


Introduction
Apache Impala is a massively parallel in-memory SQL engine supported by Cloudera designed for Analytics and ad hoc queries against data stored in Apache Hive, Apache HBase and Apache Kudu tables. Supporting powerful queries and high levels of concurrency Impala can use significant amounts of cluster resources. In multi-tenant environments this can inadvertently impact adjacent services such as YARN, HBase, and even HDFS. Mostly these adjacent services can be isolated by enabling static services pools which use Linux cgroups to fix CPU and memory allocations for each respective service. These can be simply configured using the Cloudera Manager wizard. Impala Admission Control, however, implements fine-grained resource allocation within Impala by channeling queries into discrete resource pools for workload isolation, cluster utilization, and prioritization.
This blog post will endeavour to:
- Explain Impala’s admission control mechanism;
- Provide best practices for resource pool configuration; and
- Offer guidance for tuning resource pool configuration to existing workloads.
Anatomy of Impala Query Execution
Before we dive into admission control in detail, let us provide a quick overview of Impala query execution. Impala implements a SQL query processing engine based on a cluster of daemons acting as workers and coordinators. A client submits its queries to a coordinator which takes care of distributing query execution across the workers of the cluster.
Impala query processing can be separated into three phases: compilation, admission control, and execution as illustrated below:
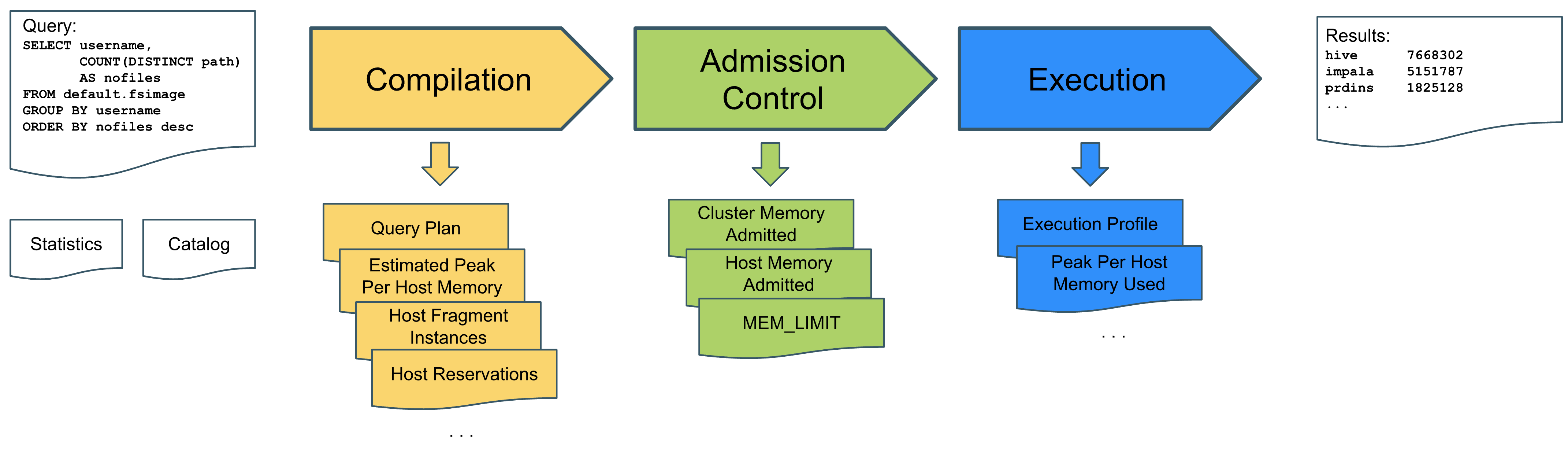
Compilation
When an Impala coordinator receives a query from the client, it parses the query, aligns table and column references in the query with data statistics contained in the schema catalog managed by the Impala Catalog server, and type checks and validates the query.
Using table and column statistics, the coordinator produces an optimized distributed query plan – a relational operator tree – with parallelizable query fragments. It assigns query fragments to workers, taking account of data locality – thus forming fragment instances – and estimates the peak per-host main memory consumption of the query. It further determines an allotment of main memory that workers will allocate initially for processing when receiving their fragments.
