

In October of 2020 Cloudera acquired Eventador and Cloudera Streaming Analytics (CSA) 1.3.0 was released early in 2021. It was the first release to incorporate SQL Stream Builder (SSB) from the acquisition, and brought rich SQL processing to the already robust Apache Flink offering.
The team’s focus turned to bringing Flink Data Definition Language (DDL) and the batch interface into SSB with that completed. We wanted to leverage the exciting developments in the latest upstream Flink versions as well as add important functionality to SSB. For customers, this opens up massive new opportunities within the Cloudera stack to incorporate existing data footprints with streaming sources.
We are excited to announce CSA 1.4.0 – with a unified streaming and batch interface. We believe this new capability will unlock net new capabilities for use cases in IoT, Finance, Manufacturing and more. This gives customers the ability to create unique ETL flows, real-time data warehousing, and create valuable feeds of data without massive infrastructure redesign.
Why batch + streaming?
For so long we’ve been told that batch and streaming (bounded and unbounded systems) were orthogonal technologies – a reference architecture where streams feed lakes and nothing more. One where batch is used to check the validity of streams (lambda) or we need to consider everything a stream (kappa).
But in the trenches, as data practitioners, we wanted more. We wanted to be able to address batch sources and streaming sources in our logic and have the tooling and (SQL) grammar to easily work with them. We wanted the ability to easily incorporate existing enterprise data sources and high velocity/low latency streams of data in simple ways. We needed the flexibility to address both batch APIs and streaming APIs and the connectivity to read from and write to them seamlessly. We needed to experiment, iterate, and then deploy processors that could scale and be recovered without massive data replay. We wanted the schemas to be auto-inferred where possible, and rich tooling to build them where needed.
Ultimately, the business doesn’t care what form the source data is in, and we wanted a framework to deliver data products quickly and easily without massive infrastructure additions or requiring downstream databases. This architecture doesn’t have a fancy name – mostly because it’s just how things should have worked all along. Because of this, CSA 1.4 makes building these data products a snap.
A bit of Flink history
Cloudera Streaming Analytics is powered by Apache Flink and includes both SQL Stream Builder and the core Flink engine. But, maybe you didn’t know that Apache Flink, from the beginning, was a batch processing framework. However, Flink embraced batch and streaming early on with two discrete APIs. Flink Improvement Proposal 131 redefined the Flink API with the focus on the unification of bounded/unbounded processing under the same API. Previously, one must choose one or the other API. With the introduction of Flip-131, the processing mode would be completely abstracted from the program under the table API – allowing the developer to write programs that combined the two processing paradigms neatly and simplistically. Flink has always focused on correct results, and supported exactly-once processing. Combining the power of the engine with time-bounded join grammar gives us options to query bounded and unbounded data using simple join syntax. This is a complete and total game-changer.
SQL Stream Builder meets bounded queries
In contrast to Flink itself, SQL Stream Builder started life as a pure streaming interface. Starting with CSA 1.4, SSB allows for running queries to join and enrich streams from bounded and unbounded sources. SSB can join from Kudu, Hive, and JDBC sources to enrich streams. We will continue to add more bounded sources and sinks over time. SSB has always been able to join multiple streams of data but now it can enrich via batch sources too.
