

Introduction
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructured data by means of parallel execution on a large number of commodity computing nodes.
While that programming paradigm was a good fit for the challenges it addressed when it was originally introduced, recent technology supply and demand drivers have introduced varying degrees of scalability complexity to modern Enterprise Data Platforms that need to adapt to a dynamic landscape characterized by:
- Proliferation of data processing capabilities and increased specialization by technical use case or even specific variations of technical use cases (for example, certain families of AI algorithms, such as Machine Learning, require purposely-built frameworks for efficient processing). In addition, data pipelines include more and more stages, thus making it difficult for data engineers to compile, manage, and troubleshoot those analytical workloads
- Explosion of data availability from a variety of sources, including on-premises data stores used by enterprise data warehousing / data lake platforms, data on cloud object stores typically produced by heterogenous, cloud-only processing technologies, or data produced by SaaS applications that have now evolved into distinct platform ecosystems (e.g., CRM platforms). In addition, more data is becoming available for processing / enrichment of existing and new use cases e.g., recently we have experienced a rapid growth in data collection at the edge and an increase in availability of frameworks for processing that data
- Rise in polyglot data movement because of the explosion in data availability and the increased need for complex data transformations (due to, e.g., different data formats used by different processing frameworks or proprietary applications). As a result, alternative data integration technologies (e.g., ELT versus ETL) have emerged to address – in the most efficient way – current data movement needs
- Rise in data security and governance needs due to a complex and varying regulatory landscape imposed by different sovereigns and, also, due to the increase in number of data consumers both within the boundaries of an organization (as a result of data democratization efforts and self-serve enablement) but also outside those boundaries as companies develop data products that they commercialize to a broader audience of end users.
These challenges have defined the guiding principles for the metamorphosis of the Modern Data Platform to leverage a composite deployment model (e.g., hybrid multi-cloud), that delivers fit-for-purpose analytics to power the end-to-end data lifecycle with consistent security and governance and in an open manner (using open source frameworks to avoid vendor lock-ins and proprietary technologies). These four capabilities together define the Enterprise Data Cloud.
Understanding Scalability Challenges in Modern Enterprise Data Platforms
A consequence of the aforementioned shaping forces is the increase in scalability challenges for modern Enterprise Data Platforms. Those scalability challenges can be organized in three major categories:
- Computational Scalability: How can we deploy analytical processing capabilities at scale and in a cost-efficient manner, when analytical needs grow at an exponential rate, and we need to implement a multitude of technical use cases against massive amounts of data?
- Operational Scalability: How can we manage / operate an Enterprise Data Platform in an operationally efficient manner, particularly when that data platform grows in scale and complexity? In addition, how can we enable different application development teams to efficiently collaborate and apply agile DevOps disciplines when they leverage different programming constructs (e.g., different analytical frameworks) for complex use cases that span different stages across the data lifecycle?
- Architectural Scalability: How can we maintain architectural coherence when the enterprise data platform needs to fulfill an increasing variety of functional and non-functional requirements that require more sophisticated analytical processing capabilities, while delivering enterprise-grade data security and governance capabilities for data and use cases hosted on different environments (e.g., public, private, hybrid cloud)?
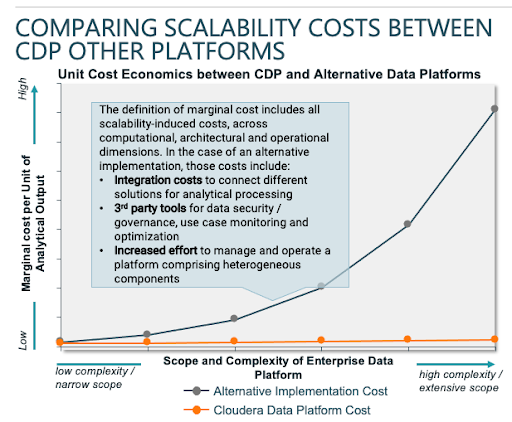
Typically, organizations that leverage narrow-scope, single public cloud solutions for data processing face incremental costs as they scale to address more complex use cases or an increased number of users. Those incremental costs derive from a variety of reasons:
- Increased data processing costs associated with legacy deployment types (e.g., Virtual Machine-based autoscaling) instead of using advanced deployment types such as containers that reduce time to scale up / down compute resources
- Limited flexibility to use more complex hosting models (e.g., multi-public cloud or hybrid cloud) that would reduce analytical cost per query using the most cost-efficient infrastructure environment (leveraging, e.g., pricing disparities between different public cloud service providers for specific compute instance types / regions)
- Duplication of storage costs as analytical outputs need to be stored in silo-ed data stores, and, oftentimes, using proprietary data formats between different stages of a broader data ecosystem that uses different tools for analytical use cases
- Increased costs for 3rd party tools required for data security / governance and workload observability and optimization; The need for those tools stems from either lack of native security and governance capabilities in public cloud-only solutions or the lack of uniformity in security and governance frameworks employed by different solutions within the same data ecosystem
- Increased integration costs using different loose or tight coupling approaches between disparate analytical technologies and hosting environments. For example, organizations with existing on-premises environments that are trying to extend their analytical environment to the public cloud and deploy hybrid-cloud use cases need to build their own metadata synchronization and data replication capabilities
- Increased operational costs to manage Hadoop-as-a-Service environments, given the lack of domain expertise by Cloud Service Providers that simply package open source frameworks in their own PaaS runtimes but don’t offer sophisticated proactive or reactive support capabilities, reducing Median Time To Discover and Repair (MTTD / MTTR) for critical Severity-1 issues.
