




Recap: What is YuniKorn Scheduler

Apache YuniKorn (Incubating) is a standalone resource scheduler that aims to bring advanced scheduling capabilities for Big Data workloads onto containerized platforms. Please read YuniKorn: a universal resources scheduler to learn about the rationale and architecture.
Since the time of our last post, we are delighted to update that YuniKorn was accepted by the Apache incubator in Jan 2020! Joining the Apache Software Foundation helps us further expand the budding community and attract more diversified contributors/users to join us. If you are interested, here’s the link to the Apache YuniKorn website, and Github repository.
What’s new in 0.8.0 release
YuniKorn 0.8.0 release is an important milestone, it has been tested in large scale production/staging environments for a few months. This is considered as our first stable release, users are encouraged to adopt and use this version.
We’re going to talk about new features and some performance benchmarks of the 0.8.0 release in the following sections.
New features
New features shipped with 0.8.0 release includes
Dynamic Queue Management
With this feature, users can set up placement rules to delegate queue management. The placement rules provide a simple, declarative way to define dynamic queues, which are created and deleted automatically. The simplest use case is to set a one to one namespace to queue mapping, YuniKorn will dynamically create a queue for each namespace, see an example here. Using this way, there is no other setup needed to run YuniKorn on a K8s cluster.
Natively support K8s operators (Pluggable Application Management)
YuniKorn can support various K8s operators now, this is leveraging the new feature called pluggable application management. This release ships with the native support for Spark-k8s-operator (alpha)!
With the pluggable app management framework, YuniKorn can be easily integrated with 3rd party K8s operators, such as Spark-k8s-operator, Flink-k8s-operator, Kubeflow, etc. YuniKorn monitors the Custom Resource Definitions defined by these operators, therefore it can manage app lifecycles end to end seamlessly.
Resource Reservation
In this release, YuniKorn community has redesigned the core scheduling logic to include reservations. In the batch scheduling scenario, reservation is the methodology used to not only avoid large/picky resource requests being starved, but also avoid head-of-line (HOL) blocks other requests. The scheduler automatically reserves resources on the queue and best-fit node for an outstanding request.
Pluggable Node Sorting Policies
There are 2 builtin node sorting policies available in YuniKorn, with regards to the pod distributing flavors. One is FAIR, which tries to evenly distribute pods to nodes; the other one is BIN-PACKING, which tries to pack pods onto the smallest number of nodes. The former one is suitable for Data Center scenarios, it helps to balance the stress of cluster nodes; the latter one is suitable to be used on Cloud, it can minimize the number of node instances when working with auto-scaler, in order to save cost. The node sorting policies are pluggable, users can implement their own policy and plug that to the scheduler.
Evaluation
Our community has done a series of evaluations in order to verify YuniKorn’s functionality and performance. All the tests are done with Kubemark, a tool that helps us to simulate large K8s clusters and run experimental workloads. 18 bare-metal servers were used to simulate 2000/4000 nodes for these tests.
Scheduler Throughput
When running Big Data batch workloads, e.g Spark, on K8s, scheduler throughput becomes one of the main concerns. In YuniKorn, there are lots of optimizations to improve the performance, such as a fully async event-driven system and low-latency sorting policies. The following chart reveals the scheduler throughput (by using Kubemark simulated environment, and launching 50,000 pods with heterogeneous resource requests ), by comparing YuniKorn (red line) to the K8s default scheduler (green line).
