

Cloudera Flow Management, based on Apache NiFi and part of the Cloudera DataFlow platform, is used by some of the largest organizations in the world to facilitate an easy-to-use, powerful, and reliable way to distribute and process data at high velocity in the modern big data ecosystem. Increasingly, customers are adopting CFM to accelerate their enterprise streaming data processing from concept to implementation. Cloudera’s flow development interface is different from typical structured-coding styles, which often presents a challenge of how to apply the ‘DevOps style’ Continuous Improvement/Continuous Delivery (CI/CD) best practices for flow delivery.
In this blog, we will explore an end-to-end life cycle of a data flow process that promotes continuous delivery with minimum downtime. We hope you feel inspired to adopt some of these ideas into your own Cloudera Flow Management CD processes.
Firstly, let’s introduce the basic concepts in a flow development life cycle.
DataFlow Processor
A processor is a pre-developed NiFi component used to integrate with:
- Traditional datastores: SFTP and Relational Databases for instance.
- Big data services: like Kafka and HBase.
- Public cloud services: such as AWS S3 and Azure DataLakeStorage.
CFM has nearly 400 out-of-box processors for customers to configure in their data flows.
DataFlow Process Group
NiFi allows multiple components, such as Processors, to be grouped into a Process Group.
Flow Development
Developers drag and drop processors to design and test a flow.
Flow Template
A template is created from a DataFlow. It can be exported as a flow XML file and imported into another cluster as a template and to instantiate the flow.
Version Control
The flow template itself doesn’t have version control. To overcome this, Cloudera’s NiFi Registry is designed to store versioned DataFlows and to retrieve and upgrade flow versions in related NiFi clusters.
Flow Deployment
- Manually: Downloading/Uploading flow templates is only recommended for developers to copy flows between their laptops and the DEV cluster. Due to its limitation, it shouldn’t be used in any deployment.
- Automatically: NiFi and NiFi Registry provide CLI and RESTful API for deploying a specific flow version from the registry across environments. NiFi Registry is the flow version control repository, from where the flows should be promoted into a higher environment.
Run Flow
Start the flow in the new environment.
Enterprise Challenges with SLAs and Data Security
When a customer maintains enterprise environments that support varying business SLAs & Data Security, more rigor is often required to meet business security regulations to mitigate potential impacts on critical workloads. These include but are not limited to multi-tenancy Access Control Lists (ACL), peer review, and release management.
Enterprise Change Management – A Necessary Evil
For most big organizations Cloudera works with, Production environment changes have to go through a well-defined change process, such as raising change requests, analyzing the impacts, scheduling the change window, creating a backout plan, and informing clients or related system owners. This aims to avoid business impacts and to avoid any data loss during the change.
In terms of Cloudera Flow Management, the ‘data collecting mode’ of a flow will impact the data resilience in different manners.
‘Pull Mode’ flows actively collect data from the source systems or storage. For example, a flow pulls files from an SFTP server or consumes messages from a Kafka topic. Generally, pull mode flows are safe to be momentarily stopped. This is because the data is buffered in the source systems and the processing will be resumed after the flow is restarted.
‘Push Mode’ flows, on the other hand, are passively listening for other systems to send the data. Upgrading a running push mode flow will however create a larger impact – Outages need to be communicated, and where possible flows are designed to minimize downtime.
Cloudera recommends our customers split a flow into at least two process groups, such as a feeding process group and a digestion process group.
In the feeding process group, we only design the processor to listen or connect to the source system, then connect it to an output port. This feeding process group is then seldom changed after the initial deployment. This feeding flow then acts as an internal buffer or queue to hold messages.