The above challenges and costs can be easily ignored in PoC deployments or at the early stages of a public cloud migration, particularly when an organization is moving small and less critical workloads to the public cloud. However, as the scope of the data platforms extends to include more complex use cases or process larger volumes of data, those ‘overhead costs’ become higher and the cost for analytical processing increases. That situation can be easily illustrated with the notion of marginal cost for a unit of analytical processing, i.e., the cost to service the next use case or provide an analytical environment to a new business unit:
How Cloudera Data Platform (CDP) Addresses Scalability Challenges
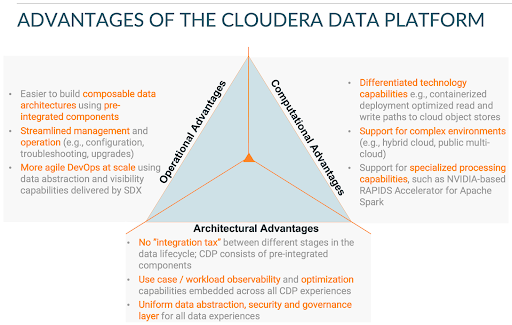
Unlike other platforms, CDP is an Enterprise Data Cloud and enables organizations to manage scalability challenges by offering a fully-integrated, multi-function, and infrastructure-agnostic data platform. CDP includes all necessary capabilities related to data security, governance and workload observability that are prerequisites for a large scale, complex enterprise-grade deployment:
Computational Scalability
- For Data Warehousing use cases that are some the most common and critical big data workloads (in the sense that they are being used by many different personas and other downstream analytical applications), CDP delivers lower cost-per-query vis-a-vis cloud-native data warehouses and other Hadoop-as-a-Service solutions, based on comparisons performed using reference performance benchmarks for big data workloads (e.g., benchmarking study conducted by independent 3rd party)
- CDP leverages containers for the majority of the Data Services thus enabling almost instantaneous scale up / down of compute pools, instead of using Virtual Machines for auto-scaling, an approach still used by many vendors
- CDP offers the ability to deploy workloads on flexible hosting models such as hybrid cloud or public multi-cloud environments, allowing organizations to run use cases on the most efficient environment throughout the use case lifecycle without even incurring migration / use case refactoring costs
Operational Scalability
- CDP has introduced many operational efficiencies and a single pane of glass for full operational control and for composing complex data ecosystems by offering pre-integrated analytical processing capabilities as “Data Services” (previously known as experiences) , thus reducing operational effort and cost to integrate different stages in a broader data ecosystem and manage their dependencies.
- For each individual Data Service, CDP reduces time to configure, deploy and manage different analytical environments. That is achieved by providing templates based on different workload requirements (e.g., High Availability Operational Databases) and by automating proactive issue identification and resolution (e.g., auto-tuning and auto-healing features provided by CDP Operational Database or COD)
- That level of automation and simplicity enables data practitioners to stand up analytical environments in a self-service manner (i.e., without involvement from the Platform Engineering team to configure each Data Service) within the security and governance boundaries defined by the IT Function
With CDP, application development teams that leverage the various Data Services can accelerate development of use cases and time-to-insights by leveraging the end-to-end data visibility features offered by the Shared Data Experience (SDX) such as data lineage and collaborative visualizations Architectural Scalability
- CDP offers different analytical processing capabilities as pre-integrated Data Services, thus eliminating the need for complex ETL / ELT pipelines that are typically used to integrate heterogeneous data processing capabilities
- CDP includes out-of-the-box, purposely built capabilities that enable automated environment management (for hybrid cloud and public multi-cloud environments), use case orchestration, observability and optimization. CDP Data Engineering (CDE) for example, includes three capabilities (Managed Airflow, Visual Profiler and Workload Manager) to empower data engineers to manage complex Directed Acyclic Graphs (DAGs) / data pipelines
- SDX, which is an integral part of CDP , delivers uniform data security and governance, coupled with data visualization capabilities enabling quick onboarding of data and data platform consumers and access to insights for all of CDP across hybrid clouds at no extra cost.
Conclusion
The sections above present how the Cloudera Data Platform helps organizations overcome scalability challenges across computational, architectural and operational areas that are associated with implementing Enterprise Data Clouds at scale. Details around the Shared Data Experience (SDX) that removes architectural complexities of large data ecosystems can be found here and for an overview of the Cloudera Data Platform processing capabilities please visit
Editor's Choice