Data Definition Language (DDL)
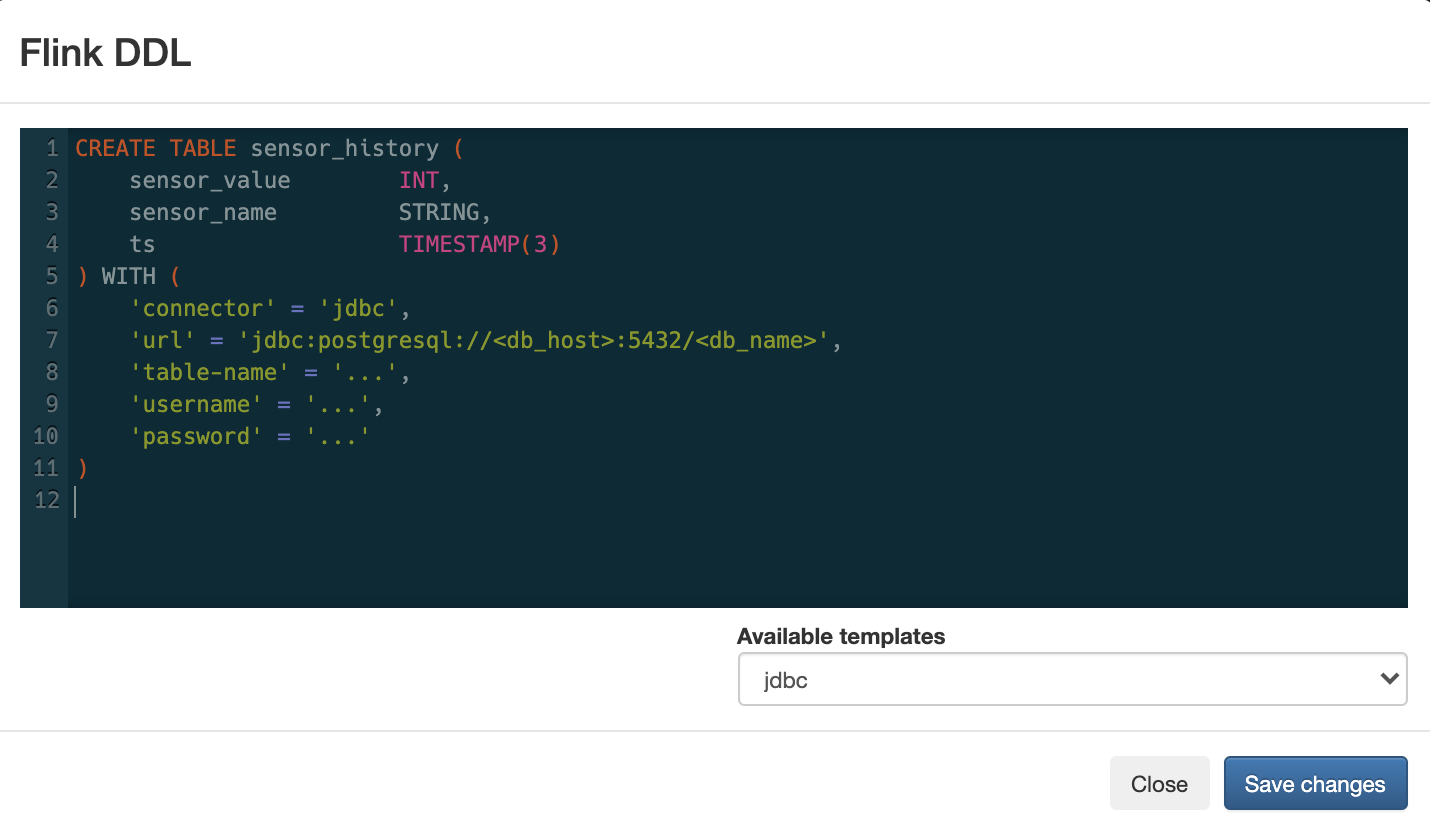
At the heart of the new functionality is the incorporation of Flink DDL into SSB. Tables are defined with a schema (inferred or specified) and Continuous SQL can then be run on them just like any other source. Further, sources across the Cloudera Data Platform are automatically accessible.
-- auto-inferred from CDP catalog import CREATE TABLE `CDP_Hive_Catalog`.`airplanes`.`faa_aircraft` ( `tailnumber` VARCHAR(255), `model` VARCHAR(255), `serial` VARCHAR(255), `icao` VARCHAR(255), `owner` VARCHAR(255) ) WITH ( ... )
Reading and enriching with batch data
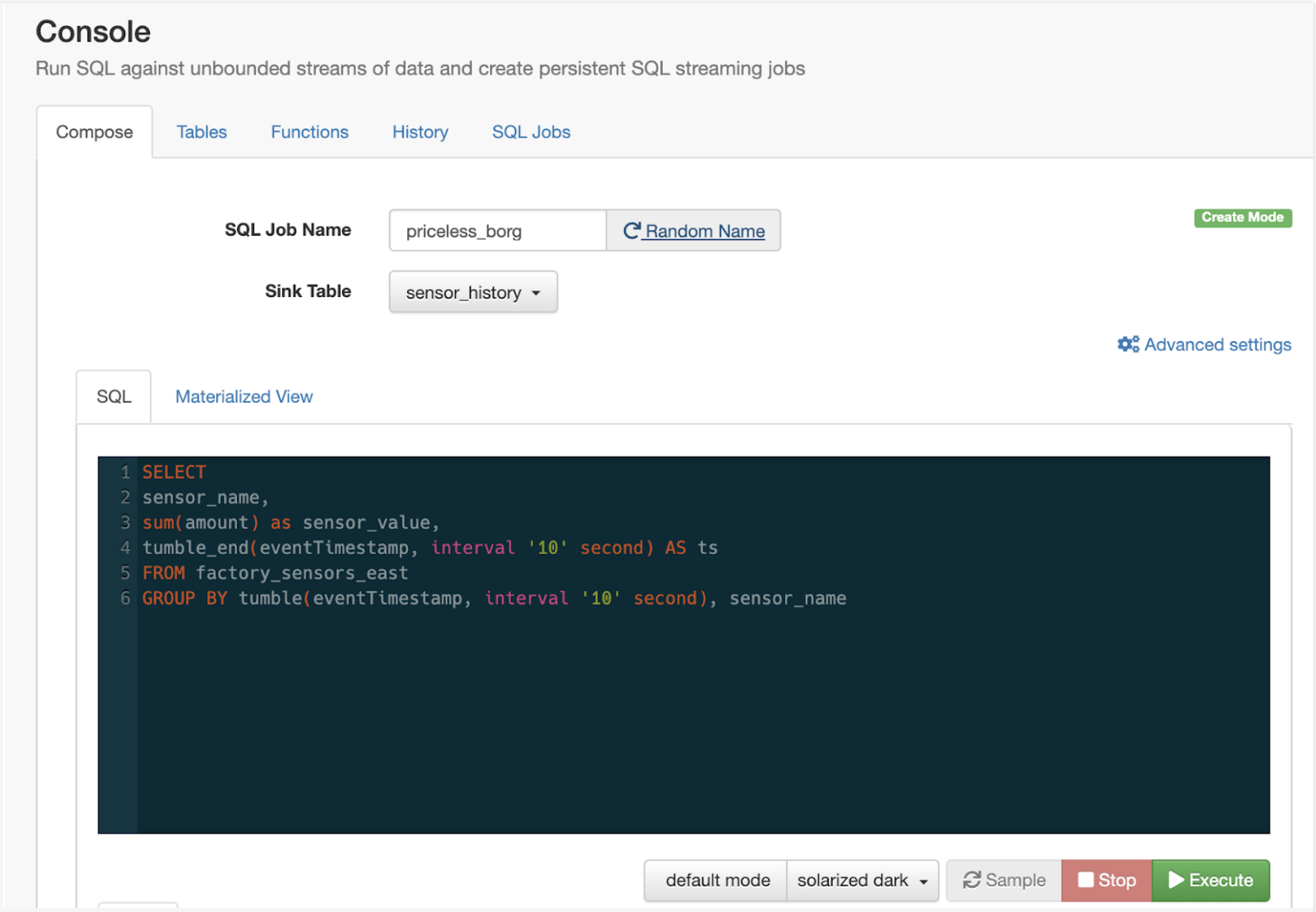
For example, here we are enriching a stream of data that measures testing status for manufacturing systems. We enrich the stream (a) with employee data from (b). We leverage the Flink grammar for specifying time for the table (proctime()), and specify a join key.
SELECT a.stationid, a.test, b.managername FROM mfgrline AS a JOIN `CDP_Kudu_Catalog`.`HR_db`.`impala::mfgr.stations` FOR SYSTEM_TIME AS OF PROCTIME() AS b ON a.stationid = b.stationid
It’s also possible to join multiple sources including stream to stream joins in one statement:
SELECT geo_event.eventTimestamp, geo_event.driverId, geo_event.eventTime,geo_event.eventSource, geo_event.truckId,geo_event.driverName,geo_event.routeId,geo_event.route,geo_event.eventType, geo_event.latitude, geo_event.longitude, geo_event.correlationId, geo_event.geoAddress, speed_event.speed, driver.certified, driver.wage_plan, timesheet.hours_logged, timesheet.miles_logged FROM geo_events_json AS geo_event JOIN speed_events_json AS speed_event ON (geo_event.driverId = speed_event.driverId) LEFT JOIN CDP_Hive_Catalog.employees_hr_hive_db.driver FOR SYSTEM_TIME AS OF PROCTIME() driver ON driver.driverid = geo_event.driverId LEFT JOIN `CDP_Kudu_Catalog`.`default_database`.`impala::employees_hr_kudu_impala_db.timesheet` FOR SYSTEM_TIME AS OF PROCTIME() timesheet ON (timesheet.driverid = geo_event.driverId AND timesheet_week = 1) WHERE geo_event.eventTimestamp BETWEEN speed_event.eventTimestamp - INTERVAL '1' SECOND AND speed_event.eventTimestamp + INTERVAL '1' SECOND AND geo_event.eventType <> 'Normal' AND driver.wage_plan = 'hours' AND timesheet.hours_logged > 45
Writing to batch systems
SSB can also write to batch systems as a sink. This is powerful not only for storing the results of some computation, but also keeping logical state of a computation. For instance, keeping a ledger for what accounts you’ve turned off due to fraud – so you don’t resend future requests. To write to a sink it’s as simple as defining a table and select it as a sink.
