

What’s more fun than uncovering insightful trends and patterns buried in piles of data? Being able to easily share and explain them to colleagues and other business teams! New in the Cloudera Machine Learning (CML) 1.2 we’re excited to announce support for hosting persistent web based applications and dashboards using frameworks like Flask, Dash and Shiny to share analytics results and insights with business stakeholders. Follow the demo in this post to start having more fun using CML’s new analytical applications feature today. (Note: this feature is also available in CDSW 1.7).
A simple but compelling demo will always be beat a complicated but dull one. This blog post will help you build a simple but fun interactive Machine Learning application using the new Applications feature available in CML 1.2. You will connect to the application using your phone, draw in a single digit number in a block on the screen and have a trained model running on CML predict what you drew. The code for this can be found at this github repo.
Building models to predict hand drawn digits is the “hello world” of Machine Learning. It is based on MNIST data set and there are some great tutorials that details how this works. The focus of this blog post is about putting it all together with a practical example. It should hopefully provide you the building blocks to modify and expand this into your own applications and Machine Learning projects.
Overall System Overview
This project is divided into three main parts:
- Building and training the model
- Serving the model
- Delivering the interactive web application
The actual end-to-end process is fairly straight forward:
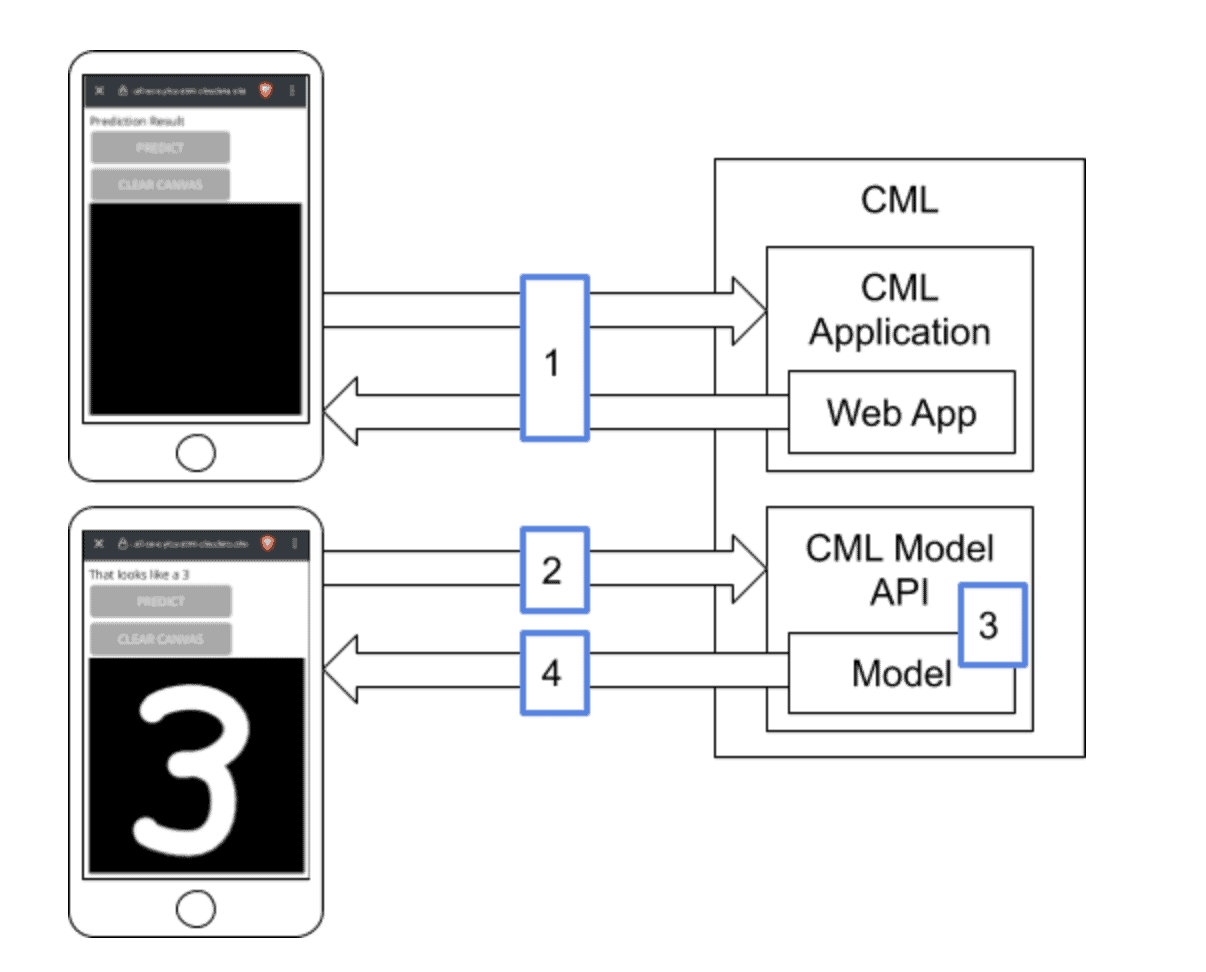
- From a mobile device, you connect to a web server running inside a CML application that delivers the content. You now have the web application interface on your phone. You draw in an image in the black square with your finger, and click predict.
