

One of the core principles that guides Cloudera and everything we do is a commitment to the open source community. As the entire Cloudera Data Platform is built on open source projects, we find it crucial to participate in and contribute back to the community. Applied ML prototypes are one of the ways that we accomplish this.
Applied ML Prototypes (AMPs) are fully built end-to-end data science solutions that allow data scientists to go from an idea to a fully working machine learning model in a fraction of the time. AMPs provide an end-to-end framework for building, deploying, and monitoring business-ready ML applications instantly. AMPs are available to deploy with a single click in Cloudera Machine Learning (CML), but every AMP is also available to the public as a public GitHub repository.
For the Cloudera and AMD Applied Machine Learning Prototype Hackathon, competitors were tasked with creating their own unique AMP for one of five categories (Sports and Entertainment, Environment, Business and Economy, Society, and Open Innovation). As you can tell, we left the guidance pretty open ended. This was a deliberate choice because we wanted to encourage competitors to work on whatever project their data hearts desired.
We had over 150 teams register to participate, and from those we selected nine teams as finalists. The final nine teams were given access to their own CML instance running on Amazon EC2 M6a instances powered by 3rd Gen AMD EPYC™, and three weeks to develop their prototypes. These general-purpose M6a instances are designed specifically for balanced compute, memory and networking needs and deliver up to 10% lower cost versus comparable instances. What the competing participants delivered in the end astounded our team of judges, and they certainly didn’t make it easy to select a winner. However, after the dust settled, we are happy to share the following three winning Applied ML Prototypes.
First Place: Forecasting Evapotranspiration With Kats and Prophet
Danika Gupta’s AMP checked all the boxes for the judges (see GitHub repository). It was a perfect example of everything that an AMP should be: a novel application of ML to a real-world problem, with well-written code, and a clean web application to communicate the results.
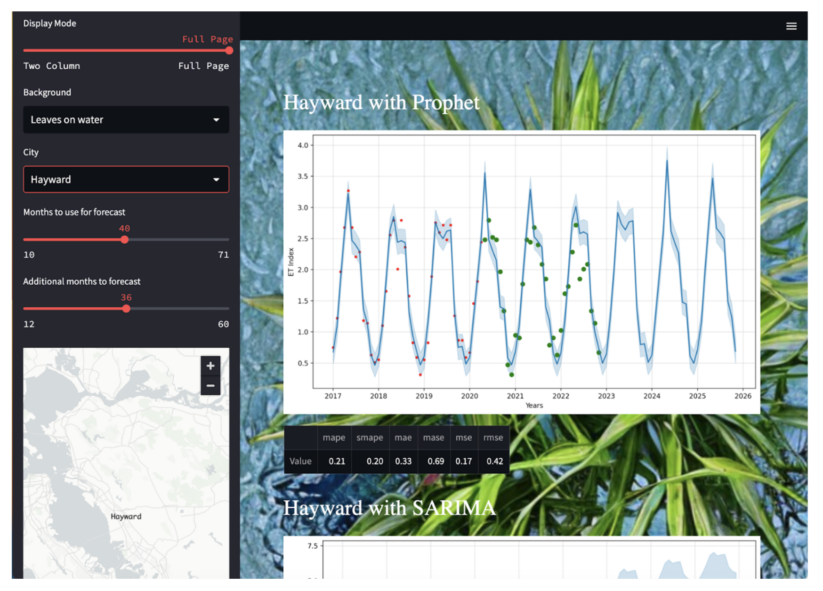
The project was aimed at helping make better water management decisions based on long-range forecasts of evapotranspiration (ET), which is an assessment of the release of water by evaporation from soil and transpiration from plants.
Using OpenET, a publicly accessible database of ET data assessed from satellite imagery, this project leverages forecasting models from the Kats library to create ET predictions for 10 cities in the California Bay Area. The accompanying web application was built with Streamlit, it allows users to select one of the 10 cities on a map and then view the historical ET data and predictions from each model for that city.
Second Place: Art Sale Price Prediction Model
Of the winning submissions, this AMP was the lone project worked on by a team (GitHub repository). Ishaan Poojari, Ge Jin, Idan Lau, and Jeffrey Lin are all students from NYU. For their AMP, they wanted to see if they could get into the New York art appraisal scene with their own ML backed art sale price predictor.
To accomplish the task, the team leveraged an ensemble method of combining predictions from a numerical and a computer vision model to accurately predict the price that a piece of art would sell at. For the numerical model they used a premade data set on Kaggle with art prices and other features from over the years to train a random forest model, and for the computer vision model they used a CNN from the TensorFlow Keras API on imagery downloaded from Sotheby’s.
