

Editor’s Note, August 2020: CDP Data Center is now called CDP Private Cloud Base. You can learn more about it here.
Background
This blogpost will cover how customers can migrate clusters and workloads to the new Cloudera Data Platform – Data Center 7.1 (CDP DC 7.1 onwards) plus highlights of this new release.
CDP DC 7.1 is the on-premises version of Cloudera Data Platform.
This new product combines the best of Cloudera Distribution Hadoop and Hortonworks Data Platform Enterprise (CDH and HDP onwards, respectively) along with new features and enhancements across the stack. This unified distribution is a scalable and customizable platform where you can securely run many types of workloads. For a complete picture of CDP DC 7.1, please refer to the documentation.
We will highlight new features of YARN coming with this release and we will also cover overview of how to upgrade to CDP DC 7.1 from CDH / HDP releases.
Highlights
Capacity Scheduler as default scheduler
One of the most important changes from YARN perspective: In CDP DC 7.1, Capacity Scheduler is the default and only supported scheduler. If you are using Fair Scheduler, you must migrate your workloads to Capacity Scheduler.
You can read this reference for a comparison of the schedulers.
Benefits of Using Capacity Scheduler
The following are some of the benefits when using Capacity Scheduler:
- Integration with Ranger
- Node partitioning/labeling
- Improvements to schedule on cloud-native environments, such as better bin-packing, autoscaling support, and so on.
- Scheduling throughput improvements
- Global Scheduling Framework
- Lookup of multiple nodes at one time
From the CDP DC 7.1 release, Cloudera provides a conversion tool, called FS2CS Conversion Utility. With this tool, you can convert your Fair Scheduler configuration to an equivalent Capacity Scheduler configuration.
We are looking forward to publish another blogpost to discuss the details about how to migrate from the Fair Scheduler to the Capacity Scheduler, as well as an in depth feature comparison of the schedulers.
GPU Scheduling support
GPUs are getting more and more important for many Big Data applications. Deep-learning / machine learning, data analytics, genome sequencing all have applications that rely on GPUs to achieve higher performance. In many cases, GPUs can get 10x speed ups.
GPU support was released as part of Hadoop 3.1 under the umbrella YARN-6223.
GPU scheduling is natively supported by Cloudera Manager, even the configuration for GPU device auto-discovery, making YARN configuration user-friendly for cluster administrators.
You can find details on how to configure GPU scheduling in the Cloudera Manager documentation.
FPGA Scheduling support
Similarly to GPUs, FPGAs have their wide-range of use-cases.
Specific applications for an FPGA include digital signal processing, bioinformatics, device controllers, medical imaging, computer hardware emulation,voice recognition, cryptography, and many more.
FPGA support was released as part of Hadoop 3.1 under the umbrella YARN-5983.
FPGA scheduling is also natively supported by Cloudera Manager, see this page for details on how to configure YARN using Cloudera Manager.
Queue Manager
YARN Queue Manager is the graphical user interface for managing the configuration of Capacity Scheduler. Using YARN Queue Manager UI, you can set scheduler level properties and queue level properties. You can also view, sort, search, and filter queues using the YARN Queue Manager UI.
