

Introduction
Many of Cloudera’s customers set up Cloudera Manager to collect their clusters’ diagnostic data on a regular schedule and automatically send that data to Cloudera. Cloudera analyzes this data, identifies potential problems in the customer’s environment, and alerts customers, requiring fewer back-and-forths with our customers when they file a support case and provides Cloudera with critical information to improve future versions of all of Cloudera’s software. If Cloudera discovers a serious issue, Cloudera searches this diagnostic data and proactively notifies Cloudera customers who might encounter problems due to the issue. This blog post explains how Cloudera internally uses the Altus as a Service platform in the cloud to perform these analyses. Offloading processing and ad-hoc visualization to the cloud reduces costs since compute resources are used only when needed. Transient ETL workloads process incoming data and stateless data warehouse clusters are used for ad-hoc visualizations. The clusters share metadata via Altus SDX.
Overview
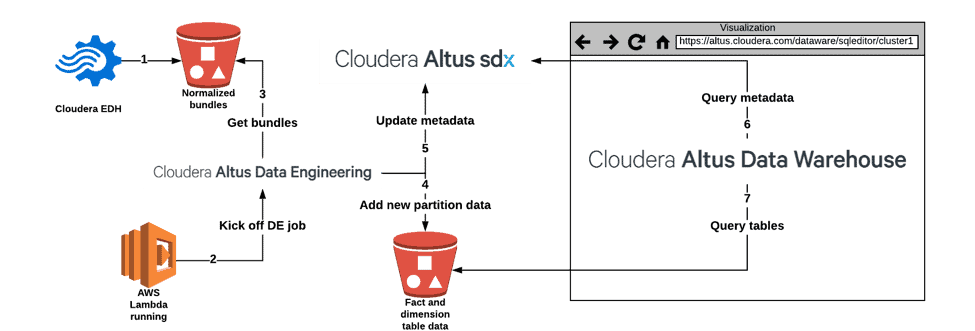
In Cloudera EDH, diagnostic bundles are ingested from customer environments and normalized using Apache NiFi. The bundles are stored in an AWS S3 bucket with date-based partitions (Step 1 in Fig 1). AWS Lambda is scheduled daily (Step 2 in Fig 1) to process the previous day’s data (Step 3 in Fig 1) by spinning up Altus Data Engineering clusters to execute ETL processing and terminating the clusters on job completion. The jobs on these DE clusters produce a fact table and three dimension tables (Star schema). This extracted data is stored in a different S3 bucket (Step 4 in Fig 1) and the metadata produced from these processes, such as schema and partitions, are stored in Altus SDX (Step 5 in Fig 1). Whenever data needs to be visualized, a stateless Altus Data Warehouse cluster is created, which provides easy access to the data via the built-in SQL Editor or JDBC/ODBC Impala connector (Step 6,7 in Fig 1).
Altus SDX
We create configured SDX namespaces for sharing metadata and fine-grained authorization between workloads that run on clusters that we create in Altus Data Engineering and Data Warehouse. Configured SDX namespaces are built on Hive metastore and Sentry databases. These databases are set up and managed by Altus customers.
First, we will create two databases in an external database.
$ mysql -h support-bundle-analyzer.cxxhh0eqnvu7.us-west-2.rds.amazonaws.com -u sba -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 51918 Server version: 5.7.23-log Source distribution Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> create database hive_c6; Query OK, 1 row affected (0.05 sec) mysql> create database sentry_c6; Query OK, 1 row affected (0.02 sec)
Fig 2 – Hive and Sentry external database creation
We will then create a configured namespace using those databases.