Unlocking new use cases and architectures
With the new capabilities CSA 1.4 presents, new use cases are possible, as well as new capabilities that lower latency and boost time to market.
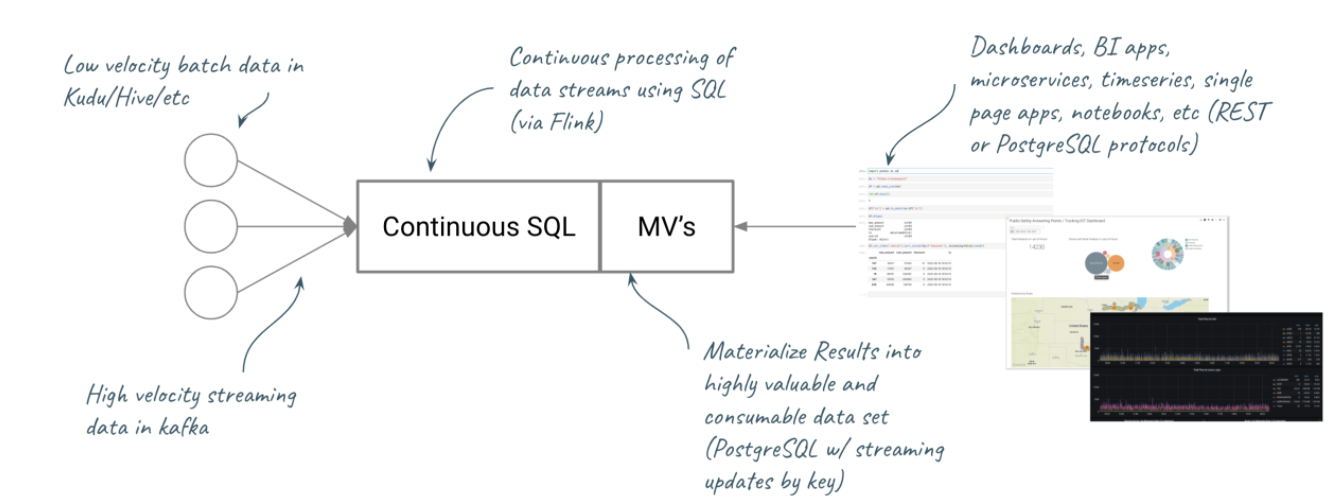
- Distributed real time data warehouse – Join streaming data as facts with batch data as dimensions via materialized views. For instance, performing enriched click stream analysis, or joining sensor data with historical measurements. The new DDL interface in SSB provides the capability to define streaming and batch sources from anywhere in the CDP stack and join them using Continuous SQL.
- Data Science – analysis requires context. For instance, personalized experiences for customers in real time by enriching streams of behavior with history for python models in notebooks. SQL Stream Builder provides a simple REST interface for materialized views that integrates easily with Python and Pandas inside notebooks – so Data Scientists can focus on small but valuable datasets in native tools vs having to parse the firehose of streaming data.
- Real-time manufacturing capabilities – In manufacturing, being able to seamlessly address sources of data from across the enterprise, then materialize views for dashboards can eliminate waste, control costs, and improve quality. For instance, joining historical station failure rates with current telemetry to display predictive output in Cloudera Dataviz or Grafana.
Wrap up
We hope you are as excited as we are for the future of streaming data. The team has worked tirelessly to bring Cloudera Streaming Analytics 1.4 to market, and unleash new capabilities that combine batch and streaming. You also dive into some of the details of the release on our blog.
We are also thrilled to announce that we have been ranked as a Strong Performer in the most recent Forrester Wave, Streaming Analytics, Q2 2021. Download your copy of the report now.
Editor's Choice

