

Our thanks to Don Drake (@dondrake), an independent technology consultant who is currently working at Allstate Insurance, for the guest post below about his experiences comparing use of the Apache Avro and Apache Parquet file formats with Apache Spark.
Over the last few months, numerous hallway conversations, informal discussions, and meetings have occurred at Allstate about the relative merits of different file formats for data stored in Apache Hadoop—including CSV, JSON, Apache Avro, and Apache Parquet. Text representations (CSV and JSON) are dismissed by most people out of hand, which leave Avro and Parquet as the main contenders.
The longer these debates went on, the more I realized that many personal opinions on this subject are based on hearsay. For example, one format is often considered to be “better” if you are looking at all the data, while another performs better if you are looking at a subset of columns.
Like any good engineer, I thought it would be worthwhile to put both of these file formats through a few performance tests to find out the truth. In this post, I’ll describe what I found.
Test Datasets
I thought it was important to utilize real-world data sets so we would have a good idea of what to expect when running jobs in a production environment. I also thought it important to simulate actual querying or processing. In other words, doing simple row counts is unsatisfactory for a good comparison.
Among datasets that I had used recently, I found two that would be a good basis for testing. The first one, which I call the “narrow” dataset, comprises only three columns but contains 82.8 million rows in CSV format with a file size of 3.9GB. The other one, known as the “wide” dataset, comprises 103 columns with 694 million rows in CSV format with a file size of 194GB. I thought this approach would provide insights about whether one file format performs better on a larger or smaller data set.
Test Methodology
I chose Apache Spark 1.6 as my processing workhorse to put both of these file formats through their paces. (Spark supports Parquet out of the box, and also has good plugins available for Avro and CSV.) These jobs were executed on a CDH 5.5.x cluster with 100+ data nodes.
I was interested to see how each format performs during different execution phases, such as creating a dataset, simple querying of data, non-trivial query, time to process/query the entire dataset, and the disk space utilized for the same dataset.
I ran each test in a spark-shell with the same configuration between wide/narrow tests—excepting that the narrow table requested 50 executors, while the wide table requested 500 executors. The :paste mode in spark-shell was a lifesaver in that I could paste the Scala code right into the REPL without worrying about multi-line commands confusing the interpreter.
#!/bin/bash -x # Drake export HADOOP_CONF_DIR=/etc/hive/conf export SPARK_HOME=/home/drake/coolstuff/spark/spark-1.6.0-bin-hadoop2.6 export PATH=$SPARK_HOME/bin:$PATH # use Java8 export JAVA_HOME=/usr/java/latest export PATH=$JAVA_HOME/bin:$PATH # NARROW NUM_EXECUTORS=50 # WIDE NUM_EXECUTORS=500 spark-shell —master yarn-client \ —conf spark.eventLog.enabled=true \ —conf spark.eventLog.dir=hdfs://nameservice1/user/spark/applicationHistory \ —conf spark.yarn.historyServer.address=http://yarnhistserver.allstate.com:18088 \ —packages com.databricks:spark-csv_2.10:1.3.0,com.databricks:spark-avro_2.10:2.0.1 \ —driver-memory 4G \ —executor-memory 2G \ —num-executors $NUM_EXECUTORS \
While each query was running, I would utilize the Job tab in the Spark web UI to monitor the time it took to complete, which I then documented. I repeated each test three times and recorded the average of the three trials. The narrow tests were run on a relatively busy (non-idle) cluster and the wide tests were run on an idle cluster (not intentionally, but rather due to the status of the cluster when I had time to execute the jobs).
Data Pre-Processing
When reading in the narrow CSV dataset, I did not infer the schema but I did convert one column from a timestamp string to a Timestamp data type. The timings for that conversion were not included in my results as this step was not related to the file-format comparison.
When reading in the wide CSV file, I did infer the schema, but any processing time needed to do that was similarly not included in my results as it reflects data preparation time and nothing more.
Looking Forward to a Date with Avro!
I created and tested the queries used before I ever started recording the times. I was surprised to learn while testing my Avro-based queries that saving an Avro file with a Timestamp data type is impossible. In fact, Avro v1.7.x does not support the Date nor Timestamp data types.
Narrow Results
The first test is the time it takes to create the narrow version of the Avro and Parquet file after it has been read into a DataFrame (three columns, 83.8 million rows). The Avro time was just 2 seconds faster on average, so the results were similar.
These charts show the execution time in seconds (lower numbers are better).
