

User-defined functions (UDFs) are a key feature of most SQL environments to extend the system’s built-in functionality. UDFs allow developers to enable new functions in higher level languages such as SQL by abstracting their lower level language implementations. Apache Spark is no exception, and offers a wide range of options for integrating UDFs with Spark SQL workflows.
In this blog post, we’ll review simple examples of Apache Spark UDF and UDAF (user-defined aggregate function) implementations in Python, Java and Scala. We’ll also discuss the important UDF API features and integration points, including their current availability between releases. To wrap up, we’ll touch on some of the important performance considerations that you should be aware of when choosing to leverage UDFs in your application.
Spark SQL UDFs
UDFs transform values from a single row within a table to produce a single corresponding output value per row. For example, most SQL environments provide an UPPER function returning an uppercase version of the string provided as input.
Custom functions can be defined and registered as UDFs in Spark SQL with an associated alias that is made available to SQL queries. As a simple example, we’ll define a UDF to convert temperatures in the following JSON data from degrees Celsius to degrees Fahrenheit:
{"city":"St. John's","avgHigh":8.7,"avgLow":0.6}
{"city":"Charlottetown","avgHigh":9.7,"avgLow":0.9}
{"city":"Halifax","avgHigh":11.0,"avgLow":1.6}
{"city":"Fredericton","avgHigh":11.2,"avgLow":-0.5}
{"city":"Quebec","avgHigh":9.0,"avgLow":-1.0}
{"city":"Montreal","avgHigh":11.1,"avgLow":1.4}
...
https://github.com/curtishoward/sparkudfexamples/blob/master/data/temperatures.json
The sample code below registers our conversion UDF using the SQL alias CTOF, then makes use of it from a SQL query to convert the temperatures for each city. For brevity, creation of the SQLContext object and other boilerplate code is omitted, and links are provided below each code snippet to the full listing.
Python
df = sqlContext.read.json("temperatures.json")
df.registerTempTable("citytemps")
# Register the UDF with our SQLContext
sqlContext.registerFunction("CTOF", lambda degreesCelsius: ((degreesCelsius * 9.0 / 5.0) + 32.0))
sqlContext.sql("SELECT city, CTOF(avgLow) AS avgLowF, CTOF(avgHigh) AS avgHighF FROM citytemps").show()
https://github.com/curtishoward/sparkudfexamples/tree/master/python-udf
Scala
val df = sqlContext.read.json("temperatures.json")
df.registerTempTable("citytemps")
// Register the UDF with our SQLContext
sqlContext.udf.register("CTOF", (degreesCelcius: Double) => ((degreesCelcius * 9.0 / 5.0) + 32.0))
sqlContext.sql("SELECT city, CTOF(avgLow) AS avgLowF, CTOF(avgHigh) AS avgHighF FROM citytemps").show()
https://github.com/curtishoward/sparkudfexamples/tree/master/scala-udf
Java
DataFrame df = sqlContext.read().json("temperatures.json");
df.registerTempTable("citytemps");
// Register the UDF with our SQLContext
sqlContext.udf().register("CTOF", new UDF1<Double, Double>() {
@Override
public Double call(Double degreesCelcius) {
return ((degreesCelcius * 9.0 / 5.0) + 32.0);
}
}, DataTypes.DoubleType);
sqlContext.sql("SELECT city, CTOF(avgLow) AS avgLowF, CTOF(avgHigh) AS avgHighF FROM citytemps").show();
https://github.com/curtishoward/sparkudfexamples/tree/master/java-udf
Note that Spark SQL defines UDF1 through UDF22 classes, supporting UDFs with up to 22 input parameters. Our example above made use of UDF1 to handle our single temperature value as input. Without updates to the Apache Spark source code, using arrays or structs as parameters can be helpful for applications requiring more than 22 inputs, and from a style perspective this may be preferred if you find yourself using UDF6 or higher.
Spark SQL UDAF functions
User-defined aggregate functions (UDAFs) act on multiple rows at once, return a single value as a result, and typically work together with the GROUP BY statement (for example COUNT or SUM). To keep this example straightforward, we will implement a UDAF with alias SUMPRODUCT to calculate the retail value of all vehicles in stock grouped by make, given a price and an integer quantity in stock in the following data:
{"Make":"Honda","Model":"Pilot","RetailValue":32145.0,"Stock":4}
{"Make":"Honda","Model":"Civic","RetailValue":19575.0,"Stock":11}
{"Make":"Honda","Model":"Ridgeline","RetailValue":42870.0,"Stock":2}
{"Make":"Jeep","Model":"Cherokee","RetailValue":23595.0,"Stock":13}
{"Make":"Jeep","Model":"Wrangler","RetailValue":27895.0,"Stock":4}
{"Make":"Volkswagen","Model":"Passat","RetailValue":22440.0,"Stock":2}
https://github.com/curtishoward/sparkudfexamples/blob/master/data/inventory.json
Apache Spark UDAF definitions are currently supported in Scala and Java by the extending UserDefinedAggregateFunction class. Once defined, we can instantiate and register our SumProductAggregateFunction UDAF object under the alias SUMPRODUCT and make use of it from a SQL query, much in the same way that we did for our CTOF UDF in the previous example.