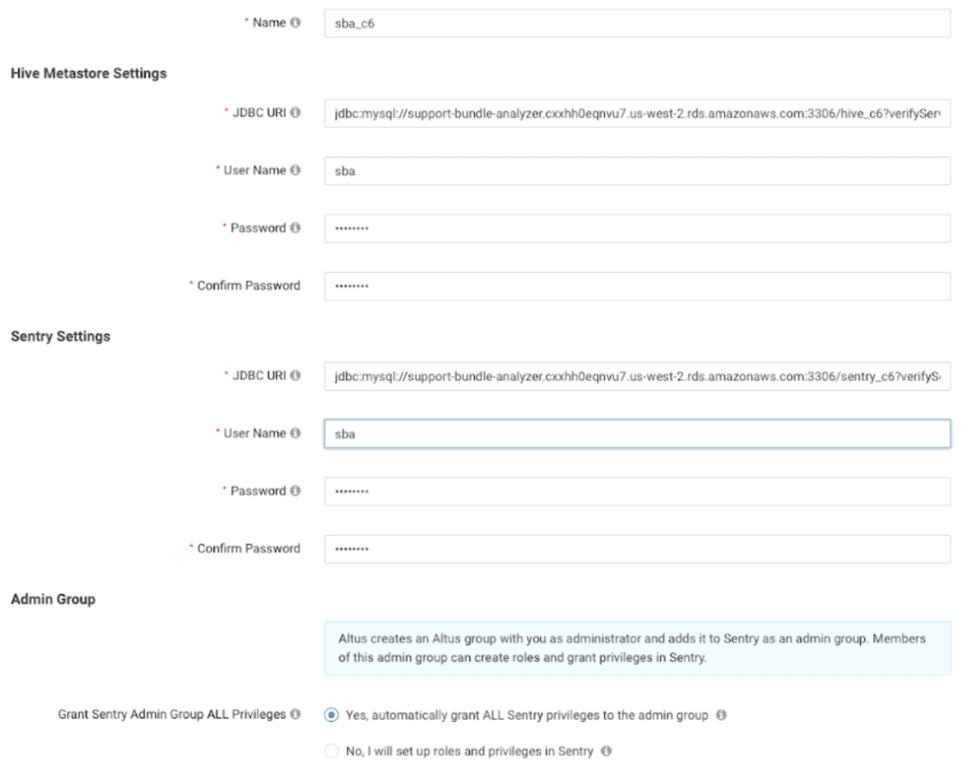
Altus will initialize the schemas of Hive metastore and Sentry databases when a cluster using a configured namespace is started. We chose to grant namespace admin group all privileges so that when the internal user ‘altus’, who executes the Spark job in Data Engineering clusters, has necessary DDL permissions.
Altus Data Engineering
We need to process the bundles that were uploaded the previous day. To do this, we need a mechanism to start an Altus Data Engineering cluster periodically, which executes the job and terminates after the processing is done. We execute an AWS Lambda function that is periodically triggered by an AWS Cloudwatch rule. This AWS Lambda uses Altus Java SDK to kick off an ephemeral Data Engineering cluster with a Spark job.
public DEJobKickoff.Response handleRequest(DEJobKickoff.Request request,
Context context) {
DataengClient deClient =
DataengClientBuilder.defaultBuilder()
.withCredentials(new BasicAltusCredentialsProvider())
.build();
CreateAWSClusterRequest awsClusterRequest = new CreateAWSClusterRequest();
awsClusterRequest.setClusterName("support-bundle-analyzer-secure");
awsClusterRequest.setCdhVersion("CDH61");
awsClusterRequest.setServiceType("SPARK");
awsClusterRequest.setEnvironmentName("atm-secure");
awsClusterRequest.setNamespaceName("sba_c6");
awsClusterRequest.setWorkersGroupSize(3);
awsClusterRequest.setInstanceType("m4.xlarge");
awsClusterRequest.setAutomaticTerminationCondition("EMPTY_JOB_QUEUE");
JobRequest jobRequest = new JobRequest();
SparkJobRequest sparkJobRequest = new SparkJobRequest();
sparkJobRequest.setJars(
Collections.singletonList(
"s3a://ganeshk-hive-qa/altus_support_bundle_analyzer_v3-9.jar"));
sparkJobRequest.setMainClass("com.cloudera.altus_support_bundle_analyzer.Extractor");
LocalDate yesterday = LocalDate.now().minusDays(1);
sparkJobRequest.setApplicationArguments(Collections.singletonList(yesterday.toString()));
jobRequest.setSparkJob(sparkJobRequest);
jobRequest.setName("sba");
awsClusterRequest.setJobs(Collections.singletonList(jobRequest));
deClient.createAWSCluster(awsClusterRequest);
return new DEJobKickoff.Response("Success!");
}
This will process the diagnostic data that was stored in a S3 bucket. It will create a fact table and three dimension tables. The data for those tables will be stored in a different S3 bucket. The metadata will be stored in Altus SDX. The cluster is deleted at the end as the job only runs for 30 minutes.