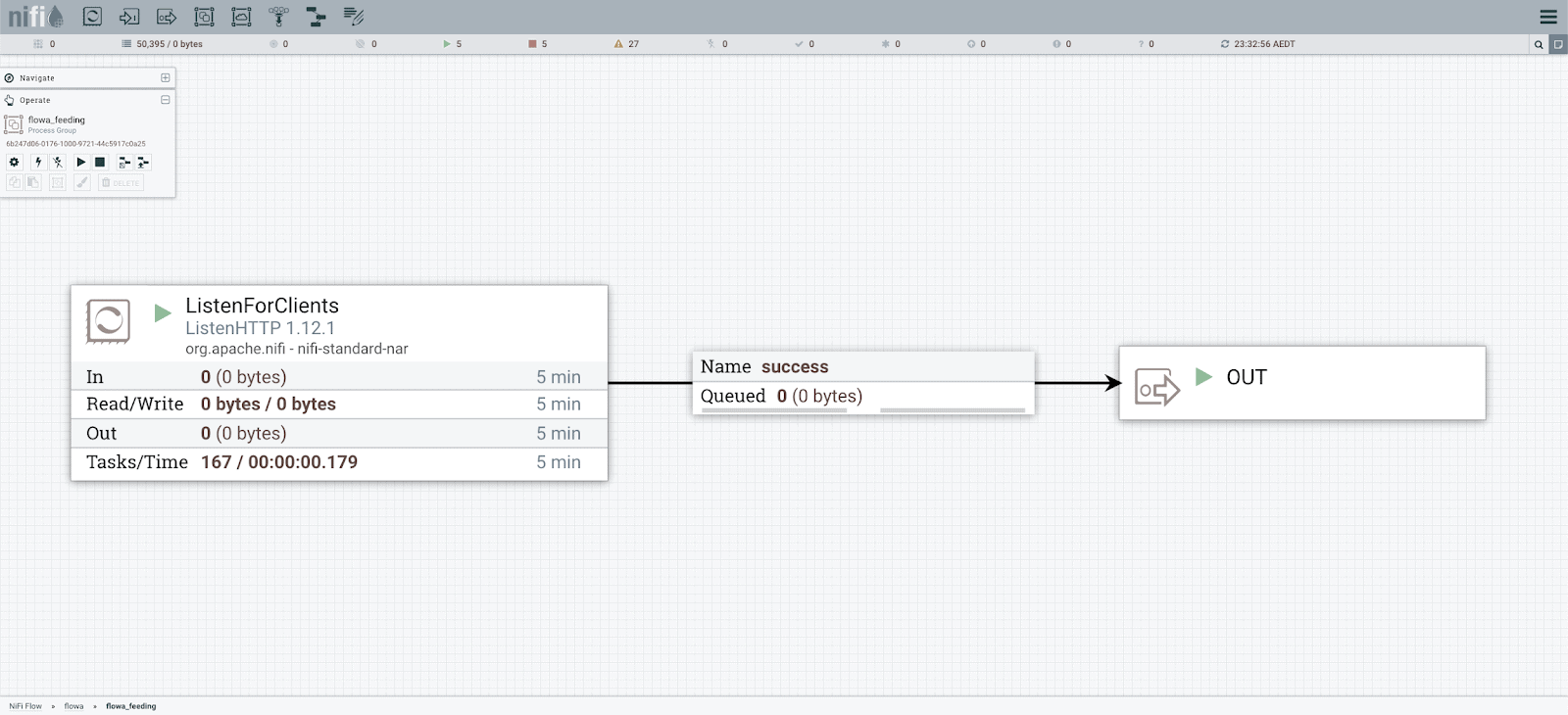
Listening Process in the Feeding Process Group
The digestion process group then handles all the business logic, which may be frequently updated without impacting upstream feeder systems. Below is an example of Feeder and Digestion Flow being implemented together:
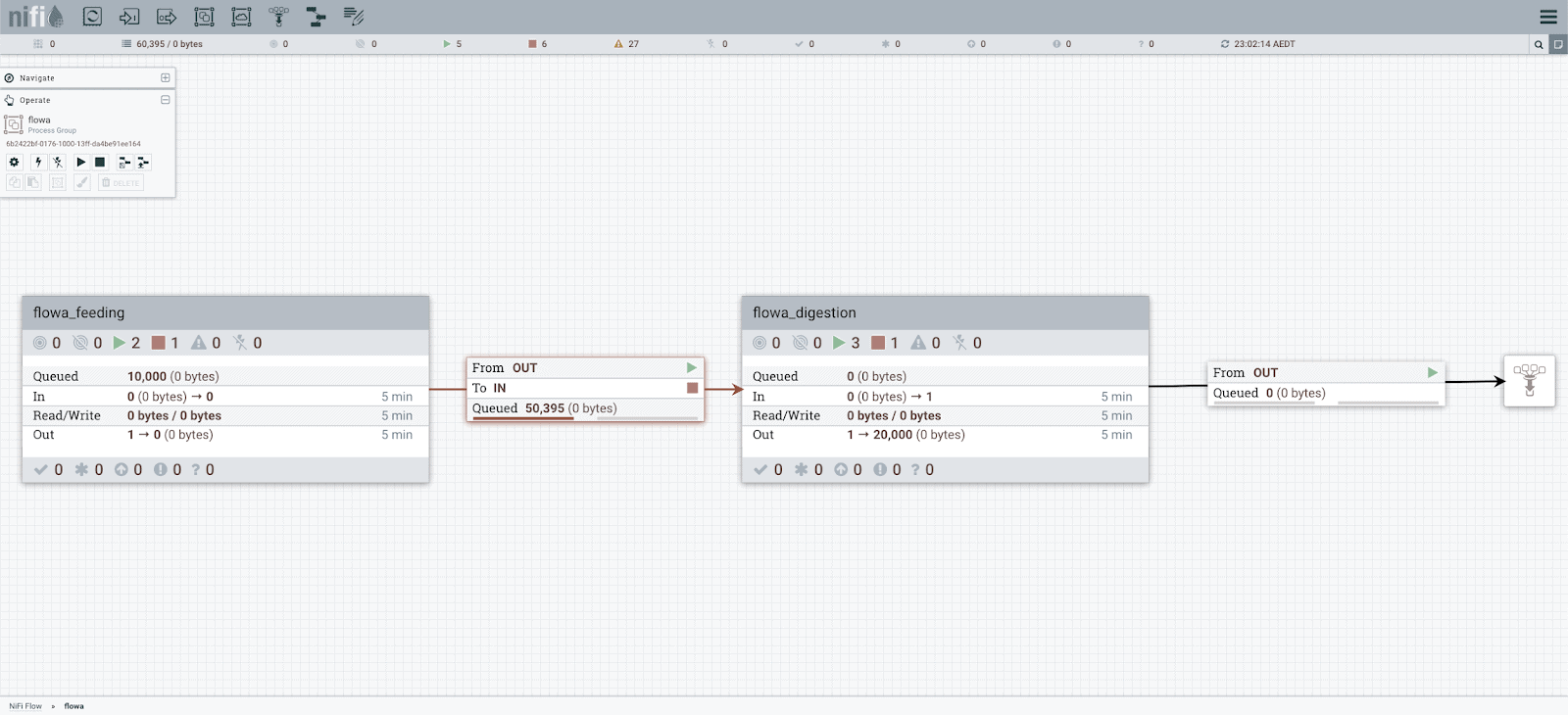
Split a Flow to Feeding and Digestion Process Groups
To deploy the sub-flows individually, the Feeding and Digestion Process Groups are separately version controlled with the registry.
Update a Flow with Queued Messages
If a live flow has queued messages, NiFi won’t allow it to be updated with a new version. This is to avoid any data loss caused by incompatible changes in the flow logic.
