

Cloudera Search is a highly scalable and flexible search solution based on Apache Solr which enables exploration, discovery and analytics over massive, unstructured and semi-structured datasets (for example logs, emails, dna-strings, claims forms, jpegs, xls sheets, etc). It has been adopted by a large number of Cloudera customers across a wide range of industries for high ROI and SLA-bound workloads, with many of those having strict requirements around security and compliance.
In CDH6.2 we introduce two new features to Cloudera Search relating to document-level security. The first extends this role-based model by adding a conjunctive match capability and the second introduces attribute-based access control to protect documents based on multiple fields and against user attributes retrieved from an attribute store.
Part 1 explored the conjunctive match capability, and this part will explore the attribute-based access control feature.
Attribute Based Access Control
Attribute Based Access Control is defined by NIST as “An access control method where subject requests to perform operations on objects are granted or denied based on assigned attributes of the subject, assigned attributes of the object, environment conditions, and a set of policies that are specified in terms of those attributes and conditions.”
In this model, we are defining a set of policies in the solrconfig.xml file where we are going to construct a set of predicates based on a user’s attributes, which will then be applied to enforce access control against a number of fields defined on each document. Cloudera’s reference architecture is illustrated in Figure 1. It differs from the NIST reference model, in that instead of computing a grant/deny on a per-object basis, we generate predicates and transformations that are then pushed down to our scale-out high-performance execution engines.
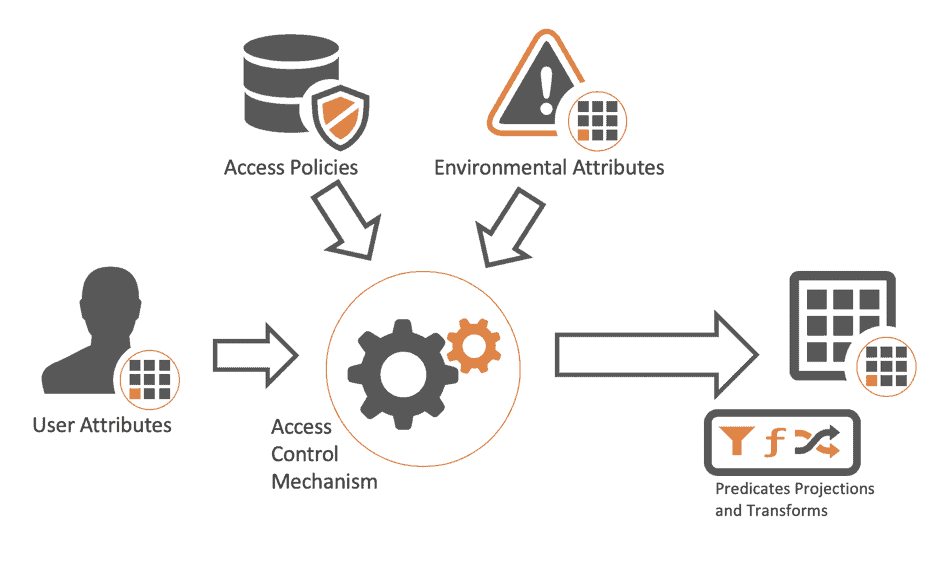
Figure 1: Cloudera’s ABAC Reference Model
In CDH6.2 we are introducing an ABAC model which executes entirely in Cloudera Search, using LDAP as the user attribute store, and with policies defined in the solrconfig.xml file. In future, this will be integrated into Apache Ranger and will eventually include environmental attributes (such as time of day, user geo, organisational readiness, etc).
User Attributes are retrieved from LDAP, where values from one or more user attributes can be mapped to single Solr field, potentially with regex matching being applied. In the case where a memberOf overlay is available (for example Active Directory), the LDAPSource can query groups, and indeed nested groups via recursive traversal of the memberOf attribute (with a configurable maxDepth and cycle detection built in).
Predicates are defined as OR (disjunctive list match), AND (conjunctive list match using the method described above), LTE (less than or equal to) and GTE (greater than or equal to) – the latter two being used for hierarchical security models based on enumerations (for example UNCLASSIFIED through to TOP SECRET in defence).
With this model we can define many predicates to be applied to a single collection based on many attributes, all of which must be satisfied for a user to be granted access to a document.
