

Analytical and operational access patterns are very different and until now the Hadoop ecosystem has not had a single storage engine that could support both. As a result, engineers have been forced to implement complex architectures that stitch multiple systems together in order to provide these capabilities. On one hand immutable data on HDFS offers superior analytic performance, while mutable data in Apache HBase is best for operational workloads. Apache Kudu bridges this gap.
Kudu’s architecture is shaped towards the ability to provide very good analytical performance, while at the same time being able to receive a continuous stream of inserts and updates. It does a great job of encapsulating any complexity away from the user through its simple API, allowing them to focus on what they care about most; the application. But some advanced users will want to understand the internals in order to appreciate how Kudu is able to support fast analytics on fast data, and how to leverage its functionality better. The aim of this post is to give users an introduction to what happens under the hood when you write data to, and read data from Kudu. This post assumes a basic understanding of Kudu’s architecture, which is covered in the documentation.
Multi-version concurrency control (MVCC)
Databases use concurrency control methods to ensure that users always see consistent results in spite of concurrent write operations. Kudu uses a method called MVCC, which tracks ongoing operations and ensures consistency by making sure that reads can only observe operations that have been committed. The key benefit of Kudu’s use of MVCC is that it allows readers (usually large scans) to not have to acquire locks, and analytics jobs will not block concurrent writers on the same data, which significantly improves scan performance.
Every write is tagged with a system-generated timestamp that is guaranteed to be unique within a tablet. When a user creates a scanner to read data from a tablet, they can choose between two read modes:
- READ_LATEST (default) takes a snapshot of the current state of MVCC in a tablet, without any guarantee of recency. That is, it reads any writes that have been committed on a replica, but because writes can commit out-of-order, there is no consistency guarantee. And because the replica may be lagging behind other replicas of the same tablet, there is no guarantee of reading the latest version
- READ_AT_SNAPSHOT takes a snapshot of MVCC that includes the version of rows based on a specific timestamp, be it user-selected or system-selected (the “current” time). The tablet waits until this timestamp is “safe” (i.e. all in-flight write operations with a lower timestamp have completed), and further writes to the tablet will be ignored by the scan because they will have a later timestamp. In this mode, scans are consistent and repeatable.
By providing your own scan timestamp, the latter snapshot type enables the ability to issue “time travel reads”, which reflect the state of the database at that point in time.
What this means is a user will only ever see a single version of a row, but internally Kudu can store multiple versions of a row to provide MVCC snapshot capabilities.
Raft
Tables in Kudu are split into contiguous segments called tablets, and for fault-tolerance each tablet is replicated on multiple tablet servers. Kudu uses the Raft consensus algorithm to guarantee that changes made to a tablet are agreed upon by all of its replicas. At any given time, one replica is elected to be the leader while the others are followers. Any replica can service reads, but only the leader can accept writes. Raft keeps a replicated log of operations, and a write is only acknowledged once it has been persisted in the log by a majority of replicas. The replicated log is an abstract concept that is actually represented by the tablet’s write ahead logs (WAL). A tablet with N replicas (usually 3 or 5) can continue to accept writes with up to (N – 1) / 2 faulty replicas.
Tablet discovery
When a Kudu client is created it gets tablet location information from the master, and then talks to the server that serves the tablet directly. To optimise the read and write paths, clients keep a local cache of this information to prevent them from having to query the master for tablet location information on every request. Over time a client’s cache can become stale and when a write is sent to a tablet server that is no longer the leader for a tablet, it will be rejected. The client will then update its cache by querying the master to discover the new leader’s location.