Cloudera Professional Service implements a simple scripting solution: deploy_dest_changes.py which checks the flow status every 10 seconds. Once all the queues are clean, it starts updating the process group with a new version:
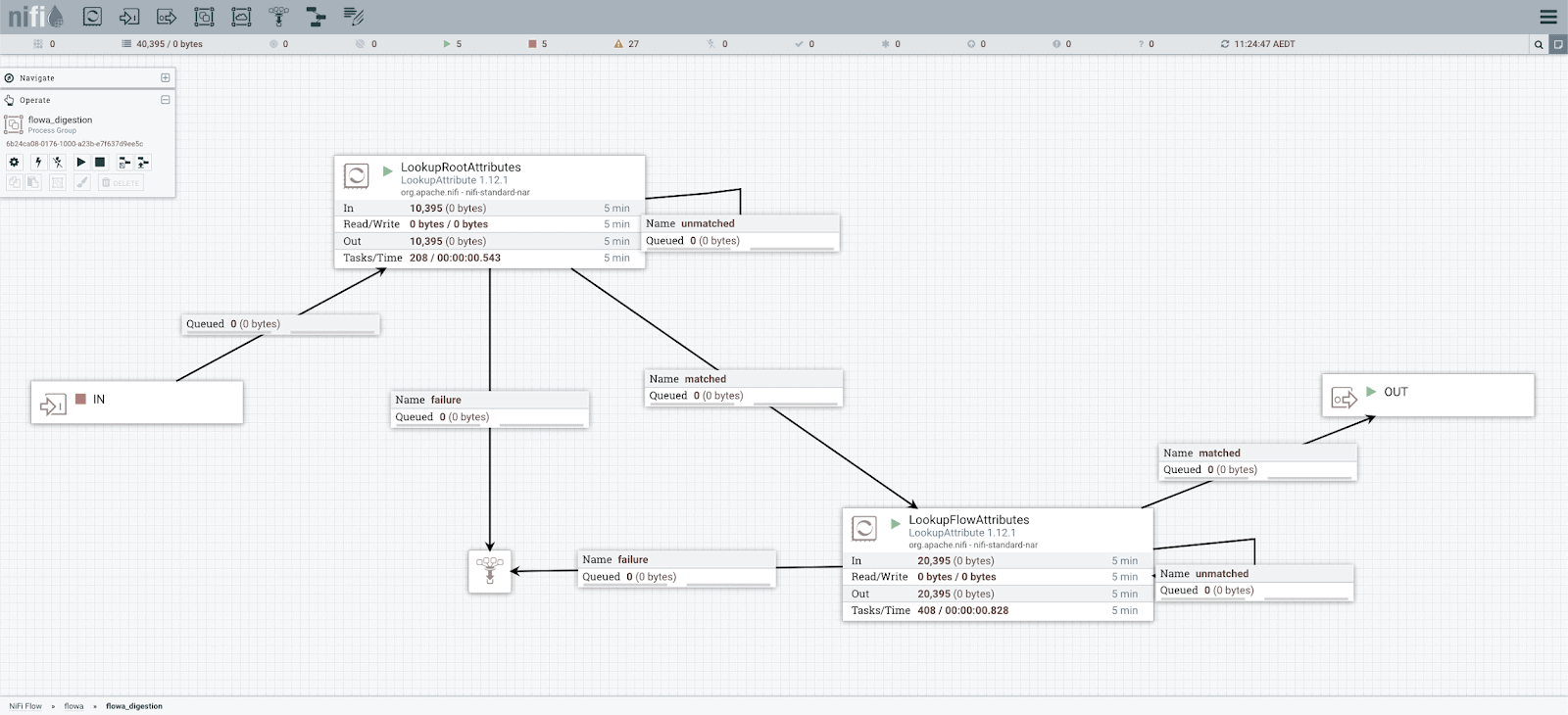
Stop the Input Port and Wait for Queues are Cleared
Control Multiple Tenants
Multitenancy generally refers to a set of features that enable multiple business users and processes to share a common set of resources, such as a Cloudera Data Platform via policy rather than physical separation, yet without violating security requirements, or even revealing the existence of each party.
Our Data Platform is designed to accommodate both Data Multi-tenancy (Clusters supporting different users/roles with entitlements to shared data assets), and Workload multi-tenancy (Clusters that support vastly different workloads for example batch vs. streaming or interactive user queries).
Multi-tenancy is also a challenge for development teams who develop different code and applications that need to be combined to execute in a single environment.
