

The previous two sections have concentrated on infrastructure considerations and services and role layouts for categories of workloads such as Analytic DB and Operational DB. Many of the concepts described therein apply predominantly to on-premise clusters while others apply to clusters deployed on-premise or in the cloud. This section will concentrate predominantly on those considerations that apply to cloud deployments only.
At the time of this writing, Cloudera supports 3 Infrastructure as a Service (IaaS) platforms: Amazon Elastic Compute Cloud (AWS), Microsoft Azure, and Google Cloud Platform (GCP). For Platform as a Service (PaaS) offerings Cloudera Altus Cloud runs on AWS and Microsoft Azure. For best of breed implementations on each IaaS platform, certain considerations must be addressed. Unless indicated otherwise in the Reference Architecture documents, the same concepts outlined in the previous two sections apply to cloud deployments as well.
Disks Layouts
AWS:
On AWS, Cloudera supports the use of both Elastic Block Storage (EBS) and ephemeral (instance) storage (for more on the difference between each, see here) for Master and Worker nodes. When using EBS storage, EBS-optimized instances should be considered and GP2 volumes are required for EBS-backed Masters. When using ephemeral (instance) storage, Cloudera recommends the largest instances types to eliminate resource contention from other guests and to reduce the possibility of data loss. Also, with ephemeral storage, ensure that data is persisted on durable storage before any planned multi-instance shutdown and to protect against multi-VM datacenter events. Here is a proposed outline of disk setup for the various components for AWS implementations:
- Operating System: Cloudera requires using EBS volumes with at least 500 GB to allow parcels and logs to be stored. You should not use any instance storage for the root device.
- Database: Your metastore RDBMS data should be on a dedicated volume or be deployed on RDS. EBS GP2 volumes or ephemeral storage that is persisted on durable storage during planned maintenance. NOTE: You can set up a scheduled distcp operation to persist data to AWS S3 (see the examples in the distcp documentation) or leverage Cloudera Manager’s Backup and Data Recovery (BDR) features to backup HDFS data and metadata natively to AWS S3 or other clusters.
- HDFS JournalNode: Because of the throughput and IOPS of GP2 volumes, the JournalNode process could be on a shared volume with the HDFS NameNode and Zookeeper. When using ephemeral storage, a dedicated volume is recommended and data must be persisted on durable storage during planned maintenance.
- ZooKeeper: See HDFS JournalNode.
- HDFS NameNode: See HDFS JournalNode.
- HDFS DataNode/Kudu Tablet Server: A set of dedicated volumes per worker hosting the HDFS DataNode is recommended.
- Kudu Write-Ahead Log (WAL): A dedicated volume is highly recommended for Kudu’s write-ahead log, required on both Master and Tablet Server nodes.
- Kafka Brokers: Dedicated volumes are recommended for Kafka Brokers.
- Flume: Edge nodes running Flume may consider dedicated volumes when leveraging Flume’s File Channel.
- Raw Data: EBS or ephemeral storage that is persisted on durable storage during planned maintenance.
Microsoft Azure:
On Azure, Cloudera requires the use of Premium Storage Disks for certain roles but supports the use of Standard or Premium Storage Disks for workers. Mixing different storage types per instance is not supported. When using Standard Disks, nodes require a dedicated 128 GB or greater log disk (P20 or P30). Also, TRIM/UNMAP should be implemented to free space from deleted files. Here is a proposed outline of disk setup for the various components for Azure implementations:
- Operating System: A Standard or Premium Storage Disk can be used for the OS. However, each node requires an additional dedicated P20 or P30 log disk.
- Database: Your metastore RDBMS data should be on a dedicated Azure Premium Storage disk in order to meet throughput and latency requirements for Cloudera Enterprise.
- HDFS JournalNode: Each JournalNode process should have its own dedicated Premium Storage Disks.
- ZooKeeper: Cloudera requires using Premium Storage data disks for ZooKeeper data to ensure low and consistent latency.
- HDFS NameNode: Each NameNode process should have its own dedicated Premium Storage Disks.
- HDFS DataNode/Kudu Tablet Server: A set of dedicated Standard or Premium Storage Disks per worker hosting the HDFS DataNode is recommended.
- Kudu Write-Ahead Log (WAL): A dedicated disk is highly recommended for Kudu’s write-ahead log, required on both Master and Tablet Server nodes. Premium Storage Disks are recommended.