- The web application extracts the image data and makes a REST call to the CML server’s model API.
- The CML model API takes in the image data and does a prediction for what digit the image most likely is using the trained model and returns a result.
- The web application on the mobile device updates the display to show the predicted result.
As you can see this is not too difficult to deploy, the Machine Learning magic lies in the training and serving the models in CML to make accurate predictions.
Training the Model
For this demo, I looked at training and serving the model using a convolution neural network built with PyTorch. As with all data science and machine learning projects, the hard part is getting the data into the correct format and into a useful place.
The MNIST dataset is a collection of 70,000 images of hand-drawn digits [0-9], with each one labeled with its actual value.
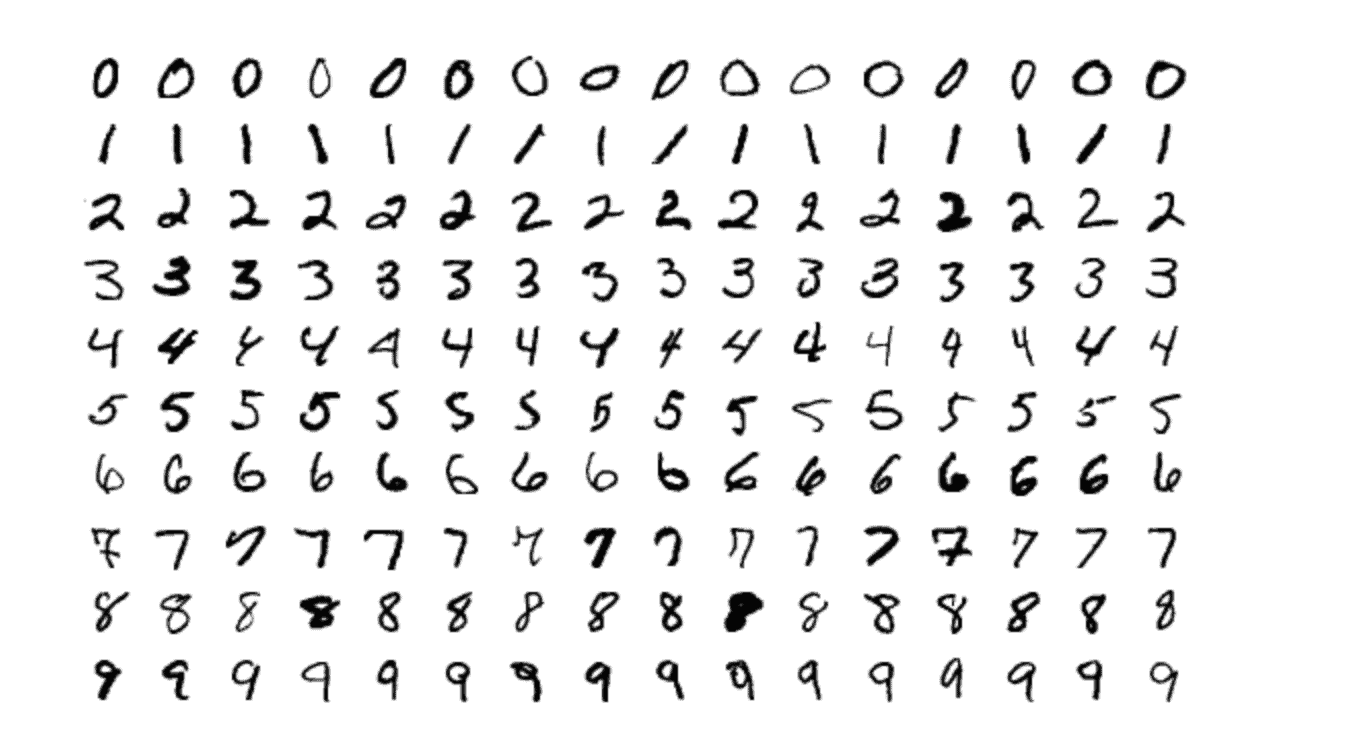
The images are quite small by modern internet image standards being 28 x 28 pixels in size. It is also a grayscale image, with each pixel representing 255 shades from white to black.
The model building and training process is done in a Jupyter Notebook to provide and idea of some of the data structure and transforms that are used.
To do the model training on CML, you will need to install 3 libraries: torch, torchvision and Pillow. Open a Python 3 workbench in the project and run:
> !pip3 install –upgrade torch torchvision Pillow
The PyTorch model
To see the model training process, open a new Jupyter Notebook editor session in CML and open the train_model.ipynb file.
This is easy to do with PyTorch as the library includes the MNIST dataset and full example to train a convolutional neural network on the data set. The original file that was used for this project comes from the PyTorch github page. Getting the data set is very simple:

This training data is used to train and test the model. The PyTorch MNIST data set returns a set of normalized tensors that can be sued to train the model.
The main parts of the code that trains the model is the nn model constructor:

And the training loop:

How quick this runs depends on your CML server and whether you have a GPU. Using a GPU made the model training run about 10x faster for me.
Finally we save the model for use with the model serving API.

In the project sample code, I’ve provided a pre-trained version of the model. Note that you can’t load a model trained on a GPU without have a GPU present.
To train the model, open a Jupyter Notebook and check that you have an engine that includes cuDNN/CUDA (if you want to train using GPU) and profile with at least 4GB of RAM and 1 GPU.
Open the the train_model.ipynb file and re-run all the cells. This will create a new version of the torch_model.pkl file in your local models CML directory.
I’m glossing over a lot of details here as this is more a quick how-to than a detailed review of deep-learning techniques, but fortunately the nicer parts of the internet are full of detailed tutorials and descriptions of how to create neural network using the MNIST dataset. It is the “hello world” of machine learning.
Serving the Model
As with the previous sections, there will be quite a lot of details that will be glossed over. For a detailed overview of how models work on CML, please see the official Cloudera documentation.
The PyTorch Model
The project contains all the files you need to build and deploy the PyTorch model. The CML-build.sh and requirements.txt files manage the library dependencies when the model is deployed. For the PyTorch model, create a new model with the following details:
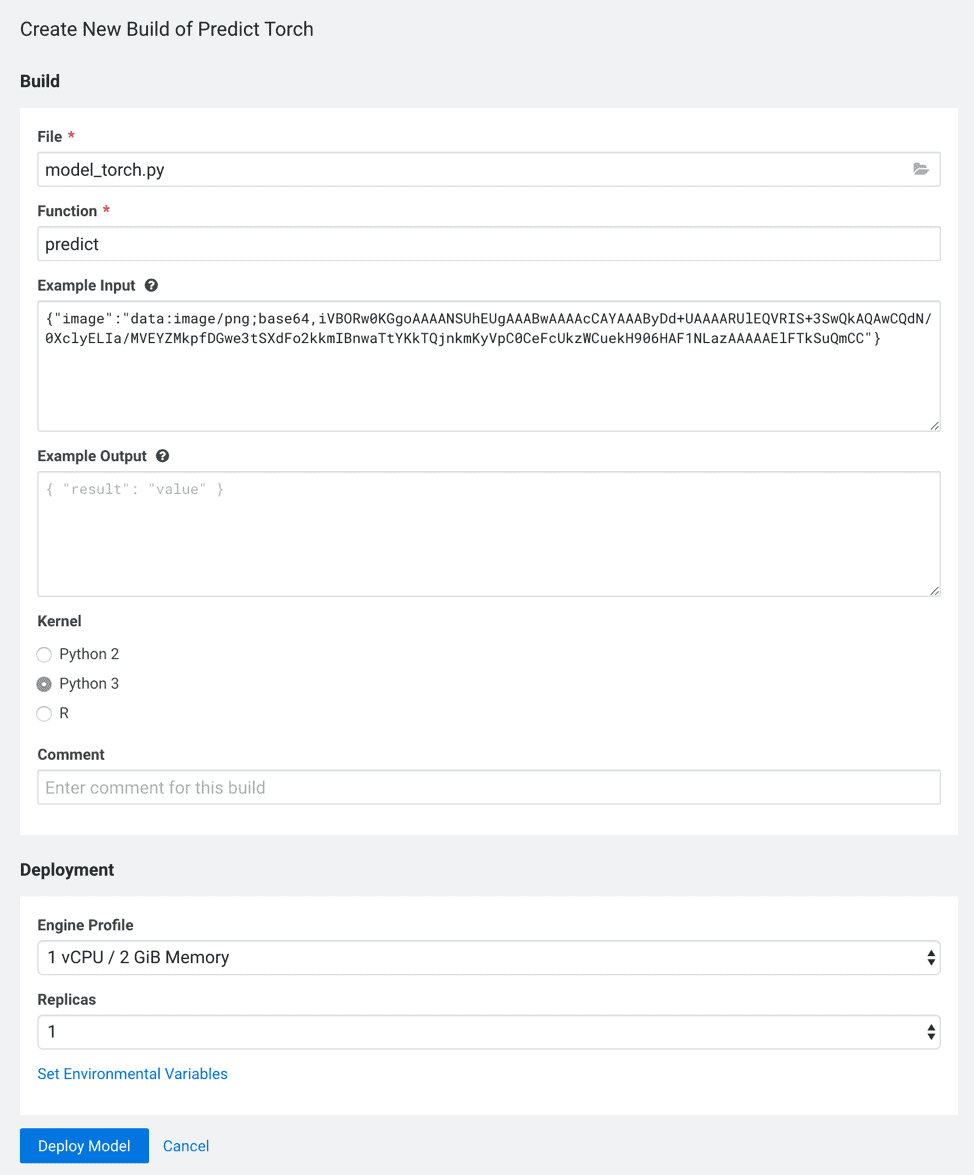
The example input to the model is a base64 encoded version of the hand drawn image. This is explained in more detail in the next section. There would usually be significantly more characters in the image string, but it makes the model test a little hard to read. The sample used here is the character sequence for a of a 5×5 black block.

The file that runs the model is model_torch.py. As the project works with both GPU and non-GPU versions of the PyTorch nn model, you can serve the model without needing to take up any GPU resources on the CML cluster. I didn’t notice any significant performance difference between the GPU and non-GPU based models for model service, but I did not run any timing tests.
The first part of the file creates the class and loads the model that was trained earlier. The image manipulation to get the image into the form the PyTorch model expects uses the Pillow library.

The predict function that is used by the model API in CML will take in the image data and do some image manipulation to get the image data in the form needed for the PyTorch model to make a prediction.
The images is:
- decoded from base64
- blurred slightly at the edges to look more like the MNIST samples
- resized to 28×28
- converted to 8 bit grayscale
- converted to a numpy array and reshaped to the MNIST format
- cast to float and scaled to 0-1 from 0-255
The model then makes a prediction on the input data and returns the most likely predicted digit value i.e. 0-9 as a JSON string.