When it comes to Cloudera Flow Management, in a multi-tenant DEV Environment, each team often only develops and operates its own flows. NiFi Registry buckets also need corresponding controls. After the flows are deployed into the multi-tenant UAT Environment, a team should still view their own flows for troubleshooting, but not allowed to change flows.
Ranger policies are designed to control authorization permissions. Ranger plug-in can be enabled for NiFi and NiFi Registry; then Ranger policies can be configured for the designed NiFi resources and NiFi Registry buckets. Each team owns its own NiFi process groups and one bucket in NiFi Registry in the DEV environment. The flow CD functional account has read permissions for all NiFi resources and all NiFi Registry buckets. When it comes to the UAT environment, the CD functional account owns all NiFi resources and all NiFi registry buckets. Then each team will be assigned read permission for their process groups after instantiation.
| Role | DEV | UAT | ||||||
| NiFi | Registry | NiFi | Registry | |||||
| View Configuration and Flow Content |
Operate and Empty Queue |
View | Operate | View Configuration and Flow Content |
Operate and Empty Queue |
View | Operate | |
| System Admin | All | All | All | All | All | All | All | All |
| System Viewer (Dashboard) |
All | No | All | No | All | No | All | No |
| Team | Team Process Groups | Team Process Groups | Team Bucket | Team Bucket | Team Process Groups | No | No | No |
| Flow CD Account | All | No | All | No | All | All | All | All |
Multi-Tenant Role Design Example
Deliver Controller Services
NiFi controller services are sharable services reused by either multiple flows or multiple processors in a flow. The former are root scope controller services suitable for cluster-wide resources connecting to external systems such as database connection pool or restricted controller services. The latter, the process-group-scope controller-services, are often used for services specific to the flow or duplicate services won’t cause external system resource issues such as AWS credentials. The process-group-scope-controller-services are wrapped in the process group version control, but the root scope controller services are out of NiFi Registry control.
The current solution is to copy the root controller services into a dedicated process group, such as ‘root_controller_services’. Then add this process group into NiFi Registry for version control. We can synchronize the ‘root_controller_services’ process group into the UAT environment during the deployment, and update the actual root scope controller services from there.
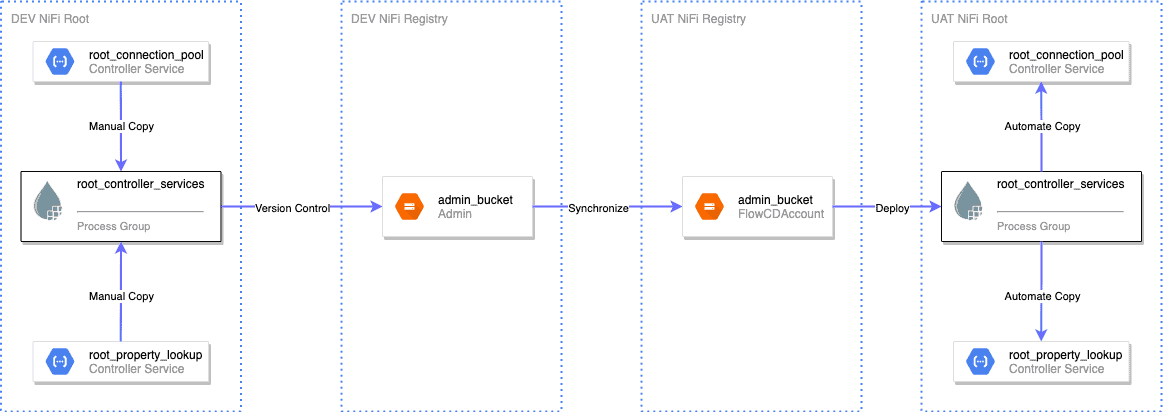
Root Controller Services Delivery
An additional challenge in this solution is knowing which controller services in this process group are changed. NiFi Registry version diff API is the resolution. This option avoids updating all controller services which would impact most of the unrelated flows.
Parameterize Flow Properties
A flow itself should be generic for different environments and fit in an environment by changing the configurable parameters. The parameters should be extracted from the flow and managed in one place. The variable registry can’t parameterize sensitive properties, such as passwords.