- Kafka Brokers: Dedicated disks are recommended for Kafka Brokers. Logging and data directories must be configured to use persistent Premium Storage or Standard Storage disks.
- Flume: Edge nodes running Flume may consider dedicated volumes when leveraging Flume’s File Channel. Cloudera requires file channels be located on attached Premium Storage or Standard Storage data disks in Microsoft Azure.
Google Cloud Platform:
On GCP, the recommended storage option is standard persistent disks. These drives provide linearly scaling performance with volume size. Another option is Local SSD which provides local-attached storage to VM instances, providing increased performance at the cost of availability, durability, and flexibility. The lifetime of the storage is the same as the lifetime of the VM instance. If you stop or terminate the VM instance, the storage is lost. Users of local SSD should take extra precautions to backup their data. Review posted Reference Architecture on the recommendations and considerations for machine types with various storage options listed above. You should choose machine types based on the workload you run on the cluster.
Here is a proposed outline of disk setup for the various components for GCP implementations:
- Operating System: By default, each Compute Engine instance has a single root persistent disk that contains the operating system. Local SSD cannot be used as a root disk. The root device size for Cloudera Enterprise clusters should be at least 500 GB to allow parcels and logs to be stored. By default, the root device is partitioned only with enough space for its source image or snapshot; repartitioning the root persistent disk may require manual intervention, depending on the operating system used.
- Database: Your metastore RDBMS data should be on a dedicated disk. Cloudera requires you to provision VM instances and install and manage your own database instance.e. For more information, see to the list of supported database types and versions.
- HDFS JournalNode: Each JournalNode process should have its own dedicated standard persistent storage due to Local SSD not living past the point of VM failure
- ZooKeeper: Each ZooKeeper process should have its own dedicated standard persistent storage due to Local SSD not living past the point of VM failure
- HDFS NameNode: Each NameNode process should have its own dedicated standard persistent storage due to Local SSD not living past the point of VM failure
- HDFS DataNode/Kudu Tablet Server: Cloudera recommends using no more than two standard persistent disks per VM as HDFS DataNode storage with a minimum size of 1.5 TB.
- Kudu Write-Ahead Log (WAL): A dedicated disk is highly recommended for Kudu’s write-ahead log, required on both Master and Tablet Server nodes. Dedicated standard persistent storage is recommended.
- Kafka Brokers: Dedicated disks are recommended for Kafka Brokers. Storage options should be based on the workload that is planned to leverage this service. Please note that with Kafka, maximizing throughput is a typical design requirement. To that end, minimizing vs. maximizing volume size is recommended.
- Flume: Edge nodes running Flume may consider dedicated volumes when leveraging Flume’s File Channel.
Networking
AWS:
Persistent CDH clusters on AWS have similar network architecture & security requirements as on-prem cluster networks. Persistent-cluster AWS networks are generally more complex than ones for transient clusters and require additional effort to set up. Key differences between persistent and transient cluster networks on AWS are listed below:

Begin designing the AWS network for your persistent CDH cluster by reviewing the organization’s currently AWS network – is there AWS Direct Connect, VPN connection, or existing VPC(s), for example. Use the existing architecture to modify the recommended AWS configuration as needed, provided the security and operational requirements are met by the final design.
The objective of the persistent cluster’s AWS network is to have a VPC address space with a private subnet(s) containing all cluster nodes. Selected instances, such as cluster edge-nodes and user/administrator jump box*(es), may need to reside in a public subnet. Data ingest and M2M cluster access may be from edge node(s) or directly to worker node(s) if the organization’s network is integrated with the VPC using AWS DirectConnect or VPN connection.
The public subnet should only be accessible from organization’s address space or specified IP address range(s). The restriction is enforced by a Network ACL (NACL) and/or the organization’s Direct Connect / VPN. HTTP, HTTPS and ephemeral ports (generally 1024-65535) should be allowed by the public NACL if instances on the private subnet need to perform Internet yum updates via a route to a NAT Gateway attached to the public subnet. Note that AWS no longer recommends NAT instances and that NAT Gateways require an Elastic IP (EIP), which is public, persistent and adds additional cost. Public IP addresses for instances on the public-subnet(s), such as jump-boxes and gateway nodes, are not persistent by default. The public subnet’s Route Table should include a route from 0.0.0.0/0 (i.e. all addresses) to the IGW attached to the VPC.