Admission Control
Once compiled, the coordinator submits the query to admission control. Admission control decides, based on the main memory estimations and fragment allocations as well as the queries already admitted to the cluster, whether a query is admitted for execution, queued, or rejected.
To do so, it keeps a tally of the main memory estimated to be consumed by the admitted queries on both a per-host and a per-cluster basis – the latter tally being divided into so-called resource pools defined by the cluster administrators. If there is enough headroom for the query to fit into both the per-host and per-resource pool tally it will be admitted for execution.
The key metric for admission control is the query’s MEM_LIMIT: the admitted maximum per host memory consumption of the query. MEM_LIMIT is often – but not always as we will see later – the same as the estimated peak per-node memory consumption of the query compilation phase.
Execution
After admission, the coordinator starts executing the query. It distributes the fragment instances to the workers, collects the partial results, assembles the total result, and returns it to the client.
Workers start execution with the initial main memory reservation determined by the query compilation phase. As execution progresses, a worker may increase the memory allocated for the query strictly observing the MEM_LIMIT admitted by admission control. Should the main memory consumption of the query approach this limit on a worker, it may decide to spill memory to disk (if allowed to do so). If main memory consumption reaches the MEM_LIMIT, the query will be killed.
During execution, the coordinator monitors the query’s progress and logs a detailed query profile. The query profile will feature a comparison of the estimates of the query compilation phase concerning the estimated number of rows and main memory consumed with the number of rows and main memory actually consumed by a query. This provides valuable insights for query optimization and the quality of table statistics.
Impala Admission Control in Detail
After this overview of Impala query execution in general, let us dive deeper into Impala admission control. Admission control is largely defined by
- the main memory assigned to each daemon (the mem_limit configuration parameter);
- the shares of total cluster memory assigned to resource pools and their configuration;
- the total and per-host memory consumption estimates of the query planner.
Let us take a look at the key resource pool configuration parameters and a concrete example of the admission control process for a query.
Resource Pools
Resource pools allow the total amount of Impala cluster memory to be segmented to different use cases and tenants. Rather than running all queries in a common pool, segmentation allows administrators to assign resources to the most important queries in order that they not be disrupted by those with a lower business priority.
Key resource pool configuration parameters are:
- Max Memory: the amount of total main memory in the cluster that can be admitted to queries running in the pool. Should the expected total main memory consumption of a query to be admitted to the pool on top of the expected total main memory of the queries already running in the pool exceed this limit, the query will not be admitted. The query might be rejected or queued, depending on the pool’s queue configurations.
- Maximum Query Memory Limit: an upper bound to the admissible maximum per-host memory consumption of a query (MEM_LIMIT). Admission control will never impose a MEM_LIMIT larger than Maximum Query Memory Limit on a query – even if the peak per-host memory consumption estimated by the query compilation phase exceeds this limit.
Unlike Max Memory, Maximum Query Memory Limit affects admission control across all pools. I.e., should the MEM_LIMIT (bounded by Maximum Query Memory Limit) of a query on top of the MEM_LIMITs of the queries already running exceed the configured main memory mem_limit of a given daemon, the query will not be admitted.
The purpose of this parameter is to limit the impact of queries with large and possibly bad or overly conservative peak per-host memory consumption estimates on admission control – for instance, queries based on tables with no statistics or very complex queries.
This parameter in combination with Max Memory, the number of daemons, and the daemons’ mem_limit configuration implicitly defines the potential parallelism of queries running in the pool and across pools, respectively. As a rule of thumb, Maximum Query Memory Limit should be a fraction of Max Memory divided by the number of daemons that captures the desired query pool parallelism.
- Minimum Query Memory Limit: a lower bound to the admissible maximum per-host memory consumption of a query (MEM_LIMIT). Regardless of the per-host memory estimates, MEM_LIMIT will never be less than this value. A safe value for the minimum query memory limit would be 1GB per node.