Altus Data Warehouse
Whenever we want to analyze the data, we spin up an Altus Data Warehouse cluster in the same environment, using the same namespace as the Altus Data Engineering cluster. Doing so allows the Altus Data Warehouse to have direct access to the data and metadata created by the Altus Data Engineering clusters.
Fig 4 – Data Warehouse cluster creationOnce the cluster is created we can use the built-in Query Editor to quickly analyze the data.
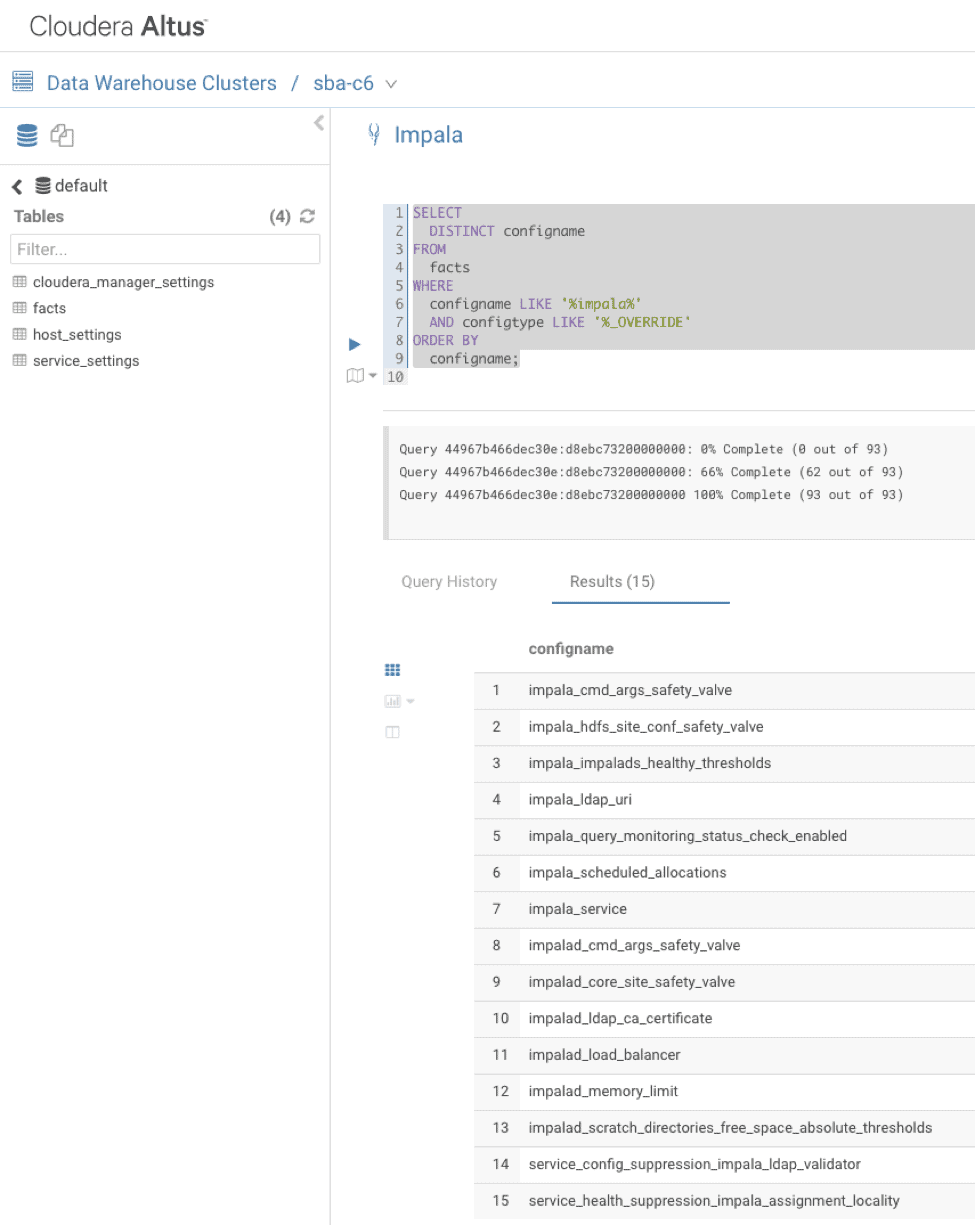
If you need to generate custom dashboards, connect to the Altus Data Warehouse clusters using Cloudera Impala JDBC/ODBC connector. Recently, we released a new Impala JDBC driver which can connect to an Altus Data Warehouse cluster by simply specifying the cluster’s name.