The private subnet NACL should only permit traffic from the public subnet address space to protect the worker, management and security nodes. The private network Route Table should have a route from the private subnet to the public subnet’s NAT Instance, which enables outbound Internet access from the private subnet for the Cloudera code repository. An alternative is to have a custom repository on the private subnet. The private subnet security group should not restrict any ports between cluster nodes. None of the nodes should run iptables or firewalld.
Cloudera recommends a deploying all cluster nodes in a single AZ. If a cluster requires multiple AZs, please see the Cloudera AWS Reference Architecture Appendix A.
Additional recommendations for persistent cluster AWS networks are to tag every object (EC2 instance and network component)- with a distinctive / searchable name and assign a project value. The searchable name can be used by the AWS CLI to identify, script and control cluster nodes. The project tag can be used to generate cost reports.
More details on how to Create and Configure a VPC are in the Cloudera Director documentation.
*A jump-box is also known as a Bastion Host.
Microsoft Azure:
Networking goals for deployment in Microsoft Azure is to provide:
- configurable protection for cluster nodes from external threats,
- convenient access for cluster users & administrators,
- fast network performance within the cluster and Internet access for nodes where desired
You can configure a VNet to connect to your on-premises network through a VPN or VNet Gateway to make the VNet function as an extension to your data center. You can also use ExpressRoute to establish a direct, dedicated link between your on-premises infrastructure and Azure. This provides more secure, faster, and more reliable connectivity than a VPN. ExpressRoute is particularly useful for moving large volumes of data between your on-premises infrastructure and Azure
Azure Virtual Network (VNet) is a logical network overlay that can include services and VMs. Resources in a VNet can access each other. All deployments require a cluster to be placed into a single Virtual Network so the instances can communicate with one another with low latency. Resources must all be located in a single Azure region.
Resources for a cluster will be organized into one or more Resource Groups and configured with Network Security Groups (NSG) to control network access.
The accessibility of the Cloudera Enterprise cluster is defined by the Azure Network Security Group (NSG) configurations assigned to VMs and/or Virtual Network subnets and depends on security requirements and workload. Typically, edge nodes (also known asPer client nodes or gateway nodes) have direct access to the cluster’s internal network. Through client applications on these edge nodes, users interact with the cluster and its data. These edge nodes can run web applications for real-time serving workloads, BI tools, or the Hadoop command-line client used to interact with HDFS.
Azure provides internal name resolution for virtual machines with limitations like fixed DNS suffixes, inability to register custom records, etc.; it is recommended only for name resolution within the cluster. An external name resolution solution is needed for on-prem integration or machines in different virtual network.
Google Cloud Platform:
Each VM instance is assigned to a single network, which controls how the instance can communicate with other instances and systems outside the network. The default network allows inbound SSH connections (port 22) and disallows all other inbound connectivity. Outbound connectivity is not restricted, nor is connectivity between instances on the same network. When provisioned, each VM instance is assigned an internal IP and an ephemeral external IP. Cloudera recommends that you use the internal instance IP addresses when configuring the cluster. More information about instances and network is available in the Google Compute Engine documentation.
High Availability
AWS:
AWS provides a high level uptime service commitment for EC2 instances and multiple hardware failure protections which complement Cloudera’s many HA capabilities & HDFS replication to provide an exceptionally reliable cluster. The inherent latency in network communication between AWS regions prevents CDH clusters from being deployed across regions, but they can span Availability Zones (AZs) within a region if desired. Note that there is an AWS charge for data moving between EC2 instances in different AZs but there is no charge for moving data within an AZ. Refer to Appendix A of the AWS Reference Architecture for more information.
AWS places EC2 instance on underlying instances with Placement Groups, which are either Shared – meaning instances are hosted on the same hardware – or Spread – meaning they are on separate hardware. Cloudera recommends placing management, security and edge nodes such as NameNodes, Key Management / Trustee servers, & Cloudera Manager, on Spread placement groups to protect against the failure of hosting hardware. CDH Worker nodes should be placed in a Shared Placement group, so they can take advantage of the low network latency and high network performance. Note that AWS recommends launching the number of instances needed in a single launch request and using the same instance type to avoid receiving an insufficient capacity error.
Additional HA protection is provided by AWS’ automatic replication of EBS volumes within an Availability Zone. EBS volumes and can have scripted snapshots taken, which can then be replicated to other regions.
Microsoft Azure:
Azure Regions are geographical locations where Microsoft has deployed infrastructure for customers. Each region is self contained and has a deployment of the various Azure services. Cloudera Enterprise clusters are deployed within a single region. Cluster configurations that span multiple regions are not supported.