We can resolve this by using NiFi parameter context. We create a parameter context ‘flowxx_parameters’ for each flow. All the sub-process groups of the flow, such as feeding and digestion, are assigned this parameter context where the processes and controller services can reference the parameters in the flow. Root controller services require a dedicated parameter context assigned to the root process group and the ‘root_controller_services’ process group.
When a versioned flow is instantiated in the destination environment, the referenced parameter context would be created automatically if it doesn’t exist, and the non-sensitive parameters would be copied as well. However, the sensitive parameters require manually updating the empty value as these values are not exposed in the registry.
If an existing parameter value is updated, it won’t be automatically overwritten in the destination environment. The solution is to add a new parameter with the new version number, ‘kafka_topic_name_v2’. In which, the number should be in line with the process group version. All the referencing in the new flow version is required to point to the new parameter. In this way, the live flow is not affected by applying the new version of the parameter context. After the new flow version is also deployed into the destination NiFi, the deprecated and unreferenced parameters can be cleaned later.
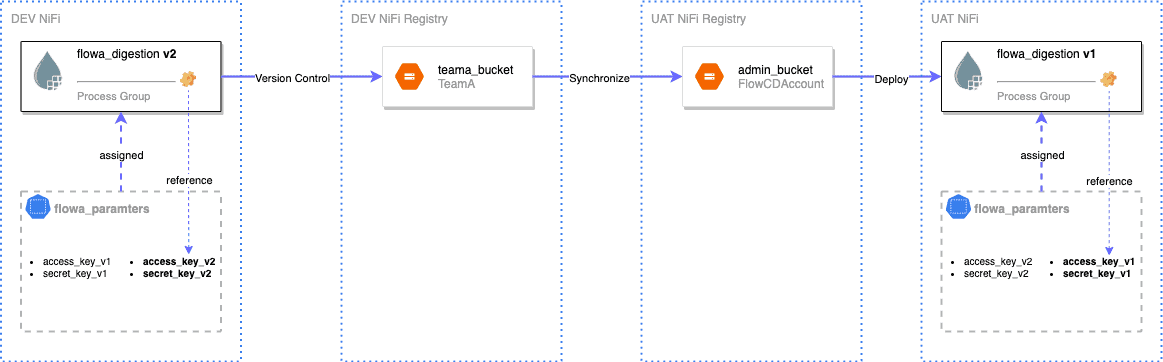
Update Live Flow Parameters
Generic Scripts to Delivery All Flows
Flow logics are different from each other. How to use the same set of scripts to deliver all the flows is a big challenge. Lots of delivery script sets are not preferred due to the maintenance costs.
The naming convention is the key to solve this problem. If all the teams follow the same naming patterns in their flow design, the delivery scripts can be significantly simplified by checking these known patterns. Some naming convention examples are listed here.
- For each flow, create a parent process group with the name ‘flowxx’. But don’t add the parent process group into NiFi Registry for version control. This is because we will deploy the sub-process groups individually.
- In the flow parent process group, split a flow into logically two process groups. The first one is named ‘flowxx_feeding’ for either listening or pulling data from the source. The second is ‘flowxx_digestion’ as the main downstream processing.
- Keep the flow name and process group name identical. For example, enable process group ‘flowxx_feeding’ version control with flow name ‘flowxx_feeding’ in NiFi Registry.
- The feeding process group must have an output port named ‘OUT’, and digestion must have an input port named ‘IN’.
- Create a dedicated process group ‘root_controller_services’ to copy the root scope controller services.
- Name root-scope controller services as ‘root_xx’, while keeping a flow-level one as ‘flowxx_xx’
- ‘root_parameters’ parameter context is for the root process group and the ‘root_controller_services’ group, while ‘flowxx_parameters’ is for the specific flow.
In the next article, we will combine all the preceding solutions into a Cloudera Flow Management continuous delivery architecture.
Big thanks to Pierre Villard, Timothy Spann, Daniel Chaffelson, David Thompson, and Laura Chu for their review and guidance!
Editor's Choice