- Clamp MEM_LIMIT: clients can override the peak per-host memory consumption estimated by query compilation and the resulting MEM_LIMIT derived by admission control by explicitly setting the MEM_LIMIT query option to a different value (e.g., by prepending SET MEM_LIMIT=…mb to their query).
If Clamp MEM_LIMIT is not set to true (which is the default), users can totally disregard the Minimum and Maximum Query Memory Limit settings of resource pools. If set to true, any MEM_LIMIT explicitly provided by clients will be bound to the Minimum and Maximum Query Memory Limit settings.
- Max Running Queries: although the Minimum and Maximum Query Memory Limit settings together with the Max Memory setting and the number of daemons implicitly define a range of how many queries can run in parallel inside a resource pool, Max Running Queries allow one to define a fixed number of queries that can run at the same time.
- Max Queued Queries: if a query cannot be admitted immediately because its MEM_LIMIT would either exceed the pool’s Max Memory limit or a daemon’s mem_limit configuration parameter, Impala admission control can send the query to the pool’s waiting queue. Max Queued Queries defines the size of this queue, with the default being 200. If the queue is full, the query will be rejected.
- Queue Timeout: a limit for how long a query may be waiting in the pool’s waiting queue before being rejected. The default timeout is one minute.
Admission Control Example
Let us illustrate Impala admission control and the interplay between peak per-host memory consumption estimates and resource pool settings using a simplified example:
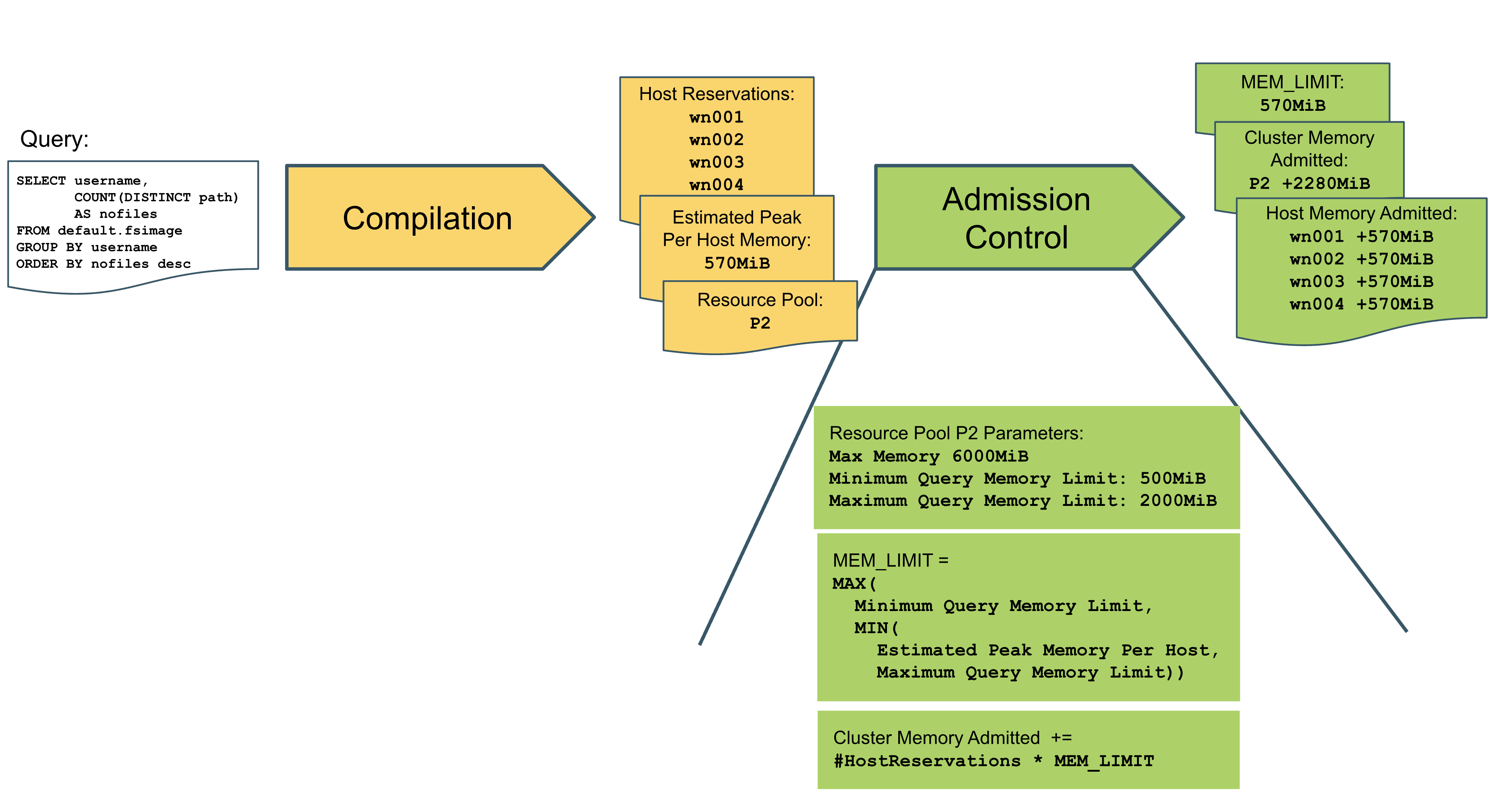
In the figure above, a client submits a simple group by / count aggregation SQL query to an Impala coordinator via an example Resource Pool P2. Using the schema catalog and query statistics for the table being queried, the query planner estimates peak per-host memory usage to be 570 MiB. Furthermore, the planner has determined that the fragments of the query will be executed on hosts wn001, wn002, wn-003, and wn004. With that query compilation result, the query is handed over to admission control.
For the purpose of the example, we assume that Resource Pool P2 has been configured with a Maximum Query Memory Limit of 2000 MiB, a Minimum Query Memory Limit of 500MiB and a Max Memory setting of 6000MiB.
The peak per-host memory consumption estimate of 570MiB fits right within the Minimum and Maximum Query Memory Limit settings. Hence, admission control will not modify this estimate in any way but set MEM_LIMIT to 570 MiB. Had the estimate been higher than 2000MiB, MEM_LIMIT would have been capped at 2000MiB; had the estimate been lower than 500MiB, MEM_LIMIT would have been buffered to 500MiB.