This is how Queue Manager looks:
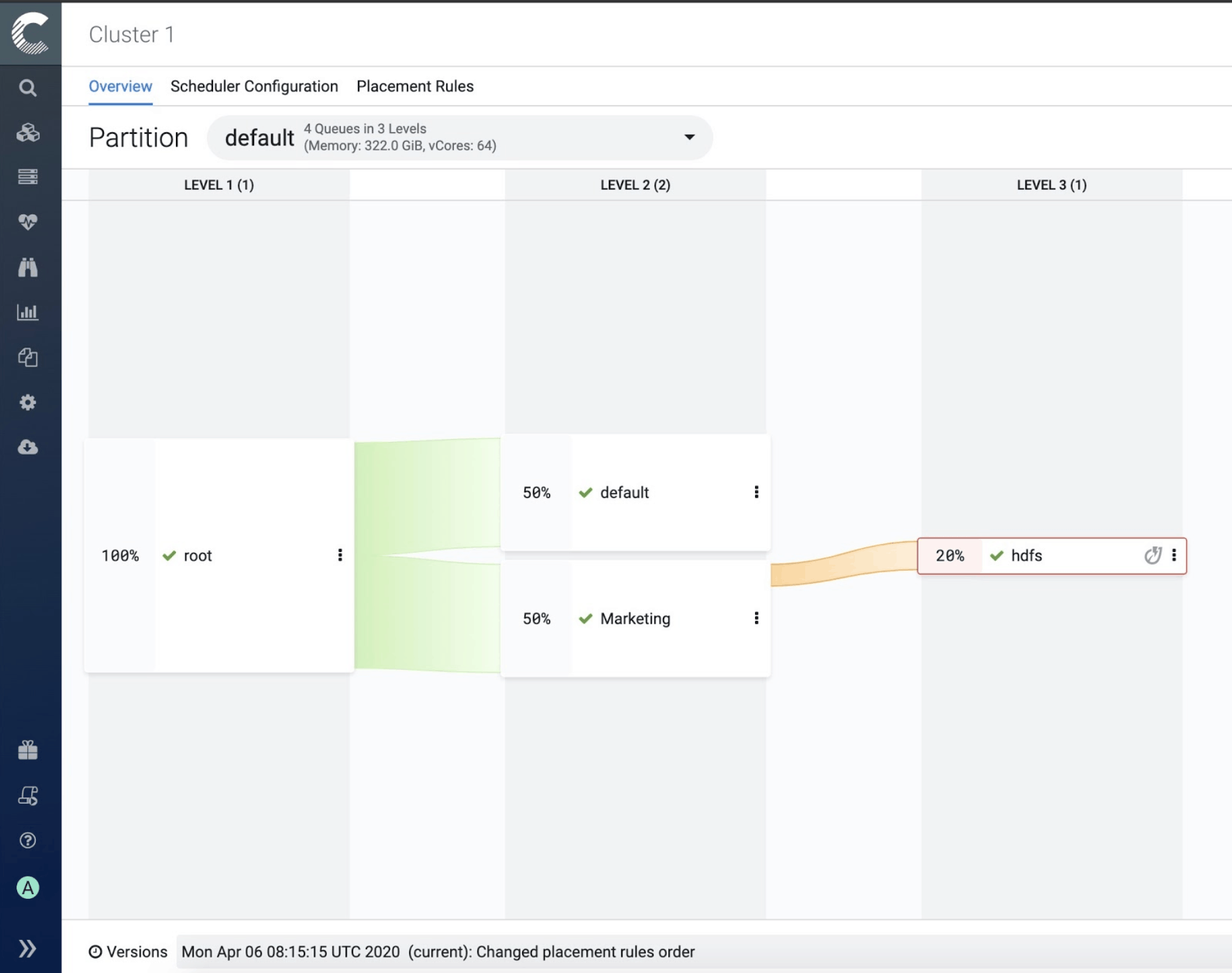
For more information about Queue Manager, see Allocating Resources Using YARN Queue Manager UI.
Docker on YARN
Support for containerized applications on YARN with Docker is supported from Hadoop 3.1, under the umbrella YARN-3611.
Docker containerization provides isolation and enables you to run multiple versions of the same applications side-by-side.
For an overview of this feature, please refer to the official Cloudera Runtime documentation of Docker support for YARN.
Cloudera Manager has native support for YARN Docker containers that are well described in the documentation. To help you troubleshoot, we prepared a detailed page where common configuration and runtime errors are discussed.
There are many use-cases of using Docker containers with YARN, for example, to package Spark and its dependencies, you can utilize containers and you can even share these versions of the framework and its dependencies quite easily. Please refer to our blog post to have a more in-depth review of Spark and Docker as a use-case of Docker on YARN: Introducing Apache Spark on Docker on top of Apache YARN with CDP DataCenter release.
Another example is when running an ML training workload on YARN (like Tensorflow/PyTorch), it doesn’t need to install dependencies like Python virtual environment, various Python packages, or an ML engine like Tensorflow or PyTorch in the physical nodes anymore. Instead, you simply package them in a Docker image so Apache Submarine can run Tensorflow/Pytorch on Docker on YARN.