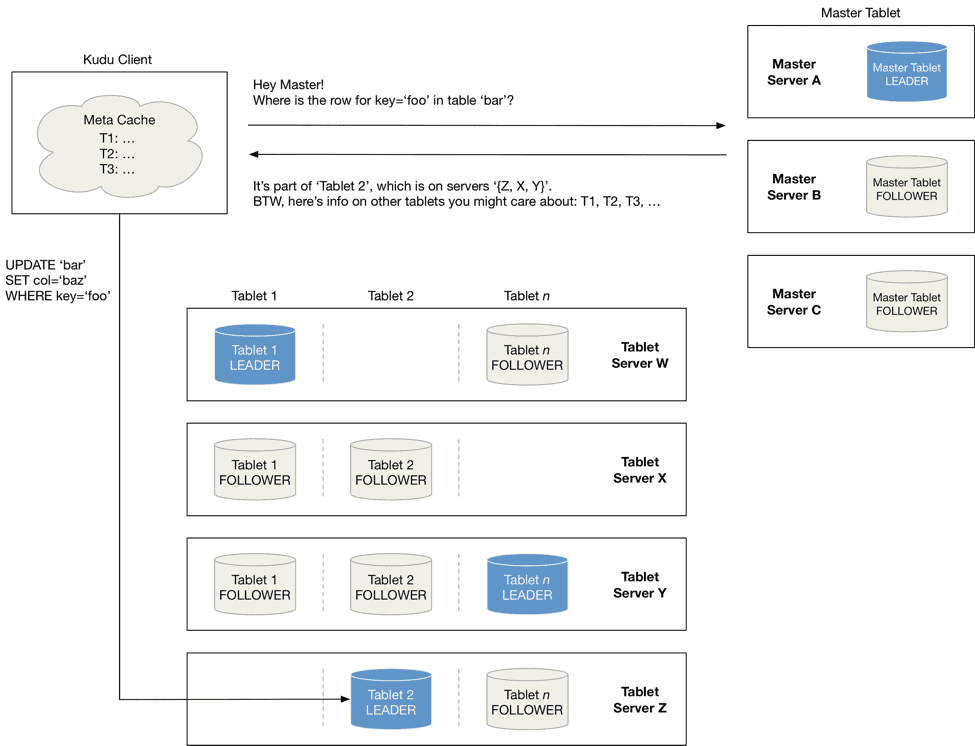
Write path
Write operations are a set of rows to be inserted, updated, or deleted. An important consideration to note is Kudu enforces primary key uniqueness, and the primary key is the sole identifier by which rows can be changed. To enforce this constraint, Kudu must handle insert and update operations differently, and this influences how writes are handled by the tablet servers.
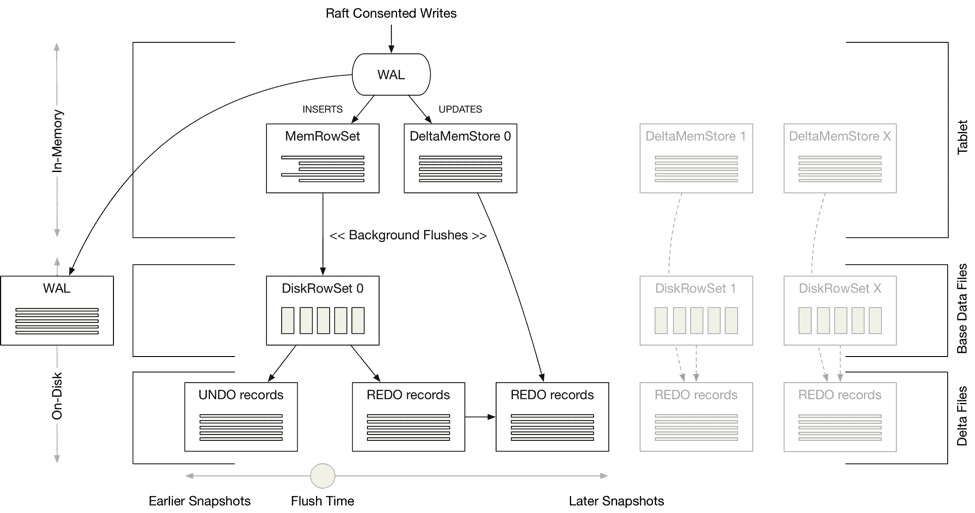
Each tablet in Kudu comprises of a write ahead log (WAL) and a number of RowSets, which are disjoint sets of rows that are held in-memory and (when flushed) on disk. Writes are committed to a tablet’s WAL and agreed upon according to Raft consensus, before being added to one of the tablet’s in-memory stores:
Inserts are added to a tablet’s MemRowSet. In order to support MVCC in the MemRowSet, updates and deletes to recently inserted rows (i.e. new rows that have yet to be flushed to disk) are appended to the original row in the MemRowSet to form a list of REDO records. Readers need to apply the relevant REDO records to build the correct snapshot of a row based on the scanners given timestamp.
When the MemRowSet fills up it is flushed to disk and becomes a DiskRowSet. In order to support MVCC for on-disk data, DiskRowSets are split into two different file types. The latest version of a row in the MemRowSet (i.e. the original insert with all of its REDO records applied) is written to a base data file. This is a columnar file format (much like Parquet) for fast, efficient read access and is what gives Kudu the ability to support analytical access patterns. The previous versions of a row that existed in the MemRowSet (i.e. the inverse of the REDO records) are written to a delta file as a set of UNDO records. Time travel reads can then apply the relevant UNDO records to build the correct snapshot of a row from an earlier point in time.