For admission, admission control checks whether the sum of all MEM_LIMITs of the already running queries on nodes wn001, wn002, wn-003, and wn004 plus 570 MiB exceeds any of those nodes’ configured main memory mem_limit.
Admission control further checks whether the query’s MEM_LIMIT times the number of nodes the query will run on on top of the already running queries still fits P2’s configured Max Memory setting of 6000 MiB.
If any of both checks fails, admission control will either queue or reject the query, depending on whether the waiting queue limit has already been reached or not.
Should both checks pass, admission control admits the query to execution under the MEM_LIMIT of 570MiB. Each worker node will execute the query as long as it does not consume more main memory on the node than this limit – should that be the case, a worker node will terminate the query.
Admission control will finally increment its host memory admitted tallies of the affected nodes by the MEM_LIMIT (570MiB); it will also increment the resource pool’s cluster memory admitted tally by the number of node the query will run on times the MEM_LIMIT (570MiB * 4 = 2280 MiB).
Admission Control Best Practices
Having illustrated how Impala admission control works, the question is what are sound strategies for configuring admission control via resource pools to suit one’s own workloads.
By tuning admission control, one tries to balance among several goals, central ones being:
- workload isolation;
- cluster resource utilization;
- fast query admission.
In the following, we present basic recommendations for achieving these goals using the Impala admission control configuration options available. Notice that some of the recommended optimisation strategies are repeated to achieve a different goal.
Within these recommendations, we refer to cluster parameters as well as workload characteristics. We start out by listing basic parameters of both the cluster and expected workload one should gather when determining admission control configuration.
Cluster and Workload Parameters
The following basic cluster parameters influence the various configuration options for Impala admission control:
- the number of Impala worker daemons in the cluster;
- the per-node memory mem_limit configured for these workers
- the resulting Max Memory of the Impala cluster (workers * mem_limit).
- The total concurrent queries running across all the pools.