See Run Apache Submarine On YARN.
Logging improvements
Log aggregation
The YARN Log Aggregation feature enables you to move local log files of any application onto HDFS or cloud-based storage depending on your cluster configuration.
YARN can move local logs securely onto HDFS or cloud-based storage, such as AWS. This allows the logs to be stored for a much longer time than they could be on a local disk, allows faster search for a particular log file, and optionally can handle compression.
Rolling Log aggregation
On top of basic log aggregation, Rolling log aggregation is now supported from this release.
This feature is responsible for aggregating logs at set time intervals. This time is given in seconds and is configurable by the user. Rolling log aggregation is primarily used for long-running applications like Spark streaming jobs.
We are looking forward to publishing another blog post to discuss the details of Log aggregation for YARN on CDP DC.
By default, log aggregation supports two file controllers: TFile and IFile. You can also add your own custom file controller.
With CDP DC 7.1, IFile (Indexed file) became supported as the default log aggregation file controller. IFile is a newer file controller than TFile. In an IFile, the files are indexed so it is faster to search in the aggregated log file than in a regular TFile.
Hadoop archives
For clusters with a large number of YARN aggregated logs, it can be helpful to combine them into Hadoop archives in order to reduce the number of small files. This way, the stress on the NameNode reduced as well. Aggregated logs in Hadoop archives can still be read by the Job History Server and by the yarn logs command.
Both CDH and HDP customers will get the Mapreduce log archive tool as it was implemented in Hadoop 2.8, specifically with MAPREDUCE-6415.
For more on Hadoop archives, see the Hadoop Archives Guide.
New YARN UI v2
The user-friendly YARN WEB UI2 is now the default user interface.
For example, the “Cluster Overview” looks like this on UI2.
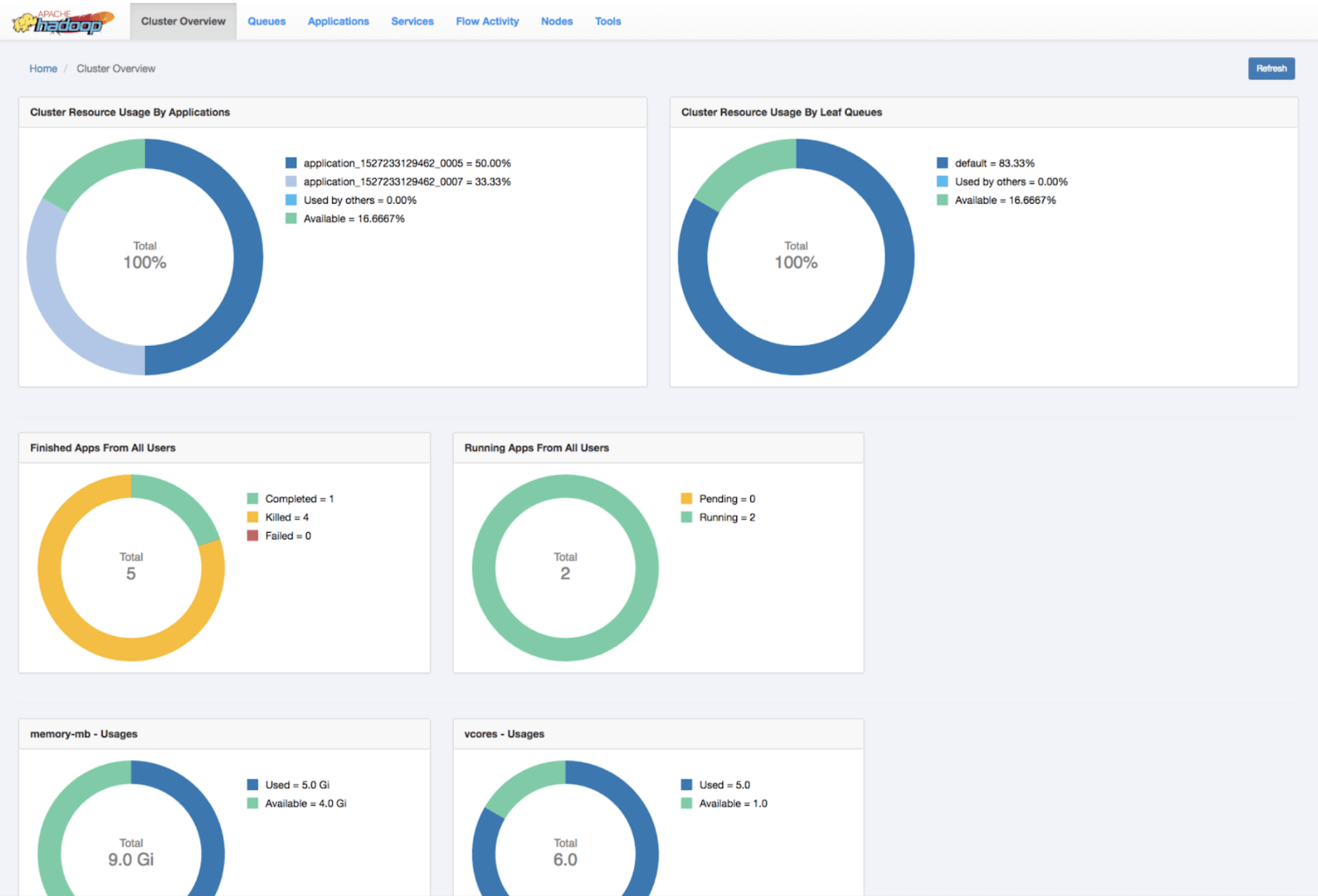
Overview of upgrade
As the base product can be a number of versions of either CDH or HDP, it is easier to list them in a table along with their Hadoop release versions and the upgradability to CDP DC 7.1.