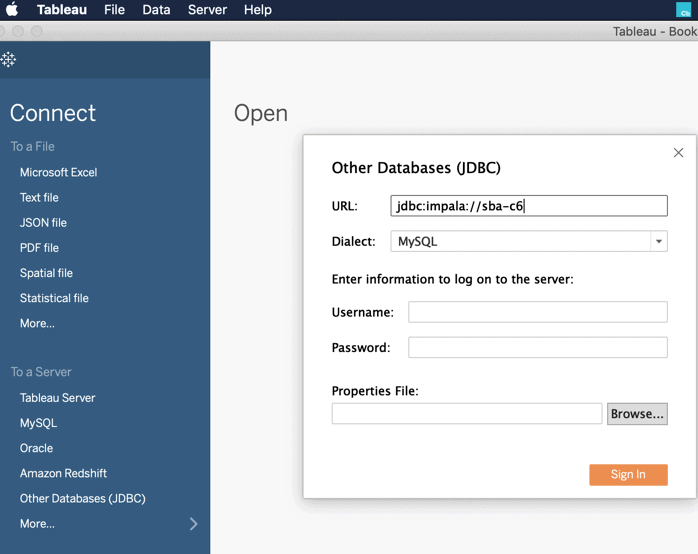
In the image above, we show how easy it is to connect Tableau to the tables in Altus Data Warehouse.
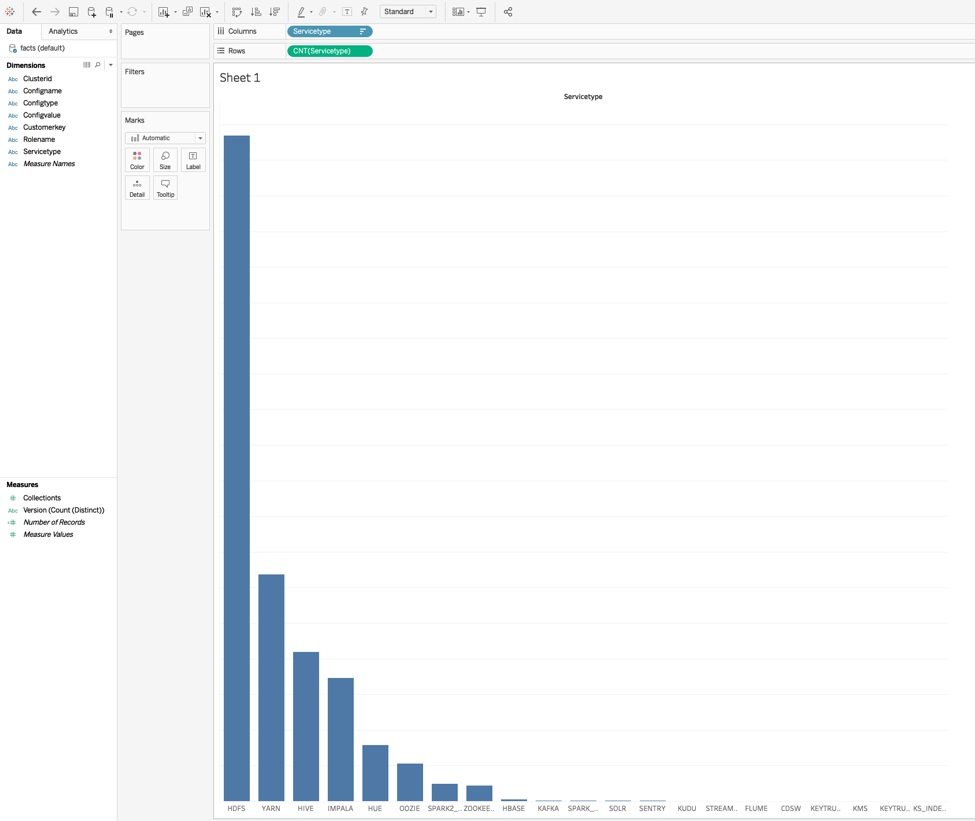
In the above visualization, you can see the distribution of services running in Cloudera clusters. Note that this is based on a random dataset.
What’s Next?
To get started with a 30-day free Altus trial, visit us at https://www.cloudera.com/products/altus.html. Send questions or feedback to the Altus community forum.
Editor's Choice

