

In our previous blog on A Case for Mirromaker 2, we had discussed how enterprises rely on Apache Kafka as an essential component of their data pipelines and require that the data availability and durability guarantees cover for entire cluster or datacenter failures. As we had discussed in the blog, the current Apache Kafka solution with Mirrormaker 1 has known limitations in providing an enterprise managed disaster recovery solution.
MM2 (KIP-382) fixes the limitations of Mirrormaker 1 with the ability to dynamically change configurations, keep the topic properties in sync across clusters and improve performance significantly by reducing rebalances to a minimum. Moreover, handling active-active clusters and disaster recovery are use cases that MM2 supports out of the box.
MirrorMaker2 Architecture
MM2 is based on the Kafka Connect framework and can be viewed at its core as a combination of a Kafka source and sink connector. In a typical Connect configuration, the source-connector writes data into a Kafka cluster from an external source and the sink-connector reads data from a Kafka cluster and writes to an external repository. As with MM1, the pattern of remote-consume and local-produce is recommended, thus in the simplest source-target replication pair, the MM2 Connect cluster is paired with the target Kafka cluster. Connect internally always needs a Kafka cluster to store its state and this is called the “primary” cluster which in this case would be the target cluster. In settings where there are multiple clusters across multiple data centers in active-active settings, it would be prohibitive to have an MM2 cluster for each target cluster. In MM2 only one connect cluster is needed for all the cross-cluster replications between a pair of datacenters. Now if we simply take a Kafka source and sink connector and deploy them in tandem to do replication, the data would need to hop through an intermediate Kafka cluster. MM2 avoids this unnecessary data copying by a direct passthrough from source to sink.
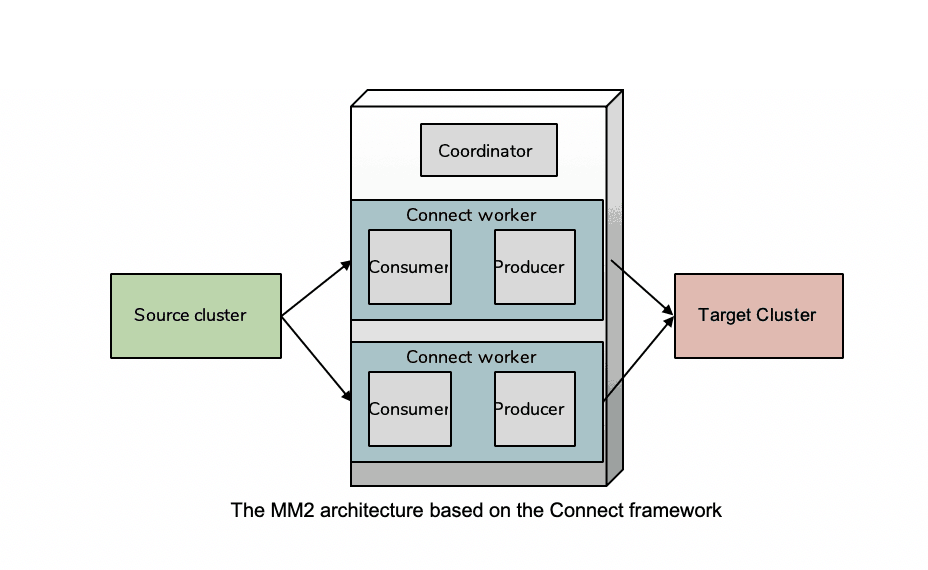
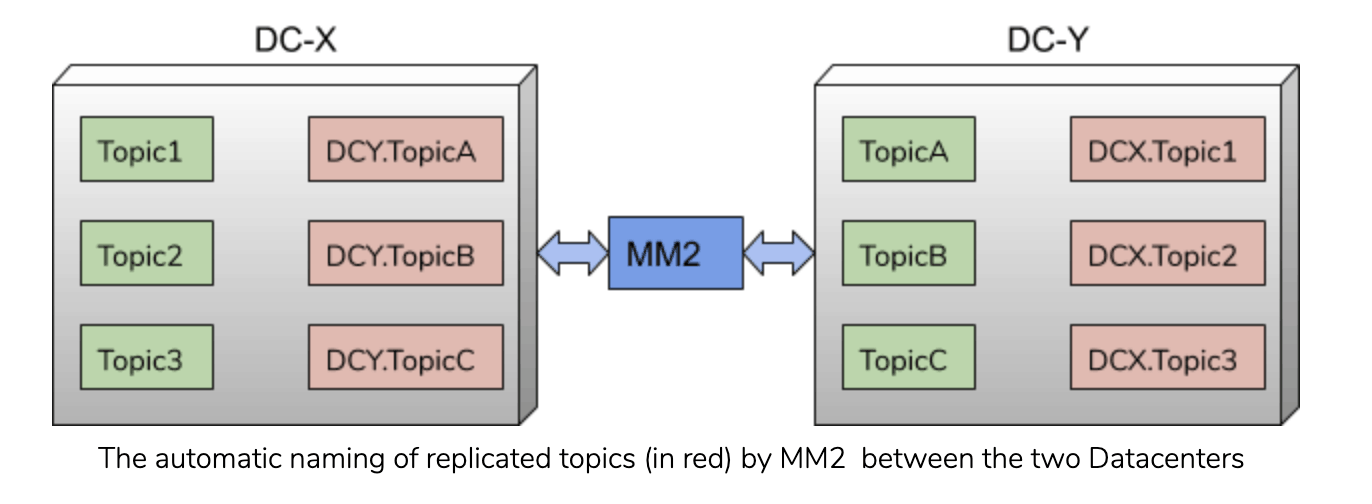
In MM1 the topic name at the source is typically the same at the target cluster and is automatically created in the downstream cluster. Such a naming process causes a bidirectional active-active setup to create an infinite loop. MM2 fixes this by automatically adding a preconfigured prefix (e.g, the source cluster alias which is human-readable alias of the clusterid) to the target topic name.