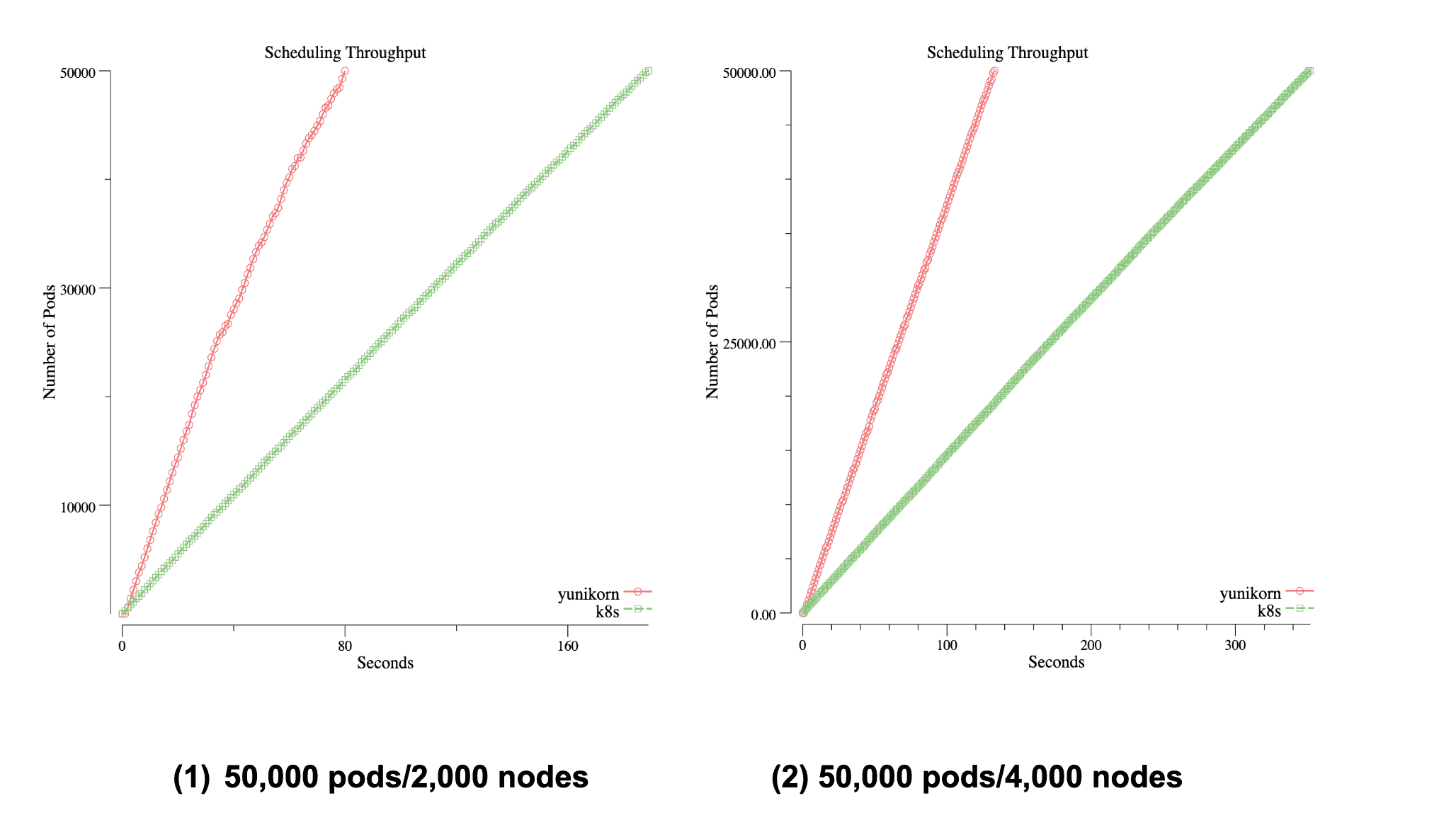
The charts record the time spent until all pods are running on the cluster
| ENVIRONMENT(# nodes) |
THROUGHPUT (pods/sec) |
|
| Default Scheduler | YuniKorn | |
| 2000 | 263 | 617 (2.34X) |
| 4000 | 141 | 373 (2.64X) |
Resource Fairness between queues
Each of YuniKorn queues has its guaranteed and maximum capacity. When we have lots of jobs submitted to these queues, YuniKorn ensures each of them gets its fair share. When we monitor the resource usage of these queues, we can clearly see how fairness was enforced:
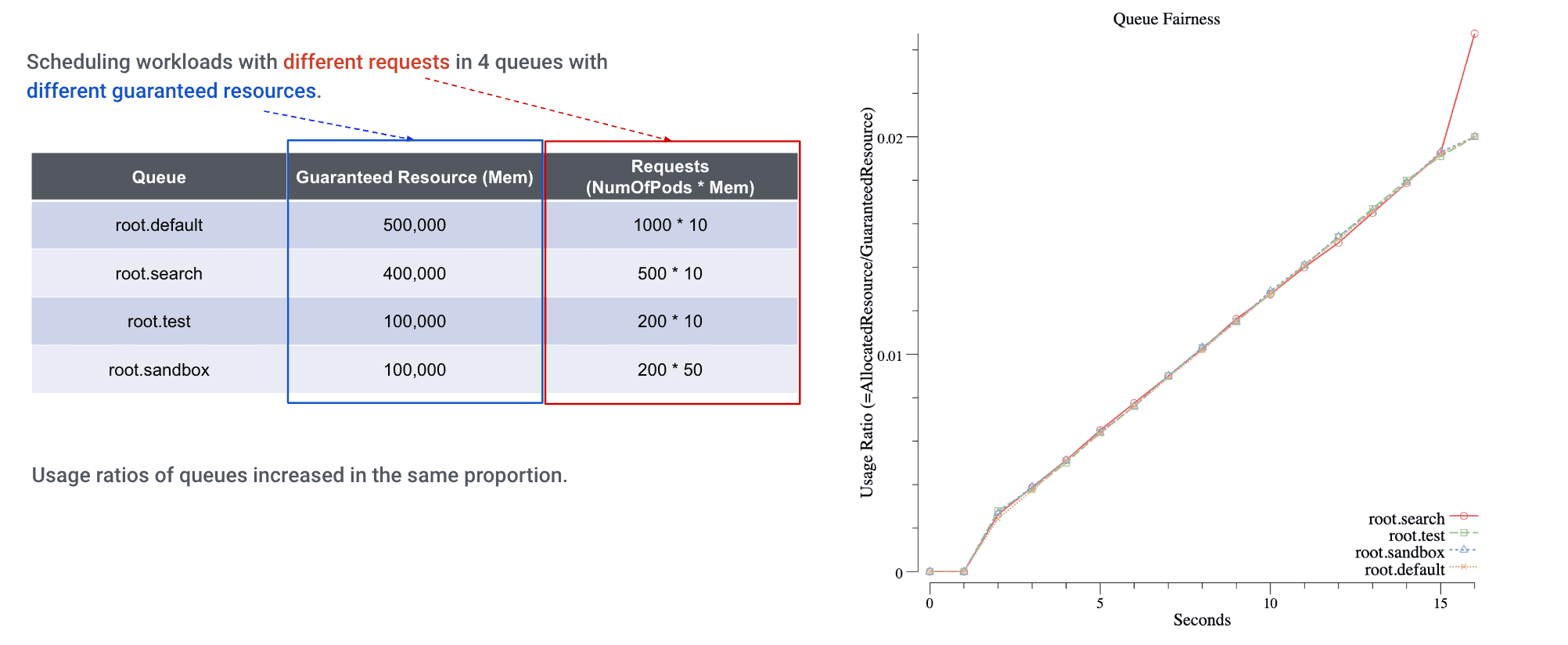
We set up 4 heterogeneous queues on this cluster, and submit different workloads against these queues. From the chart, we can see the queue resources are increasing nearly at the same slope, which means the resource fairness across queues is honored.
Community usage & participation
At Cloudera, we are focused on integrating YuniKorn to various Cloudera public cloud offerings, and we are willing to bring first-class experiences of running Big Data workloads (like Spark) on K8s with YuniKorn.
Alibaba continues to be one of our important community members. Alibaba’s Flink team is actively bringing YuniKorn to its large scale Flink clusters, in order to solve lots of problems that cannot be resolved today.
Quote the comments from Chunde Ren (Engineering Manager, Alibaba Real-time Compute) about Apache YuniKorn project:
“With the vigorous development of cloud-native and serverless computing, there are more and more big-data workloads running in Alibaba cloud for better deployment and management, backed by K8s. We identified many gaps in the existing K8s schedulers to run multi-tenant big data applications, such as no fairness/quota management among multiple tenants and low scheduling throughput for a large number of concurrent workload requests, etc. These challenges are already well-handled or working-in-progress in YuniKorn project, which aims to build a unified scheduling framework with well-designed architecture. That’s why we chose to join this great community.
We have already leveraged YuniKorn in several test K8s clusters for several months and kept improving it together with the community. We are planning to deploy YuniKorn in a new production cluster with thousands of nodes for real-time computing services in Q2 2020. Which target to process data for the Alibaba Singles Day 2020, which is the world’s largest 24-hour online shopping event.”
We also got a lot of help from Microsoft, LinkedIn, Alibaba, Apple, Tencent, Nvidia, etc. to help and guide the project’s growth. For contributors to the YuniKorn 0.8.0 release, please refer to the Apache YuniKorn release announcement.
What’s next?
We are planning to release the next version (0.9.0) by the third quarter of 2020, the main features planned for v0.9 are priority scheduling, gang scheduling, etc. More details of the future release please refer to YuniKorn Roadmap.
Thanks
Many thanks to everyone who contributed to the release from the Apache YuniKorn (Incubating) community! The release is a result of direct and indirect efforts from many contributors, please see Apache YuniKorn release announcement for a list of contributors and mentors.
Thanks, Vinod Kumar Vavilapalli for helping with reviewing/writing this blogpost.
Editor's Choice