Scala
object ScalaUDAFExample {
// Define the SparkSQL UDAF logic
private class SumProductAggregateFunction extends UserDefinedAggregateFunction {
// Define the UDAF input and result schema's
def inputSchema: StructType = // Input = (Double price, Long quantity)
new StructType().add("price", DoubleType).add("quantity", LongType)
def bufferSchema: StructType = // Output = (Double total)
new StructType().add("total", DoubleType)
def dataType: DataType = DoubleType
def deterministic: Boolean = true // true: our UDAF's output given an input is deterministic
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0, 0.0) // Initialize the result to 0.0
}
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
val sum = buffer.getDouble(0) // Intermediate result to be updated
val price = input.getDouble(0) // First input parameter
val qty = input.getLong(1) // Second input parameter
buffer.update(0, sum + (price * qty)) // Update the intermediate result
}
// Merge intermediate result sums by adding them
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getDouble(0) + buffer2.getDouble(0))
}
// THe final result will be contained in 'buffer'
def evaluate(buffer: Row): Any = {
buffer.getDouble(0)
}
}
def main (args: Array[String]) {
val conf = new SparkConf().setAppName("Scala UDAF Example")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val testDF = sqlContext.read.json("inventory.json")
testDF.registerTempTable("inventory")
// Register the UDAF with our SQLContext
sqlContext.udf.register("SUMPRODUCT", new SumProductAggregateFunction)
sqlContext.sql("SELECT Make, SUMPRODUCT(RetailValue,Stock) AS InventoryValuePerMake FROM inventory GROUP BY Make").show()
}
}
https://github.com/curtishoward/sparkudfexamples/tree/master/scala-udaf
Additional UDF Support in Apache Spark
Spark SQL supports integration of existing Hive (Java or Scala) implementations of UDFs, UDAFs and also UDTFs. As a side note UDTFs (user-defined table functions) can return multiple columns and rows – they are out of scope for this blog, although we may cover them in a future post. Integrating existing Hive UDFs is a valuable alternative to re-implementing and registering the same logic using the approaches highlighted in our earlier examples, and is also helpful from a performance standpoint in PySpark as will be discussed in the next section. Hive functions can be accessed from a HiveContext by including the JAR file containing the Hive UDF implementation using spark-submit’s –jars option, and by then declaring the function using CREATE TEMPORARY FUNCTION (as would be done in Hive[1] to include a UDF), for example:
Hive UDF definition in Java
package com.cloudera.fce.curtis.sparkudfexamples.hiveudf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class CTOF extends UDF {
public Double evaluate(Double degreesCelsius) {
return ((degreesCelsius * 9.0 / 5.0) + 32.0);
}
}
https://github.com/curtishoward/sparkudfexamples/tree/master/hive-udf
Hive UDF access from Python
df = sqlContext.read.json("temperatures.json")
df.registerTempTable("citytemps")
# Register our Hive UDF
sqlContext.sql("CREATE TEMPORARY FUNCTION CTOF AS 'com.cloudera.fce.curtis.sparkudfexamples.hiveudf.CTOF'")
sqlContext.sql("SELECT city, CTOF(avgLow) AS avgLowF, CTOF(avgHigh) AS avgHighF FROM citytemps").show()
https://github.com/curtishoward/sparkudfexamples/tree/master/hive-udf
Note that Hive UDFs can only be invoked using Apache Spark’s SQL query language – in other words, they cannot be used with the Dataframe API’s domain-specific-language (DSL) as is the case for the UDF and UDAF functions we implemented in the examples above.
Alternatively, UDFs implemented in Scala and Java can be accessed from PySpark by including the implementation jar file (using the –jars option with spark-submit) and then accessing the UDF definition through the SparkContext object’s private reference to the executor JVM and underlying Scala or Java UDF implementations that are loaded from the jar file. An excellent talk[2] by Holden Karau includes a discussion of this method. Note that some of the Apache Spark private variables used in this technique are not officially intended for end-users. This also provides the added benefit of allowing UDAFs (which currently must be defined in Java and Scala) to be used from PySpark as the example below demonstrates using the SUMPRODUCT UDAF that we defined in Scala earlier:
Scala UDAF definition
object ScalaUDAFFromPythonExample {
// … UDAF as defined in our example earlier ...