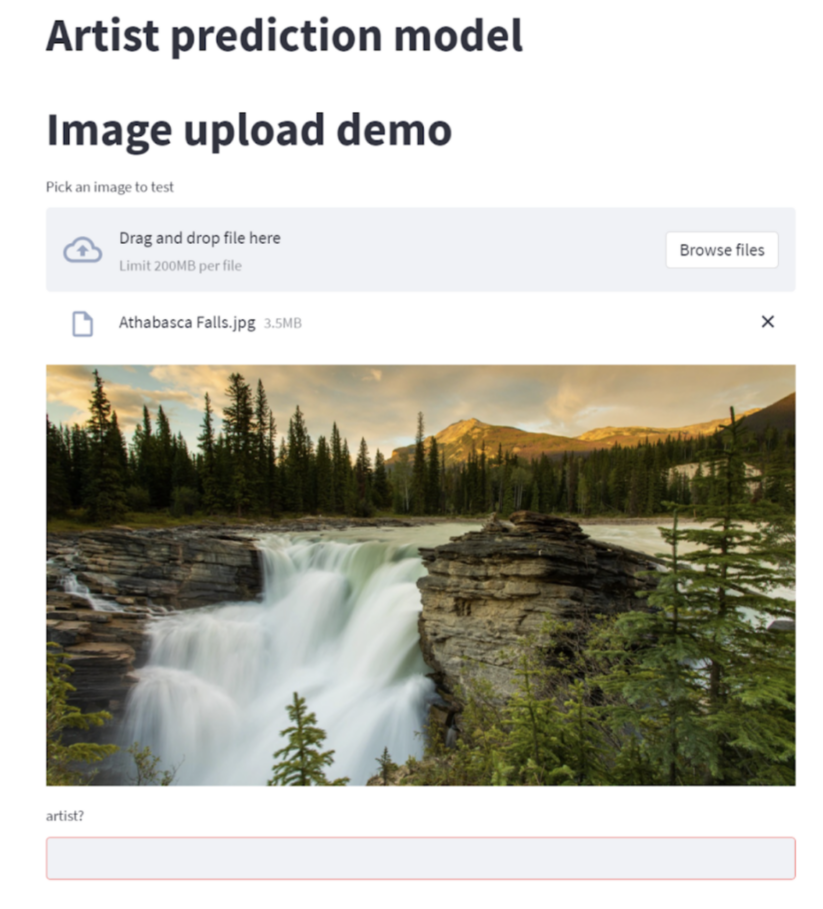
Finally, to make their model accessible to the masses, they created a web application that allows users to upload an image and add some information about the piece of art and the artist that created it. The application will then provide a prediction of the price at which that piece of art would be sold for.
Third Place: Automatic Code Commenting
This AMP really speaks to my heart. What is the one thing that every developer hates? Going through and commenting their code! Okay, maybe some of us enjoy it, but the rest of us slackers are going to love this AMP.
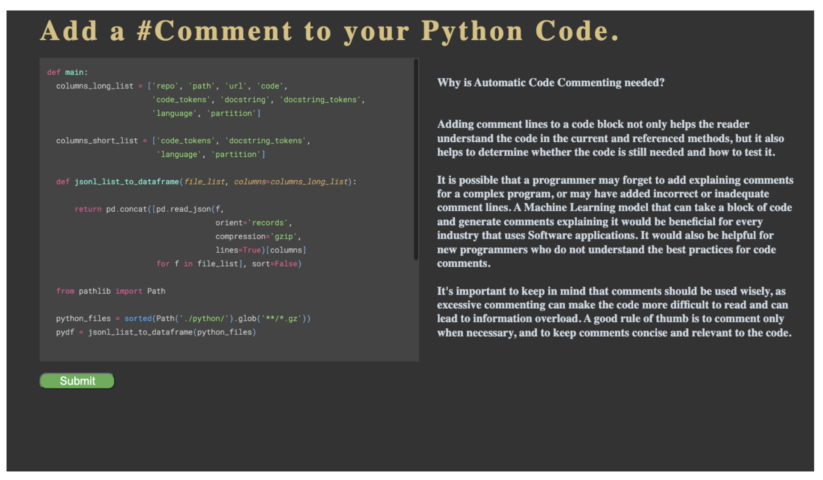
Narendra Gangwani developed their AMP (see GitHub repository) to make the lives of developers everywhere easier, with a web application that allows you to enter the text of a Python function, and have accurate and descriptive comments with proper spacing added directly into the text.
The magic behind the scenes of the app is accomplished through an attention-based pre-trained transformer model (like BERT) that has been tuned with a sequence-to-sequence data set, with code-comment pairs for Python programming language.
What’s Next
In the coming months we will be incorporating these new projects into our official AMP Catalog, making them deployable with a single click for Cloudera customers, and their source code readily available via public GitHub repositories.
If you missed participating in this hackathon, but would like to take a crack at creating your own winning submission, follow Cloudera on LinkedIn and be on a lookout for the next AMP Hackathon later this year.
To learn more about how Applied ML Prototypes can reduce your data science team’s time-to-value, visit our AMP practitioner page.
If you’d like to learn more about AMD solutions on the cloud, visit the AMD page here: https://www.amd.com/en/solutions/cloud-computing
Editor's Choice