An example configuration is shown below:
<queryParser name="subset" class="org.apache.solr.handler.component.SubsetQueryPlugin" /> <searchComponent name="queryDocAuthorization" class="org.apache.solr.handler.component.SolrAttrBasedFilter"> <bool name="enabled">true</bool> <str name="andQParser">subset</str> <!-- caching parameters --> <bool name="cache_enabled">true</bool> <long name="cache_ttl_seconds">20</long> <long name="cache_max_size">10</long> <!-- LDAP parameters --> <str name="ldapProviderUrl">ldap://myldapserver.example.com:10389</str> <str name="ldapAuthType">simple</str><!-- can be set to kerberos --> <str name="ldapAdminUser">cn=admin,ou=Users,dc=example,dc=com</str> <str name="ldapAdminPassword"><![CDATA[mypassword]]></str> <str name="ldapBaseDN">dc=example,dc=com</str> <str name="ldapUserSearchFilter"><![CDATA[(uid={0})]]></str> <bool name="ldapNestedGroupsEnabled">true</bool> <str name="ldapRecursiveAttribute">memberOf</str> <int name="ldapMaxRecurseDepth">10</int> <!-- Policy definition: attr->field mappings --> <lst name="field_attr_mappings"> <lst name="orGroupFieldName"> <str name="attr_names">orGroupsAttr,memberOf</str> <str name="filter_type">OR</str> <str name="value_filter_regex">(^[A-Za-z0-9]+$)|(cn=([A-Za-z0-9\-\_]+),)</str> <bool name="permit_empty">true</bool> </lst> <lst name="andGroupFieldName"> <str name="attr_names">andGroupsAttr</str> <str name="filter_type">AND</str> <str name="extra_opts">count_field=andGroupsCount</str> <bool name="permit_empty">true</bool> </lst> <lst name="lteEnumFieldName"> <str name="attr_names">lteAttr</str> <str name="filter_type">LTE</str> <bool name="permit_empty">true</bool> </lst> <lst name="gteEnumFieldName"> <str name="attr_names">gteAttr</str> <str name="filter_type">GTE</str> <bool name="permit_empty">true</bool> </lst> </lst> </searchComponent>
In this example, we first set up the subset query parser (for the AND predicate), configure a cache to ensure that the LDAP server isn’t hit for repeated queries, configure the LDAP connection (including the nested groups feature) and then finally we are defining four predicates, the first of which uses a regular expression to extract the common name from a Distinguished Name.
Example of documents that we can use here would be as follows:
{
id: "document10",
orGroupFieldName: ["managers", "hr"],
andGroupFieldName: ["cldr", "mergerteam"],
andGroupsCount: 2,
gteEnumFieldName: "CONFIDENTIAL",
lteEnumFieldName: "PII Class 1",
text: "This doc has two or groups, two and groups, can been seen by anybody with CONFIDENTIAL or above and has an LTE marking of PII Class 1."
}
{
id: "document11",
orGroupFieldName: ["managers"],
andGroupFieldName: ["hdp", "mergerteam"],
andGroupsCount: 2,
gteEnumFieldName: "OFFICIAL",
lteEnumFieldName: "PII Class 2",
text: "This doc has one or group, two and groups, can been seen by anybody with OFFICIAL or above and has an LTE marking of PII Class 2."
}
{
id: "document12",
orGroupFieldName: ["managers", "hr"],
andGroupFieldName: ["mergerteam"],
andGroupsCount: 1,
gteEnumFieldName: "OFFICIAL",
lteEnumFieldName: "PII Class 3",
text: "This doc has two or groups, one and groups, can been seen by anybody with OFFICIAL or above and has an LTE marking of PII Class 3."
}
Using the example above, we can see the results of this filtering when applied to simple or complex examples. If we turn on the debug flag when a query is run, we can see the additional runtime filters that are generated:
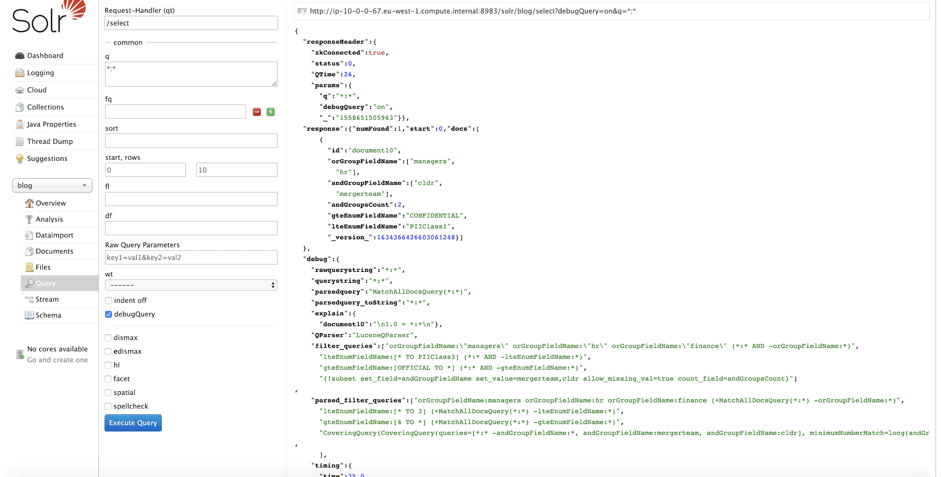
In this case, the filters have prevented us from seeing all documents other than document10.
A more comprehensive set of documentation is attached to jira SENTRY-2482 and there are some working examples in the Apache Sentry project at https://github.com/apache/sentry/tree/master/sentry-tests/sentry-tests-solr/src/test/resources/solr/configsets.
Conclusion
CDH6.2 introduces two new security features for Cloudera Search providing document-level security capabilities to be used in highly complex regulatory or corporate infosec environments, including addressing GDPR requirements. This blog has explored the usage of Attribute Based Access Control for Cloudera Search. To further explore your options for securing your sensitive or PII data on your analytics systems, please speak to your account team or get in touch via the website.
Acknowledgements
SENTRY-2482 was delivered by a multi-functional team, including Hrishikesh Gadre, David Beech, Zsolt Gyulavari, Kalyan Kumar Kalvagadda, Tristan Stevens and Eva Nahari.
Tristan Stevens is a Principal Solutions Architect at Cloudera
Editor's Choice


Hello Tristan,
If I wanted to cite the this article, what reference should I use?
Thanks