}
// This function is called from PySpark to register our UDAF
def registerUdf(sqlCtx: SQLContext) {
sqlCtx.udf.register("SUMPRODUCT", new SumProductAggregateFunction)
}
}
https://github.com/curtishoward/sparkudfexamples/tree/master/scala-udaf-from-python
Scala UDAF from PySpark
df = sqlContext.read.json("inventory.json")
df.registerTempTable("inventory")
scala_sql_context = sqlContext._ssql_ctx
scala_spark_context = sqlContext._sc
scala_spark_context._jvm.com.cloudera.fce.curtis.sparkudfexamples.scalaudaffrompython.ScalaUDAFFromPythonExample.registerUdf(scala_sql_context)
sqlContext.sql("SELECT Make, SUMPRODUCT(RetailValue,Stock) AS InventoryValuePerMake FROM inventory GROUP BY Make").show()
https://github.com/curtishoward/sparkudfexamples/tree/master/scala-udaf-from-python
UDF-related features are continuously being added to Apache Spark with each release. Version 2.0 for example adds support for UDFs in R. As a point of reference, the table below summarizes versions in which the key features discussed so far in this blog were introduced:
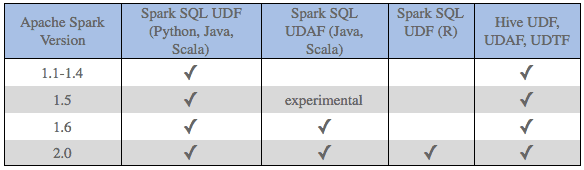
table summarizing versions in which the key features discussed so far in this blog were introduced
Performance Considerations
It’s important to understand the performance implications of Apache Spark’s UDF features. Python UDFs for example (such as our CTOF function) result in data being serialized between the executor JVM and the Python interpreter running the UDF logic – this significantly reduces performance as compared to UDF implementations in Java or Scala. Potential solutions to alleviate this serialization bottleneck include:
- Accessing a Hive UDF from PySpark as discussed in the previous section. The Java UDF implementation is accessible directly by the executor JVM. Note again that this approach only provides access to the UDF from the Apache Spark’s SQL query language.
- Making use of the approach also shown to access UDFs implemented in Java or Scala from PySpark, as we demonstrated using the previously defined Scala UDAF example.
In general, UDF logic should be as lean as possible, given that it will be called for each row. As an example, a step in the UDF logic taking 100 milliseconds to complete will quickly lead to major performance issues when scaling to 1 billion rows.
Another important component of Spark SQL to be aware of is the Catalyst query optimizer. Its capabilities are expanding with every release and can often provide dramatic performance improvements to Spark SQL queries; however, arbitrary UDF implementation code may not be well understood by Catalyst (although future features[3] which analyze bytecode are being considered to address this). As such, using Apache Spark’s built-in SQL query functions will often lead to the best performance and should be the first approach considered whenever introducing a UDF can be avoided. Advanced users looking to more tightly couple their code with Catalyst can refer to the following talk[4] by Chris Fregly’s using …Expression.genCode to optimize UDF code, as well the new Apache Spark 2.0 experimental feature[5] which provides a pluggable API for custom Catalyst optimizer rules.
Conclusion
UDFs can be a helpful tool when Spark SQL’s built-in functionality needs to be extended. This blog post provided a walk-through of UDF and UDAF implementation and discussed integration steps to make use of existing Java Hive UDFs inside of Spark SQL. UDFs can be implemented in Python, Scala, Java and (in Spark 2.0) R, and UDAFs in Scala and Java. When using UDFs with PySpark, data serialization costs must be factored in, and the two strategies discussed above to address this should be considered. Finally, we touched on Spark SQL’s Catalyst optimizer and the performance reasons for sticking to the built-in SQL functions first before introducing UDFs in your solutions.
References
- https://www.cloudera.com/documentation/enterprise/5-8-x/topics/cm_mc_hive_udf.html#concept_wsd_nms_lr
- https://spark-summit.org/2016/events/getting-the-best-performance-with-pyspark/
- https://issues.apache.org/jira/browse/SPARK-14083
- http://www.slideshare.net/cfregly/advanced-apache-spark-meetup-project-tungsten-nov-12-2015
- https://issues.apache.org/jira/browse/SPARK-9843
Code
https://github.com/curtishoward/sparkudfexamples
CDH Version: 5.8.0 (Apache Spark 1.6.0)
Editor's Choice

