortonworks.com/products/data-services/data-steward-studio/.
Editor's Choice


Hi ,
I found DSS is suitable to our use case. Hence, we are going to use DSS tool for identification of sensitive/PII columns. As per the blog, we can achieve it using DSS. So, we have few questions related to that one as follow.
1. Can we do some configuration in DSS to identify senstive column other than inbuilt one (inbuilt means IBAN numbers (27 EU Countries),Telephone (EU, AMER) )? In short, is that possible to a develop custom tag which will identify my sensitive column?
2. Can DSS scan only hive tables data and not other than that?
3. There are very limited blogs and articles on internet related to DSS. So, Can we get user guide which will explain more in detail about how to use DSS tool with example(specially, for custom tag rule feature)