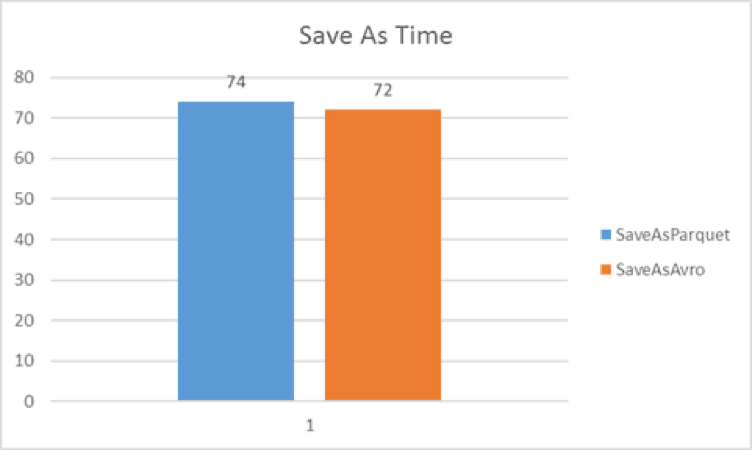
Test Case 1 – Creating the narrow dataset
The next test is a simple row count on the narrow data set (three columns, 83.8 million rows). The CSV count is shown just for comparison and to dissuade you from using uncompressed CSV in Hadoop. Avro and Parquet performed the same in this simple test.
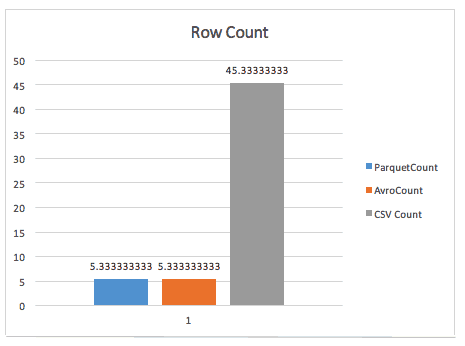
Test Case 2 – Simple row count (narrow)
The GROUP BY query performs a more complex query on a subset of the columns. One of the columns in this dataset is a timestamp, and I wanted to sum the replacement_cost by day (not time). Since Avro does not support Date/Timestamp, I had to tweak the query to get the same results.
Parquet query:
val sums = sqlContext.sql("""select to_date(precise_ts) as day, sum(replacement_cost)
from narrow_parq
group by to_date(precise_ts)
""")
Avro query:
val a_sums = sqlContext.sql("""select to_date(from_unixtime(precise_ts/1000)) as day, sum(replacement_cost)
from narrow_avro
group by to_date(from_unixtime(precise_ts/1000))
""")
The results show Parquet query is 2.6 times faster than Avro.
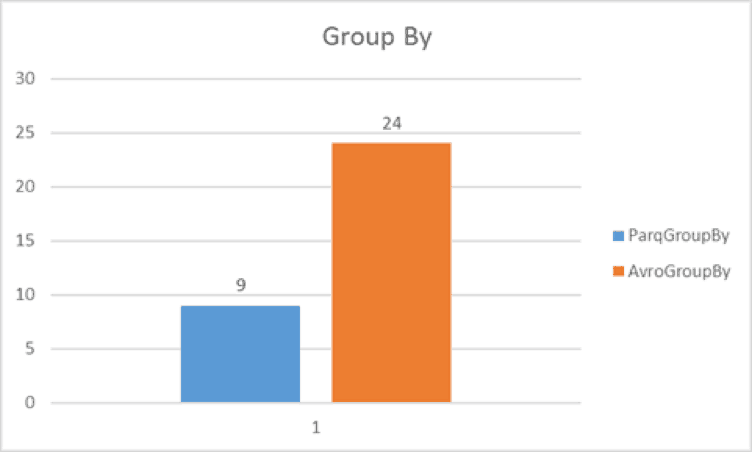
Test Case 3 – GROUP BY query (narrow)
Next, I called a .map() on our DataFrame to simulate processing the entire dataset. The work performed in the map simply counts the number of columns present in each row and the query finds the distinct number of columns.
def numCols(x: Row): Int = {
x.length
}
val numColumns = narrow_parq.rdd.map(numCols).distinct.collect
This is not a query that would be run in any real environment, but it forces processing all of the data. Again, Parquet is almost 2x faster than Avro.
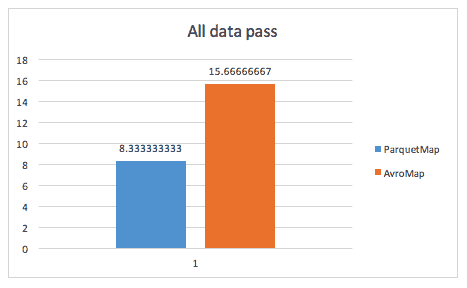 Test Case 4 – Processing all narrow data
Test Case 4 – Processing all narrow data
The last comparison is the amount of disk space used. This chart shows the file size in bytes (lower numbers are better). The job was configured so Avro would utilize Snappy compression codec and the default Parquet settings were used.