Parameterizing workload is less clear-cut. Often, exact workload characteristics are not known at the time of admission control configuration, they may change over time, or they are difficult to quantify. However, administrators should consider:
- Applications running on Impala
- Workload types running on Impala
- Query Parallelism
- Acceptable Waiting Time
- Memory Consumption
Cloudera Manager provides some useful insights in this respect via the Impala > Queries page:
On that page, queries can be filtered by facet, for example, peak per-node memory usage along with query counts:
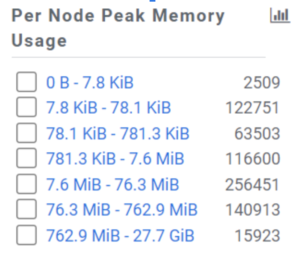
Likewise, there is a histogram for the peak memory usage of queries across all nodes:
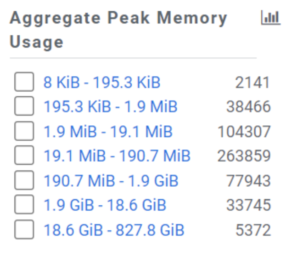
Using this information, administrators can iterate resource pool configurations and begin the process of refining queue configurations to best meet the needs of the business. Typically, a number of iterations will be required as knowledge and insights of usage develop over time.
Achieving Workload Isolation
Keep Pools Homogeneous: In order to isolate workloads it’s useful to keep resource pools homogeneous. That is to say, queries in a pool should be similar in nature, whether they be ad-hoc analytics that require occasional large memory assignment or highly-tuned regular ELT queries.
Set Max Memory of Resource Pools According to Relative Load: Having identified the resource pools, the first configuration parameter to determine for each pool is Max Memory. As you may recall, this is the share of the total Impala worker main memory up to which admission control allows queries into the pool.
A simple approach to choosing Max Memory is to set it proportionally to the relative load share that should be granted to the queries in the pool. Relative load share could be quantified based on expected or exhibited query rate or memory usage, for example.
Avoid Having too many Resource Pools: Having too many resource pools is also not ideal as Impala memory for that pool is reserved and other pools cannot use that memory (unless the pool is overprovisioned). This basically causes busy pools to queue up and memory in the free pools to be unused. Ideally depending on the use case somewhere around 10 pools should the maximum and smaller tenants can share resource pools.
Don’t Fall For The Isolation Fallacy: Recall that resource pools do not provide complete workload isolation. The reason for this is the way admission control keeps a per-host tally of the MEM_LIMITs of all queries admitted for execution. This tally is independent of resource pools. You can, however, reduce the likelihood of admission rejection as we will see below.
Keep Maximum Query Memory Limit Low: By reducing the Maximum Query Memory limit for each resource pool, the likelihood of MEM_LIMITs of all admitted queries reaching a worker’s mem_limit is reduced.
Enable Clamp MEM_LIMIT: If Clamp MEM_LIMIT is not enabled for a resource pool, every user submitting a query to that pool can force admission control to set a MEM_LIMIT even outside the bounds of the pool’s Minimum Query Memory Limit and Maximum Query Memory Limit. Thus, by prepending SET MEM_LIMIT=<very large value> to a query, a mischievous user can quickly block admission control from allowing not only further queries into the same pool but also prevent other queries from other pools onto the same worker daemons.
Compute Table Statistics: Doing so with current statistics will yield better – i.e., lower – peak per-host memory estimates by the query planner, which is the foundation for admission control’s MEM_LIMIT. Furthermore the query plan will be optimized which will result in improved execution time. Faster execution time means less time blocking memory in admission control.
Avoid Spilling Queries to disk: Queries that spill to disk will slow down queries significantly. Slow queries will block memory in admission control for a longer period of time, which increases the likelihood of blocking the admission of other queries. Therefore set aggressive (minimal) SCRATCH_LIMITS to ensure such queries get killed quickly with the proviso that in some cases, spilling to disk is unavoidable. Generally, the primary strategy for managing spills is by managing statistics, file formats and layouts to ensure the query does not spill in the first place. Disabling Unsafe Spills will ensure queries that are likely to reach that limit are quickly killed.