The Interactive Website
The final part to this project is hosting the web application and this is where we will use the new Applications feature from CML 1.2. The requirements are quite basic: we need some kind of web server that can deliver an html file to a client. Specifically the index.html file in the flask directory.
Serving the Application files
This is where the new CML Applications feature comes in. The Applications will run and serve a long running web based application with a permanent URL. This application is set up so that it can be accessed by any users who have network access to the CML instance. This is useful for creating dashboards or data exploration tools to be used by non CML users.
In this instance, we’re going to serve index.html from the CML server using the Python Flask framework. Open a Python 3 workbench and run the flask_app.py file. The Application does not need a lot of resources for this, so a tiny one (0.5 vCPU 1 GB) will be fine. As you see the flask_app.py file provides a way to sending the index.html file to the user. You could add more complex processing into this file in the flask routes, but for now we just need it to deliver the one file.

To create the application, use the new Applications feature available on the main menu.
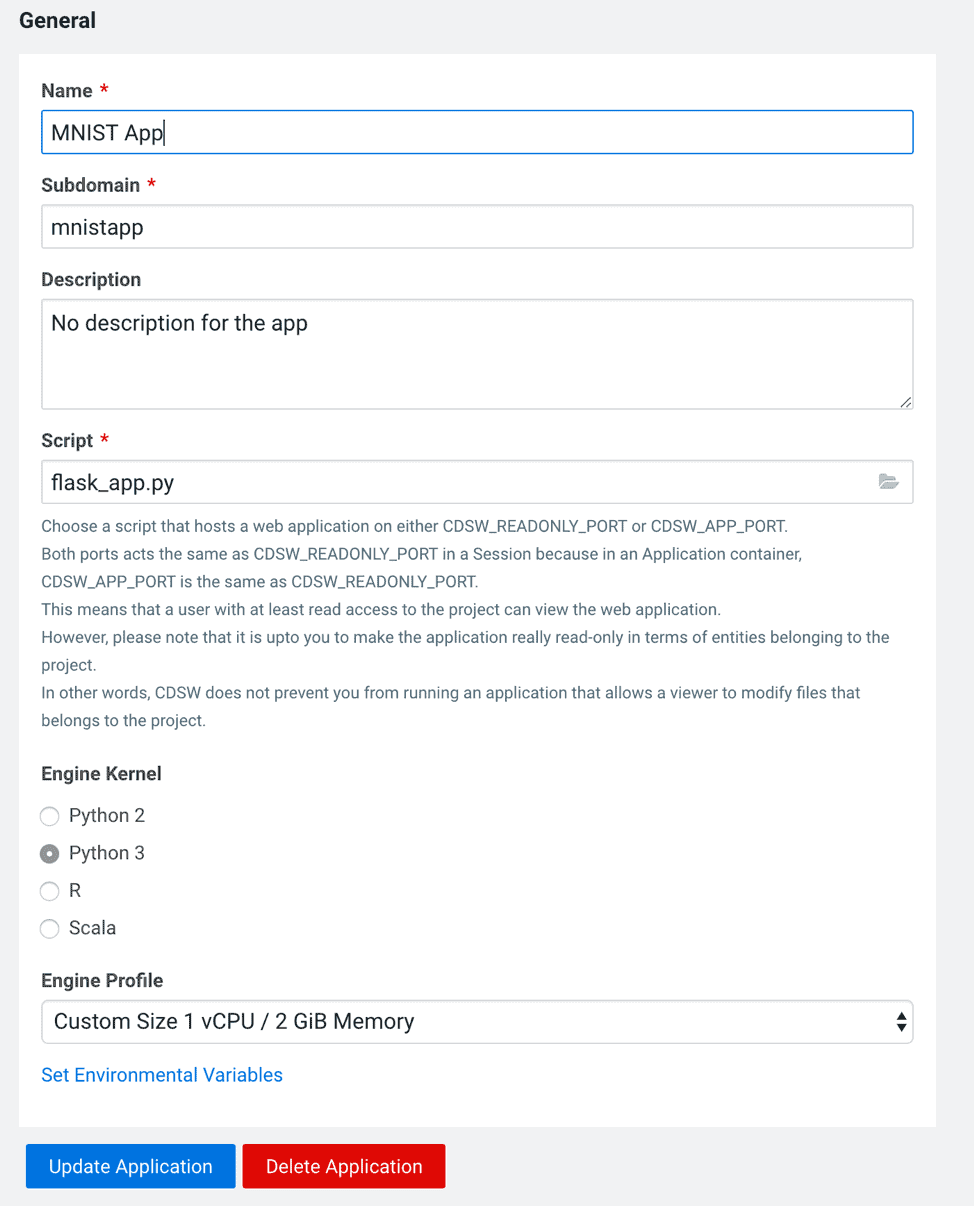
Create a new Application called MNIST App and mnistapp as the subdomain, and copy the settings below.
The Web Application
Now that we have an easy way of serving the index.html file, lets see what it does. The file contains the complete web application and loads the Javascript libraries, the style sheets and makes the Javascript call to the CML model API.
There only two javascript libraries that are used are p5.js and d3.js.