Updating a columnar formatted data file that is encoded and compressed would require rewriting the entire file, and for this reason the base data files are considered immutable once flushed. In addition, the row key uniqueness constraint means that updates and deletes to the base records cannot be added to a tablet’s MemRowSet, and instead they are added to a separate in-memory store called a DeltaMemStore. Much like the MemRowSet, mutations are added to the DeltaMemStore as a set of REDO records, and when the DeltaMemStore fills up the REDO records are flushed to a delta file on disk. A separate DeltaMemStore exists for every DiskRowSet. To build the correct snapshot of a row, a reader must first find the row’s base record before applying the relevant UNDO or REDO records from the delta files.
Compactions
A tablet will accumulate many DiskRowSets over time, and each of these will accumulate many delta REDO files as rows get updated. When inserting a key, to enforce primary key uniqueness, Kudu consults a set of bloom filters for the RowSets whose range might include the key. The more bloom filter checks and subsequent DiskRowSet seeks that a write has to perform, the slower it will become. As more DiskRowSets accumulate, action must be taken to ensure that write performance doesn’t degrade.
Moreover, as more REDO delta files accumulate for each RowSet, the more work scans needs to perform in order to transform the base data into the most recent version of a row. This means that read performance would also degrade over time if no action was taken. Kudu handles these problems by performing compactions. There are three types of compactions:
- Minor delta compaction reduces the number of delta files by merging them together, without touching the base data. The result is reads have to seek fewer delta files to produce the current version of a row.
- Major delta compaction migrates REDO records to UNDO records, and updates the base data. Given that the majority of reads will be for recent snapshots (forward in time from base data), and the base data is stored the most efficiently (encoded and compressed), minimizing the number of REDO records stored will result in more efficient reads. During major compaction, a row’s REDO records can be merged into the base data, and replaced by an equivalent set of UNDO records containing previous versions of the row. Major compaction can be performed on any subset of columns, so compaction can be performed on a single column if it receives significantly more updates than other columns, which reduces the I/O for major delta compactions by avoiding having to rewrite unchanged data.
- RowSet compaction merges together RowSets that overlap in range. This results in fewer RowSets whose bloom filters and indexes must be consulted for each row mutation, thus speeding up writes.
This is a short introduction to the compaction process to give the reader an understanding of the background work that Kudu performs to manage and optimise its physical storage. We will be publishing a follow-up post to describe the compaction process in more detail.
Read path
When a client reads from a table in Kudu, it must first establish the set of tablet servers it needs to connect to. It does this by following the tablet discovery process (described above) to determine the locations of the tablets that contain the primary key ranges predicated in the read (reads don’t have to happen on the leader tablets, unless the user explicitly chooses that option). A scanner is then used by the tablets to materialise visible rows from the RowSets and the relevant UNDO or REDO delta records.
First of all, the tablet must determine the RowSets that include the base records that fall within the range of the scanner. This can include the MemRowSet and one or more DiskRowSets. The tablet will then traverse the selected RowSets and materialise the keys that fall within the given range, while also matching the scan’s predicates.
In the MemRowSet, the scanner will materialise the complete projection of each row, and any delta records will be applied in-line. This is fast because it all happens in memory. For each DiskRowSet, the scanner will materialise a column at a time, and apply any delta records and predicates before moving on to the next column. Only the columns that match the scan’s predicates will be read from disk, which makes disk I/O very efficient and is what gives Kudu its fast analytical performance. Kudu prioritises scanning the columns for which predicates have been defined. This allows Kudu to completely avoid scanning other columns if the predicates are not satisfied, thus avoiding unnecessary I/O.
We hope that this post provides a clear and concise overview of Kudu’s read and write paths, and gives the reader an appreciation of how Kudu is able to support fast analytical access patterns, on continuously changing data. We will be publishing two follow-up posts that cover transactions, and the compaction process in more detail. To dive deeper into the detail, and to get involved in the project, please visit the Apache Kudu website.
James Kinley is a Principal Solutions Architect at Cloudera.
David Alves in a Software Engineer at Cloudera and Apache Kudu Committer and PMC
Editor's Choice


James,
The document is very deep and easy to understand. Appreciate your efforts to create this blog. After almost 3 years of this blog, it’s still hard to find this much detailed discussion on Kudu architecture functioning. It would be very helpful if you could post details regarding compaction and how it affects read/writes get operations. Also please try to include more diagrams.
Samir