For example, consider two clusters in two datacenters DC-X and DC-Y replicating in an active-active setup ,
DC-X Topics: Topic_1, Topic_2, …
DC-Y Topics: Topic_A, Topic_B, …
If MM2 is setup to replicate from DC-X to DC-Y and vice versa the following topics will exist in both clusters:
DC-X Topics: Topic_1, Topic_2, …, DC-Y.Topic_A, DC-Y.Topic_B,…
DC-Y Topics: Topic_A, Topic_B, …, DC-X.Topic_1, DC-X.Topic_2,…
MM2 filters out any topics that carry the target cluster name in the prefix. A consumer can subscribe to the super topic e.g., “*TopicA” to consume from the source cluster and continue consuming from the target cluster after failover.
More Balance less Rebalance
Internally, MirrorMaker2 uses the Kafka Connect framework which in turn use the Kafka high level consumer to read data from Kafka. Kafka high level consumer coordinates such that the partitions being consumed in a consumer group are balanced across the group and any change in metadata triggers a consumer rebalance. Similarly, each time there is a change in topics, say when a new topic is created or an old topic is deleted, or a partition count is changed, or there is a source cluster change event, or when Connect nodes are bounced for a software upgrade, or the number of Connect workers are changed or worker configuration is changed it triggers a Connect workers cycle of stop/rebalance/start. Frequent rebalances cause hiccups and are bad for the mirroring throughput.
In MM2 the rebalances that are triggered due to change in the topics (when a new topic is created or added to the whitelist or source cluster change events) are avoided by using the low-level consumer to subscribe to a given list of partitions. MM2 uses an internal mechanism to farm out the partitions among these workers/consumers. Instead of the Connect worker’s high-level consumer directly subscribing to the source cluster partitions MM2 will manage this assignment in the Connector leader or controller. The controller tracks the changes at the source cluster and then farms out the partitions to the workers. The workers use the low-level consumer to directly subscribe to the partitions that were assigned to them by the controller thereby eliminating a majority of rebalances.
Thus, any change to the number of topics and partitions does not cause a full rebalance. There are however rebalances triggered by changes to the Connect cluster itself (more worker nodes etc) that cannot be avoided. These changes in most cases are much more infrequent than topic changes.