Parquet was able to generate a smaller dataset than Avro by 25%.
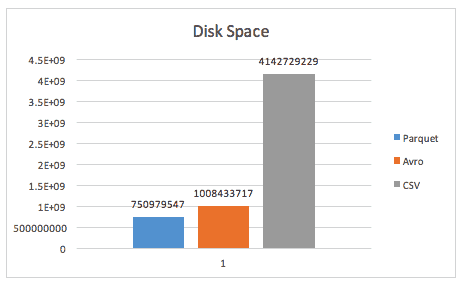
Test Case 5 – Disk space analysis (narrow)
Wide Results
I performed similar queries against a much larger “wide” dataset. As a reminder, this dataset has 103 columns with 694 million rows and is 194GB in size.
The first test is the time to save the wide dataset in each format. Parquet was faster than Avro in each trial.
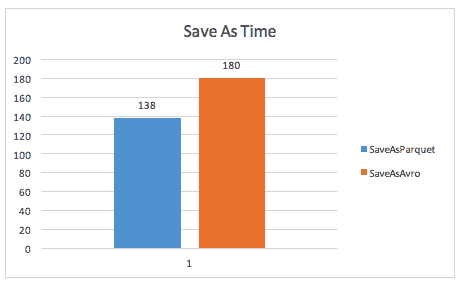
Test Case 1 – Creating the wide dataset
The row-count results on this dataset show Parquet clearly breaking away from Avro, with Parquet returning the results in under 3 seconds.
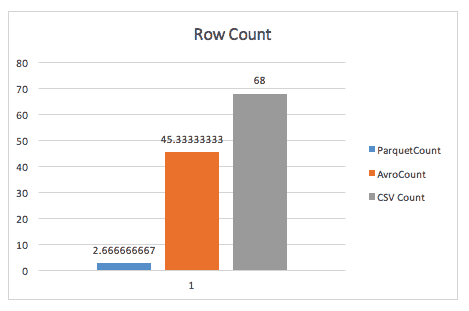
Test Case 2 – Simple row count (wide)
The more complicated GROUP BY query on this dataset shows Parquet as the clear leader.
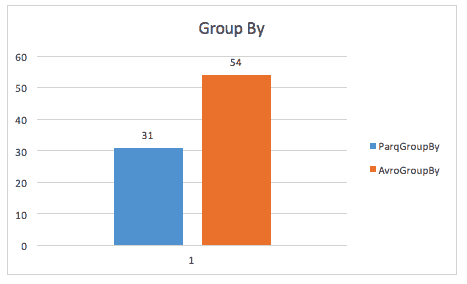
Test Case 3 – GROUP BY query (wide)
The map() against the entire dataset again shows Parquet as the clear leader.
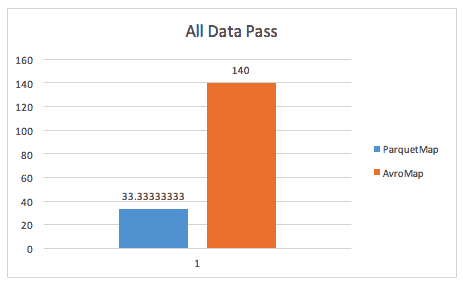
Test Case 4 – Processing all wide data
The final test, disk space results, are quite impressive for both formats: With Parquet, the 194GB CSV file was compressed to 4.7GB; and with Avro, to 16.9GB. That reflects an amazing 97.56% compression ratio for Parquet and an equally impressive 91.24% compression ratio for Avro.
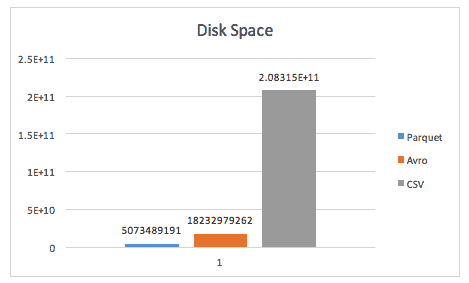
Test Case 5 – Disk space analysis (wide)
Conclusion
Overall, Parquet showed either similar or better results on every test. The query-performance differences on the larger datasets in Parquet’s favor are partly due to the compression results; when querying the wide dataset, Spark had to read 3.5x less data for Parquet than Avro. Avro did not perform well when processing the entire dataset, as suspected.
When it comes to choosing Hadoop file format, there are many factors involved—such as integrating with third-party applications, schema evolution requirements, data type availability, and performance. But if performance matters the most to you, the tests above show that Parquet would be the format to choose.
Editor's Choice


Thanks for the great piece. As an IT Expert, please let me know how to proxypass in apache?