| Product | Version | Hadoop release | Upgrade to CDP DC 7.1 |
| CDH | 5.13.x – 5.16.x | 2.6.0 | Directly with Cloudera Manager |
| CDH | 6.0 or higher | 3.0.0 | Not supported |
| CDH | other versions | N/A | Interim upgrade step / manually copy data to CDP cluster |
| HDP | 2.6.5 | 2.7.3 | Supported with interim step |
| HDP | 3.x | 3.1.1 | Not supported |
If you would like to access more detailed information on supported versions, please refer to the Supported upgrade paths.
Summary
As discussed in detail, upgrading from CDH or HDP is a way forward to leverage the new features of CDP DC 7.1.
With this new platform, users will have Capacity Scheduler as the default scheduler, with the additional benefit of native support of GPU / FPGA scheduling and Docker containers, all integrated into Cloudera Manager. You will also get Queue Manager which is our brand new tool for managing YARN scheduler queues.
Talking about user interfaces, YARN Web UIv2 is also integrated by default into Cloudera Manager.
We also talked about several logging improvements users can leverage.
Acknowledgments
I’d like to thank Wilfred Spiegelenburg and Sunil Govindan for our planning and brainstorming sessions about how to approach the whole topic and testability perspectives of upgrading.
I’d also like to thank the Budapest YARN Team for their continued effort that made the whole story happen.
Special thanks to Wangda Tan, Wilfred Spiegelenburg, and Rudolf Reti for reviewing and sharing useful comments.
A huge thanks to Rahul Buddhisagar and Paolo Milani for helping on Cloudera Manager related questions and code reviews.
References
https://blog.cloudera.com/upgrading-clusters-workloads-hadoop-2-hadoop-3/
https://blog.cloudera.com/hadoop-3-blog-series-recap/
https://blog.cloudera.com/introducing-apache-spark-on-docker-on-top-of-apache-yarn-with-cdp-datacenter-release/
Editor's Choice


for customers with data on CDH 6.x, please confirm the the below understanding.
(1) we have to create a new temporary cluster of CDP 7.2, and migrate the data there.
(2) Upgrade the existing 6.4 to the 7.2 and them migrate the data from the temporary 7.2 CDP cluster.