Offset Mapping
In Mirromaker1, the offsets of a topic in the source cluster and the offset of the replica topic at the target cluster can be completely different based on the point in the topic lifetime that replication began. Thus the committed offsets in the consumer offsets topic are tracking a completely different location at the source than at the target. If the consumers make a switch to the target cluster they cannot simply use the value of the last committed offset at the source to continue. One approach to deal with this offset mismatch is to rely on Kafka’s support of timestamps when doing a failover. Kafka (v0.10) added support for timestamps that are set by the producer at message create time (or by the broker when the message is written). If the timestamp is carried forward by Mirroring process then the target cluster will have the timestamp of the source message.
Say a consumer at the source cluster had committed offset O_s (in the __consumer_offsets topic) and that message had a timestamp T_s. When the consumer fails-over to the target cluster it has to find out the offset at the target O_t which corresponds to the original timestamp T_s. Now recall that mirroring is an asynchronous process so it is possible that the target cluster may not yet have seen the message with a timestamp T_s. If the consumer tries to find the offset corresponding to T_s it may result in an offset out of range which would reset the offsets to the beginning or end both of which are not desirable. To find a reasonable “guess” of the target offset one approach is to timebound the lag in the mirroring pipeline to 𝛕. Knowing the maximum delay by which mirroring can lag, on failover the consumer can rewind to the offset corresponding to the timestamp T_s -𝛕 by using consumer.offsetsForTimes() and then seeking to that offset consumer.seek(). This offset, however, may not exist as this timestamp may not map to an actual message timestamp. The consumer needs to “guess” to find one closest to that time and start consuming from that offset. A few messages may be reread in the process!
In MM2, this entire guesswork is eliminated. MM2 uses 2 internal topics to track the mapping of source and target offsets as well as the mapping between the source consumer_offsets to the target offset. The offset_sync topic at the target cluster maps the source topic, partition and offset with the corresponding offset at the target. MM2 gets the target offset from the RecordMetadata returned by producer.send().
For consumers relying on the __consumer_offsets topic to track progress, MM2 maps the consumer offsets in a separate log compacted __checkpoint topic per source cluster. MM2 periodically queries the source cluster for all committed offsets from all consumer groups, filters for those topics and consumer groups that need to be replicated and emits a message to the internal checkpoints topic at the target cluster. These checkpoint records are emitted at a configurable interval that can be dynamically controlled.

Using the checkpoint topic, a consumer, on failover, can directly determine (using the MM2 utilities) the target offset corresponding to the source committed offset that it needs to start consuming from.
More on how failover and failback is handled is discussed in the next blog in the series: “Handling Disaster Recovery with MM2”.
Consolidated MirrorMaker Clusters
Traditionally a MirrorMaker cluster is paired with the target cluster. Thus there is a mirroring cluster for each target cluster following a remote-consume and local-produce pattern. For example, for 2 data centers with 8 clusters each and 8 bidirectional replication pairs there are 16 mirrormaker clusters. For large data centers, this can significantly increase the operational cost. Ideally there should be one MirrorMaker cluster per target data center. Thus in the above example, there would be 2 Mirrormaker clusters, one in each data center.
Internally the Kafka Connect framework assumes that a source connector reads from an external source and writes to Kafka while a sink connector reads from Kafka and writes to an external sink. In MM2 there needs to be one connect cluster per target data center thus all clusters replicating across a pair of data centers can be handled by a single MM2 cluster.
Flexible Whitelists and Blacklists
To control what topics get replicated between the source and target cluster Mirrormaker uses whitelists and blacklists with regular expressions or explicit topic listings. But these are statically configured. Mostly when new topics are created that match the whitelist the new topic gets created at the target and the replication happens automatically. However, when the whitelist itself has to be updated, it requires mirrormaker instances to be bounced. Restarting mirrormaker each time the list changes creates backlogs in the replication pipeline causing operational pain points. In MM2 the configuration of the topic lists and regex can be changed dynamically using a REST API.
What is coming next in MirrorMaker 2
Cross-cluster Exactly Once Guarantee
Kafka provides support for exactly-once processing but that guarantee is provided only within a given Kafka cluster and does not apply across multiple clusters. Cross-cluster replication cannot directly take advantage of the exactly-once support within a Kafka cluster. This means MM2 can only provide at least once semantics when replicating data across the source and target clusters which implies there could be duplicate records downstream.
Does this mean MM2 cannot support exactly-once semantics for replicated data?