The black drawing block is a <canvas> element that is created by the p5 library. It is very straightforward as p5 does all the complex work. You can change the background and stroke colours in these functions in the html file if you wish.

Once you have drawn the image, it needs to be passed to the CML model API interface. There are some changes you need to make to the javascript in the index.html file in order for this to work. On the CML model overview page, you will find the URL and the accessKey information you need in the sample code.

Replace the corresponding values in the index.html file.

This uses the fetch method to make the POST to the CML model API. The image data is extracted from the <canvas> element using the toDataURL() call which will create a string based data representation of a PNG version of the image. This is the data that will be passed to the CML model API. Once the CML model API has calculated and returned the predicted result, there is a d3.select function that updates the text on the web application to show the end user this result.

Running the Application
Now that everything is in place, you can run the application and test it. Start you application, and click on the launch application link. This will provide you with the permanent URL you can use for anyone to access the application. It will look something like this: https://mnistapp.[your.CML.url]/

Note: This won’t look very good in a normal PC browser window as this is meant to be viewed on a phone or tablet.
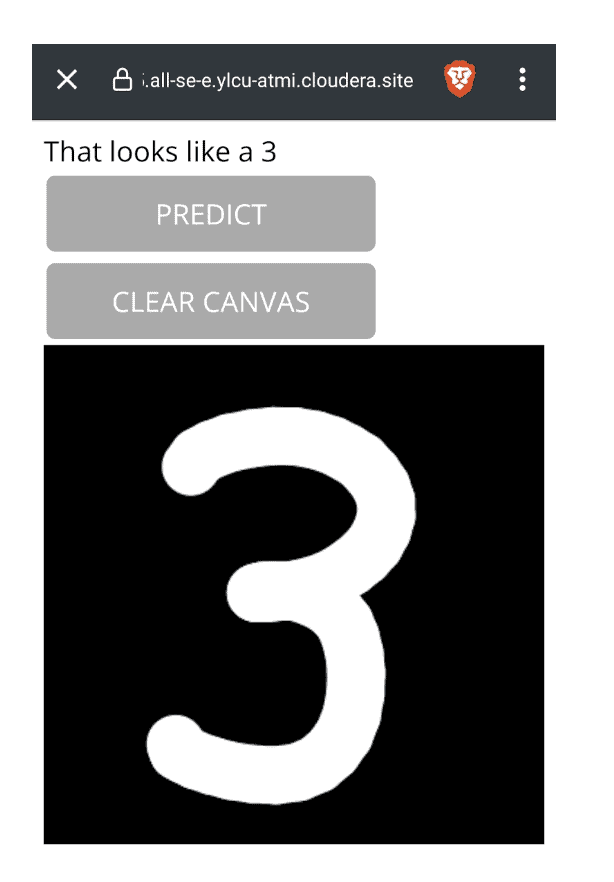
Browse to the link on your phone and you will see the initial screen. Draw a number with your finger in the block, click predict and the application will send the data to the model API, which is serving the model we trained earlier. The model will then predict what digit this is and return the result to the application.

Conclusion
Hopefully this will give you a framework to understand and start building your own interactive machine learning applications. CML has all the tools you need to build this basic demo, but the real benefit comes with starting bring in the other components from the full platform.
There are almost no limitations on what you can achieve.
Learn More
Tune in for our weekly webinar series with technical experts to learn more about Cloudera’s machine learning platform for enterprise data science teams. Each session will feature a product overview including a live demo and Q&A for both end-user, data scientists and administrators. For the webinar series in North America, click here. For the webinar series in Europe, Middle East and Africa, click here.
Editor's Choice