It is possible set SCAN_BYTES_LIMIT to control queries scanning 100s of partitions and NUM_ROWS_PRODUCED_LIMIT to avoid poorly designed queries – e.g. cross joins, however caution should be applied in universally settting these limits where it may be more appropriate to set at per query or per pool level and reflect the operating charachteristics and capacity of the cluster., See CDP Private Cloud Base documentation for more information.
Set Max Running Queries to Limit Parallelism: With many queries submitted to a pool in an uncontrolled manner, overly relaxed parallelism boundaries may allow these queries to fill up the per-host admitted memory count to such an extent that queries in other pools are prevented from running. By setting the Max Running Queries parameter to the desired query parallelism for the pool’s workload, one can create headroom in the per-host memory count for queries from other pools. This should be accompanied by appropriate waiting queue settings (Max Queued Queries and Queue Timeout).
Achieving High Cluster Resource Utilization
Keep Maximum Query Memory Limit Close to Peak Per-Node Query Memory Consumption: Keeping Maximum Query Memory Limits close to the real peak per-node memory consumption is important to achieve a good cluster memory utilization.
Remember Impala admission control does not consider the real memory consumption of queries. Instead, it manages admission by means of MEM_LIMITs based on the query planner memory estimates bound by the Minimum and Maximum Query Memory Limit values. The more generous a pool’s Maximum Query Memory is set, the more willing admission control is to account for and trust large conservative memory estimates of the planner that could result – for instance – from missing or outdated table statistics or very complex query plans.
Limit Parallelism Only Where Necessary: Setting Max Running Queries can result in reduced cluster utilization in situations where admission control no longer admits queries into a pool having reached its limit of running queries, despite only limited load in other resource pools. Hence, query parallelism should only be limited explicitly for pools with high bursts in query ingestion rate or with many long-running queries.
Cluster Level Query Parallelism Limit: At a cluster level, across all the pools, the recommended total queries running at any time is recommended to be close to 1.5 to 2.x of the total number of multi threaded cores on the data nodes. This ensures that each query gets an appropriate share of CPU time and does not get paged out frequently. Thus if the data nodes have say 2*24 Core Processors, with multithreading we have 96 multithreaded cores.
With this we would recommend that total concurrent queries on the cluster at any given time should be not more than 96 queries.
Achieving Fast Query Admission
An ideal query admission control should hardly be noticeable by clients yet still ensure workload isolation and a high degree of cluster utilization. An effect that is particularly noticeable by clients, however, is when Impala admission control does not admit a query into the cluster but instead puts it into a waiting queue in which it may even time out.
Set a low Maximum Query Memory Limit: not only reduces the risk of the per-host admitted memory count reaching the mem_limit of a worker; it also makes queries consume less of the pool’s Max Memory itself again reducing the risk of waiting times. 1GiB is a sensible low value in most circumstances.
Enable Clamp MEM_LIMIT, such that query authors cannot intentionally or unintentionally make admission control set excessively large MEM_LIMITs for their queries.
Ensure current table statistics: to support the query planner in creating better and faster query plans with lower memory estimates.
Limit Spilling queries: As these are slow, burdening admission control per-pool admitted memory counts for long periods of time, negatively affecting the risk of queries not being admitted to the cluster. Spilling adds work for the disk, slowing down reads for queries, it is something you do strongly want to avoid
Consider Waiting Time Resilience Per Pool: Effectively, one has to strike a balance between waiting times for queries of pools with bursts in query ingestion rate or long-running queries and waiting times for queries of other pools with different query characteristics and requirements. Fast query admission from the perspective of one application may constitute suboptimal workload isolation from the perspective of another application.
In order to be able to make waiting queue configurations for resource pools, it is therefore important to have an understanding of what waiting times for admission are acceptable by the different applications issuing queries to these resource pools.
Summary
In summary we have demonstrated the anatomy of an Impala query, how it is planned, compiled and admitted for execution and how administrators can use the query profile to tune and refine the query’s resource usage. We have described Impala admission control and how it can be used to segment Impala service resources and tuned in order to enable the safe execution of queries that meet the established requirements according business priority. Further documentation is available here.
Editor's Choice