Actually, it can. Let’s dig a bit into where exactly once processing breaks in replication. If you look at replication to be, at its core, a consume from source cluster and produce to target cluster then the consumer state is being tracked by a write to the __consumer_offsets topic at the source while the data is being produced or written to the topic at the target cluster. These two “writes” cannot be controlled by an atomic transaction as they span two different clusters and there is always a chance that on failure they will diverge causing duplicates.
How do we get these 2 writes to be in an atomic transaction? Hint: In MM2 we have a checkpoint topic that is at the target cluster tracking the state of the consumer at the source. MM2 can thus provide exactly-once semantics by leveraging the checkpoint topic write to be in the same transaction as the product to the target topic. MM2 can support exactly-once semantics even across clusters. This feature will be coming soon in MM2’s next iteration.
High Throughput Identity Mirroring
Let’s go back yet again to replication being basically a combo deal of consume from source and produce to target. The APIs used to read and write data are that of any standard producer and consumer which are both record-oriented. In replication, if the source and target are identical in terms of having the same topic, same number of partitions, same hash function, same compression, same serde we call this identity mirroring. In this scenario, which is in fact quite common, the ideal case would be to read a batch of records as a byte stream and write them out without doing any processing. The batch does not need to be decompressed and compressed and deserialized and serialized if nothing had to be changed. Identity mirroring can have a much higher throughput than the traditional approach. This is another feature that will be coming soon in MM2.
Where can I learn more?
If you want to learn more about Mirrormaker2 as well as see a little snippet of Cloudera Streams Replication Manager, register for our upcoming Kafka Power Chat webinar on Simplifying Kafka Replication on September 17th, 2019.
Editor's Choice


I just want to know how i use rest api to change config in mirror maker
You will need a full Connect cluster to use the Connect REST API to control MM2. Unfortunately, this also means you need to configured all of MM2’s Connectors manually. In case you only need to change the topics and groups being replicated, Cloudera’s Stream Replication Manager lets you do this dynamically from a command-line tool. See: https://docs.cloudera.com/csp/2.0.0/srm-using/topics/srm-control.html
So far I haven’t heard anything about how to reconcile with Schema Registry. when mirroring topics between two clusters that each have their own registry. Sharing or replicating a source registry at the target is not always an option, especially in used cases that consolidate/aggregate topics from more than one broker cluster origin.
Is there any hope with MM2 in this particular use case, or does it not address is any better than MM1 did?
Did you find a solution? We are hitting exactly the same problem, and cannot find an easy solution.
We are mirroring topics using MM2, and want to see corresponding topic schemas in the Schema Registry of the target Kafka cluster.
I’m also interested in approaches to mirroring topics between clusters with seperate Schema Registries.
Is it possible to simply mirror the “_schemas” topic?
If the “primary” cluster is the target cluster, how does bi-directional MM2 work between 2 data-centers? In the simplest case would you have one MM2 with one of the “connect workers” “primary cluster” in the local datacenter and one of the “connect workers” “primary cluster” in the remote datacenter?
That’s correct. You usually want one or more MM2 nodes in each data center. Using the –clusters flag, you can restrict specific workers to only produce to specific clusters. See here for an example: https://github.com/apache/kafka/blob/trunk/connect/mirror/README.md#multicluster-environments
Good afternoon.
I would like to know if you could provide an ETA about the next blog entry “Handling Disaster Recovery with MM2”.
Thank you.
Good Day.
How to identify the mirror maker version, I’m not able to find it in kafka folder.
Can anyone help. Thanks
MM2 comes with Kafka 2.4+ and is located in the ./connect folder.
Any idea on , how long it takes to mirror the 3TB data to new cluster?
Replication latency across clusters can be as low as a few milliseconds, once replication is caught up to real-time. To get up to speed quickly, try increasing “tasks.max” and running MM2 on multiple nodes.
Hello,
Is there a minimum version for the Kafka Cluster on which MM2 is running?
Is it possible to use it to mirror topics to/from a Kafka 1.1 cluster, for example?
Kind regards,
Tim
Some features may not work with very old Kafka clusters. These can be disabled, e.g. “sync.topic.acls.enabled = false”. Apache Kafka 1.1 should work fine out-of-the-box.
