

Cloudera Search is a highly scalable and flexible search solution based on Apache Solr which enables exploration, discovery and analytics over massive, unstructured and semi-structured datasets (for example logs, emails, dna-strings, claims forms, jpegs, xls sheets, etc). It has been adopted by a large number of Cloudera customers across a wide range of industries for high ROI and SLA-bound workloads, with many of those having strict requirements around security and compliance.
In CDH 5.1.0 we introduced document-level security for Cloudera Search using Apache Sentry. This model provided a mechanism where user groups could be assigned one or more roles which would then be matched against tokens specified within a Solr document. This simple mechanism meant that it was possible to essentially tag documents in order to control access to them.
As an example, in order to provide a Purpose Based Access Control (PBAC) model in compliance with GDPR Article 6, a document may be tagged according to the purposes that the subject has consented, for example [“marketing“, “product-development“] and this would mean that only users who have either the “marketing” or “product-development” roles (or both) could see the document.
In CDH6.2 we introduce two new features to Cloudera Search relating to document-level security. The first extends this role-based model by adding a conjunctive match capability and the second introduces attribute-based access control to protect documents based on multiple fields and against user attributes retrieved from an attribute store.
In this blog we will explore the conjunctive match capability, and part 2 will explore the attribute-based access control feature.
Conjunctive Match
The CDH5.1 role-based model provided a disjunctive, or OR based predicate – where the user must have token1 or token2 or token3 etc. With conjunctive match we simply ensure that all of the tokens applied to a document must be assigned to the user in order for access to be granted. This is sometimes known as AND based predicates, or AND groups.
This might be used in scenarios where information is limited to extreme intersections of users, for example in Mergers and Acquisitions where you might need to have information that cannot be seen by both parties:
{
id: "document1",
sentry_auth: ["cldr", "mergerteam"],
sentry_auth_count: 2,
text: "Some text that can only be seen by some of the merger team"
}
{
id: "document2",
sentry_auth: ["hdp", "mergerteam"],
sentry_auth_count: 2,
text: "Some text that can only be seen by different members of the merger team"
}
{
id: "document3",
sentry_auth: ["mergerteam"],
sentry_auth_count: 1,
text: "All members of the merger team can see this"
}
As with the existing document-level security in Cloudera Search we control this using the solrconfig.xml file, and then map users to roles using Apache Sentry:
<queryParser name="subset" class="org.apache.solr.handler.component.SubsetQueryPlugin" /> <searchComponent name="queryDocAuthorization" class="org.apache.solr.handler.component.QueryDocAuthorizationComponent"> <bool name="enabled">true</bool> <str name="matchMode">CONJUNCTIVE</str> <str name="sentryAuthField">sentry_auth</str> <str name="tokenCountField">sentry_auth_count</str> <str name="allRolesToken">anybody</str> <str name="allow_missing_val">true</str> <str name="qParser">subset</str> </searchComponent>
To make the conjunctive match capability work, we’re introducing three new things:
- A matchMode attribute, which we set to CONJUNCTIVE
- A tokenCountField which needs to specify the minimum number of values that the user needs to match on a per-document basis
- We define the Subset query, which in this instance we’ve called “subset”, which is the default name.
The allRolesToken is a field which is implicitly given to all users (for example as a default role), and similarly the allow_missing_val capabilities defines whether permission should be granted to documents who do not have a value for the sentryAuthField.
Running a query against this collection with the debug attribute set shows us the actual filter that is being appended onto the query as a predicate:
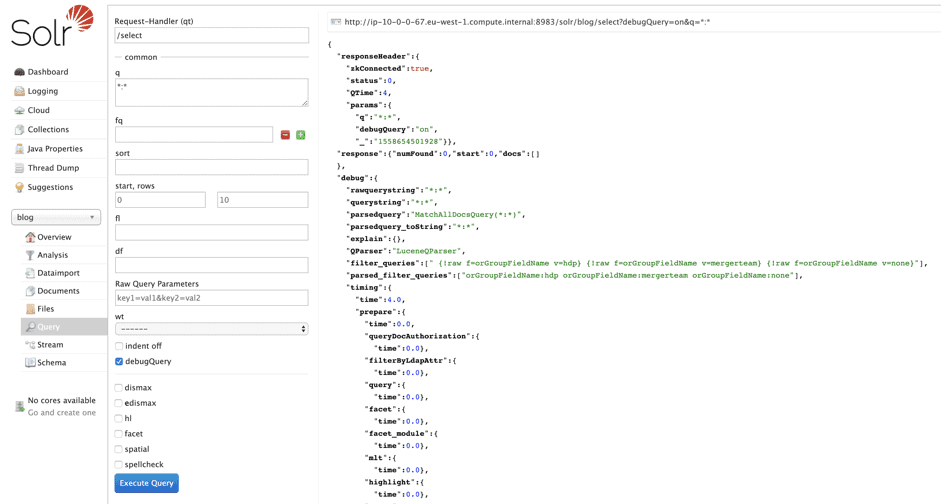
Using the debug attribute, it can sometimes be slightly easier to understand why specific documents are or are not being filtered.
Conclusion
This blog introduces the conjunctive match feature delivered for Cloudera Search in CDH6.2. Part 2 will explore the attribute-based access control feature.
Acknowledgements
SENTRY-2482 was delivered by a multi-functional team, including Hrishikesh Gadre, David Beech, Zsolt Gyulavari, Kalyan Kumar Kalvagadda, Tristan Stevens and Eva Nahari.
Editor's Choice