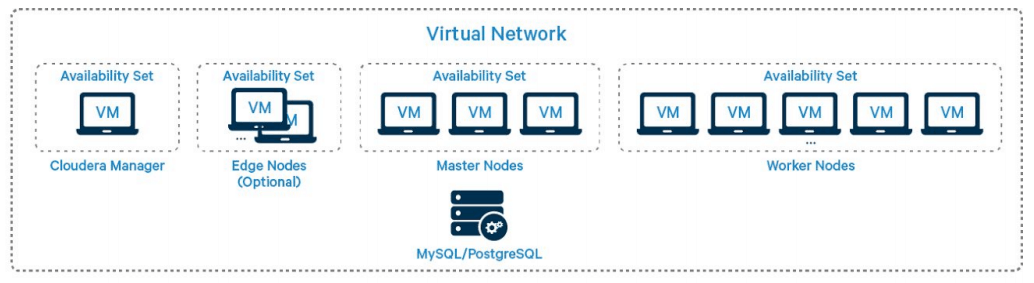
Azure manages the availability of VMs using Azure Availability Sets. Each VM can only belong to a single Availability Set. Microsoft recommends that machines with identical function be placed into an Availability Set, especially if they are configured in a high availability grouping.
Availability Sets currently implement two uncorrelated failure domains. The first is the Fault Domain and is associated with the underlying hardware, networking, and power that are required for the VM to be operational. A single hardware failure can make all machines in a given Fault Domain unavailable. The second failure domain is the Update Domain and it is used for planned maintenance that requires reboot of the hypervisor
We recommend using one Availability Set for Masters, another Availability Set for Workers, and additional Availability Sets for any other group of like-functioning nodes. The number of Fault Domains in each Availability Set should be changed to 3 when it is created. You should use Classic/Unmanaged Availability Sets for deployments that leverage unmanaged disks and Aligned/managed Availability Sets for deployments that leverage managed disks. If there are more than 3 VMs in a set you should associate the nodes with rack locations that match the Azure-assigned Fault Domain or Update Domain. You should be aware of the risk associated with the failure domain that is not mitigated by rack-awareness. Update Domain risk can be minimized by using a larger number of Update Domains when creating the Availability Set (up to 20). Note: Azure Premium Storage and Standard Storage disks provide 3 in-region storage replicas limiting this to an availability problem. Known Limitations There is currently an Azure limitation of 100 VMs per Availability Set. There are also limitations on provisioning VMs from different series (D,DS,DS_V2) into a single Availability Set.
The nodes should be placed into an Availability Set to ensure they don’t all go down due to hardware failure or host maintenance.
Google Cloud Platform:
Cloudera deployments on Google via the Google Compute Engine have the same High Availability (HA) as other infrastructure deployment options. For a list of all considerations, review the HA documentation here. Business SLA and Company Policies should be taken into account to assess the level of HA and backup needs.
Google Cloud Storage can be used to ingest or export data to or from your HDFS cluster. In addition, it can provide disaster recovery or backup during system upgrades. The durability and availability guarantees make it ideal for a cold backup that you can restore in case the primary HDFS cluster goes down. For a hot backup, customers deploy a second HDFS cluster holding a copy of your data.
Cloudera EDH deployments are restricted to single zones. Clusters spanning zones and regions are not supported.
Series Conclusion
Deploying your next Enterprise Data Hub, the platform for Machine Learning and Advanced Analytics, once you have a solid understanding on what you’re trying to achieve and bringing the EDH platform in line with your goals.
Gaining a general understanding of how to classify the various node types, and how that translates into actual infrastructure requirements is the first step. You should always consider what your security and availability requirements are, where we just assume in this blog that security is a must, and high availability is a given.
We demonstrated a use case of what a deployment could look like when planning to build out environments intended for Analytic DB, Operational DB, and Data Science and Engineering. Carefully considering role layouts early on helps make transitioning to larger clusters easier and more manageable.
Be sure to check out hardware reference architectures provided by Cloudera partners, which are designed hand-in-hand with our team. They are a great starting point for cluster designs, though keep in mind that each cluster situation may be unique and have specific requirements needed for your Enterprise Data Hub implementation. Also because the world of Big Data and Hadoop is not static and evolves rapidly, make sure you often visit our company’s vision as the future of data offers an immense world of opportunities.
Acknowledgements to Alex Moundalexis and Rick Hallihan for contributing to this section of the blog.
Editor's Choice