In the article there is a part saying that “Using the checkpoint topic, a consumer, on failover, can directly determine (using the MM2 utilities) the target offset corresponding to the source committed offset that it needs to start consuming from.” What is MM2 utilities? I read about connect-mirror-client and the RemoteClusterUtils.translateOffsets method but I could not find any example of usage. Is there a command line tool that wraps this function or how could it be possible to ensure that on failover consumers continue where source cluster left off in order to prevent reading duplicate messages.
Thanks in advance.
In Apache Kafka, the RemoteClusterUtils and MirrorClient classes are provided for this purpose. Cloudera has built additional tooling around these classes as part of our Streams Replication Manager product. For example, see the “srm-control offsets” command: https://docs.cloudera.com/srm/1.0.0/using/topics/srm-control-offsets.html
Thank you for your quick response Ryanne 🙂 We want to set up a multi active/passive kafka cluster in kubernetes environment using Strimzi and MM2 for replication. There will be a load balancer in front of them, only one cluster active and under traffic , the topics/groups will be replicated to other cluster. Actually they will run on different data centers. When there is a problem failover will be done from load balancer. We must be ensure that after the failover we are not consuming duplicate messages. We register the original and replicated topic at the same time so that when failover occurs there will be no need of application change as it is suggested in this blog. Under these circumstances what should we do in the failover time? Actually this issue https://issues.apache.org/jira/browse/KAFKA-9076 addresses the problem. Do we have to write a code in an application to trigger the RemoteClusterUtils (then what should be the properties map which is the first parameter of translateOffset method) find out all groups and set seek to the calculated offset or KAFKA-9076 this solves the issues and to be merged in the future?
Thanks in advance
Hello Ozgur Sucu, your scenario looks very interesting. Did you tried RemoteClusterUtils?
Does Mirror Maker 2 support `messageHandlers` ?
Referring to the line
Now if we simply take a Kafka source and sink connector and deploy them in tandem to do replication, the data would need to hop through an intermediate Kafka cluster. MM2 avoids this unnecessary data copying by a direct passthrough from source to sink.
how exactly would this work? In my scenario I have a Kafka Connect cluster already running and I’m trying to run a MirrorSourceConnector with a config targeting a kafka cluster which is not the primary for kafka connect. But I still see the messages being written to my primary cluster and not my target cluster specified in the config.
First I’d like to thank Apache Kafka Mirror Maker 2 code committers for your effort on this project. I am running a POC to see if we can use MM2 for DR in Active / Passive mode. Below I have listed the requirement, test cases executed along with the results and an understanding of the issue that I see.
Requirement: Need to provide DR for a large Kafka cluster with High Partition Count in the order of 30K, few hundred Terra Byte of data and growing on the primary site.
DR sites DR1 (primary) and DR2 (secondary). When DR1 fails DR2 will become primary until DR1 recovers.
Having prefix of cluster alias to topics would double the partition count and may result in adding more servers to the cluster to have the same performance(without this solution of DR). Due to this high partition count we don’t want to create topics with prefix of cluster on the remote kafka cluster.
Test Cases:
Test case1: Used custom class for replication.policy.class to create topic on remote without prefix.
Result: Passed
Test case2: Replication of data from topicA (DC1) to topicA (DC2) when messages were produced to topicA (DC1)
Result: Passed
Test case3: Replication of data from topicA (DC1) to topicA (DC2) after restarting MM2. Only messages that were not copied should be transferred to DC2.
Result: Passed
Issue to be resolved:
At this point I was looking at Replicating data from DC2 to DC1. I understand that by having cluster alias as prefix we avoid cycle (providing DAG behavior). But as said above to have a cost effective solution we don’t have prefix.
MM2 should start copying only new messages in DC2 avoiding Cyclic message copies. To have this implemented I was looking at seeking to the offset in DC2 topicA. I thought of using mm2-offset-syncs.DC2.internal in DC1 cluster which should have the mapping of DC1 topicA offset to DC2 topicA offset. But this topic mm2-offset-syncs.DC2.internal in DC1 had offset mapping only for every start of MM2 that copied from DC1 -> DC2 and NO further offset mapping, in-spite of successful copying from DC1->DC2 for topicA. I validated the offsets of topicA on both DC1 and DC2 and they were increasing but NO offset mapping updates in mm2-offset-syncs.DC2.internal.
When I checked how MM2 upon restart resumes replicating from where it left, I saw it uses mm2-offsets.DC2.internal topic but the Data dump of this topic had only heartbeats.
I took a look at the code of MirrorSourceTask that does this task of copying and writing to mm2-offset-syncs topic.
Please let me know if I am missing anything here. Thanks
“But this topic mm2-offset-syncs.DC2.internal in DC1 had offset mapping only for every start of MM2 that copied from DC1 -> DC2 and NO further offset mapping, in-spite of successful copying from DC1->DC2 for topicA.”
This is intentional. If it weren’t so, offset-syncs topic could become huge (offset sync record for _every_ message replicated). And basically it isn’t even necessary. The mapping between the upstream (source) and downstream (target) offsets for a topic-partition in ideal case can be described with a single number representing the source offset, when the topic -partition had begun being replicated. If this number is, for instance “k” a message being at offset “n” in the source can be found at offset “n-k” in the target. It is because every message is replicated from partition to partition. However, reality is not ideal. So MM2 instead, creates offset-sync messages whenever upstream and downstream topic-partitions get out of sync. In a case of network glitch, or in the case startup.
So, basically, with that data offsets can be reliably calculated.
For you other implicitly stated question: I don’t think, that a DC2->DC1 replication back to the original topic makes
sense. Mirromaker2 had not been designed with this use case in mind. With the custom “identity” replication policy, it can be attempted – but, I think, it can break offset translation. Offset translation calculates the mapping between
upstream and downstream offsets. To calculate this mapping, it uses the offset checkpoints derived from offset syncs. However, if someone replicates data back to an “original” topic, the offset-syncs will be stored at two different
places, namely, mm2-offset-syncs.DC1.internal, and mm2-offset-syncs.DC2.internal residing on two different clusters. MM2 won’t correctly translate offsets anymore, because it would use only one of those topics, completely ignoring the data in the another.
I am trying to utilize MM2 for Kafka DR in active -passive model but looks like offset syncronization is not working as expected. Here is my use case :
1. produce 10 msg on primary .
2. consumer 5 msg form primary cluster
3. close primary produce & consumer
4. make a DR scenario by putting instance count of primary kafka as 0 , or some other way to shut down primary kafka tempoary
5. after 2-3 minutes start consumer on seconday kafka and see if it receives mesage from beginning or form 6th
6. Ideally if offset mgmt is happening , it should have pick up form 6th , but it is picking from 0 itself.
am I missing anything in MM2 configuration?
Please note , that consumer group id is same for both consumers (primary & secondary).
“For consumers relying on the __consumer_offsets topic to track progress, MM2 maps the consumer offsets in a separate log compacted __checkpoint topic per source cluster.”
In our use case, we are proposing to manage offsets externally within the consumer’s database (to overcome two phase commit challenges) therefore the consumer’s data and the offsets are committed atomically. This offset may not be same as that of Consumer_Offsets topic, therefore, we use the ‘Seek’ method to reset the consumer offsets for any restarts. However, during a failover scenario to secondary DC, how do we translate the offsets to target cluster ? In MM2, Is there any utility to translate the offset that is stored externally within the Consumer’s database ? Should we use the Offset_Sync topic ?
Hi , I have a situation where I can’t deploy Mirror Maker on the target data center ( DC2) .
Can I deploy the Mirror Maker on the Source data center ( DC1 ) ?
Use Caes :
DC1 – Kafka cluster; DC2 – Kafka Cluster
1. publish/replicate Kafka events from DC1 to DC2
2. consumer/replicate Kafka events from DC2 into DC1
tnx !
Hi Alon,
Yes you can. Even though we recommend to follow the pattern of remote-consume and local-produce, there is no hard coded limitation in Mirror Maker 2 that would prevent you from running Connect workers on your source cluster.
Make sure to test the setup in your environment to make sure it can properly handle the amount of data you want to replicate.
I understand MM2 Does not give guarantee of producer once, In case of duplicate message Will it still maintain correct offset?? Also does is copy all internal topics like _schemas, _offset etc ?
MM2 is just byte array. Schemas are not copied over. You would have to mirror the topic _schemas too to get the schemas.
Do I understand correctly that the offsets no longer need to be reset or translated with Mirrormaker 2.0 and SRM. Can consumers continue without intervention in the backup data center except that the connection to the backup cluster has to be established?
If offsets need to be exported and reset, can this step be automated with srm-control?