

Cloudera considers the handling and reporting of security vulnerabilities a very serious matter. In this post, learn the processes involved.
In addition to expecting enterprise-class standards for stability and reliability, Cloudera’s customers also have expectations for industry-standard processes around the discovery, fix, and reporting of security issues. In this post, I will describe how Cloudera addresses such issues in our software.
An overview of the process looks like this flowchart:
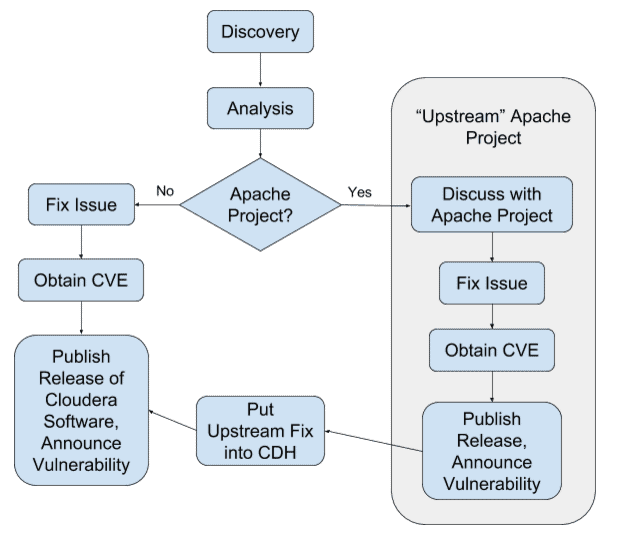
The first step in the life cycle of a security vulnerability is that it is discovered and reported to Cloudera. There are a number of ways that we can learn of a vulnerability:
- It can be reported by someone outside of Cloudera to security@cloudera.com
- It can be reported to the Apache community directly, and we learn of it from our involvement in the community. For example, a user could post a vulnerability in core Apache Hadoop to the private security@hadoop.apache.org mailing list.
- It can be discovered internally.
- It can be a vulnerability in third-party software upon which we rely. Two examples of this situation include the Apache Commons Collections vulnerability and POODLE (PDF). While these weren’t vulnerabilities in code that Cloudera wrote, we either shipped or interacted with the software with the vulnerability.
In the Analysis phase, engineers spring into action to determine the severity, impact, and repercussions of the issue. The overall severity of security vulnerabilities depends primarily on two factors: the ease of exploitation and the severity of the vulnerability. For example, if an exploit can be performed remotely (in other words, over the network) and the result is that the attacker gets access to sensitive data, that’s about as bad as it can get. If an exploit is really difficult and yields little new information, that’s a very mild issue. Most exploits lie somewhere in between.
If the vulnerability is in an Apache project, the actions we take move to the upstream community. The Apache Software Foundation has a well established process in place already that specifies how projects handle security issues; the outline of this process is roughly:
- Deal with the issue completely on a private mailing list and not in a public JIRA.
- Agree on a fix and implement it.
- Request a CVE number (more on this in a bit).
- Commit the fix, publish a release with the fix, and then report the fix publicly.
Once this process is complete in the upstream community, Cloudera will incorporate the fix into our software, publish a release with the fix, and publicly announce the issue and fix.
If the vulnerability is in Cloudera-controlled software such as Cloudera Manager, the process is basically the same except that discussion is kept privately inside the company.
Frequently this process is complicated by the scope of the security vulnerability. One good example was the POODLE vulnerability in SSLv3. This vulnerability basically made SSLv3 obsolete overnight, and software needed to turn off support for it – and this had to happen with basically every component in the system. (Imagine the right half of the flowchart above being repeated a dozen times!)
Handling of CVEs
The term CVE stands for “Common Vulnerabilities and Exposures.” “CVE numbers” are used to uniquely identify security vulnerabilities. For example, CVE-2014-3566 uniquely identifies the POODLE vulnerability in SSLv3. The middle set of numbers is the year of discovery, and the latter set of numbers is just an integer that starts at 1 each year and is incremented for each vulnerability reported. These CVEs all make their way into the “CVE Database,” which is controlled by an organization called MITRE.
The process for interacting with MITRE is somewhat unique. The first step is to acquire a CVE number. This can be done by sending an email to cve-assign@mitre.org, or some larger companies have a pool of spare CVEs they keep around. When the vulnerability is publicly announced, the CVE number is used. MITRE keeps an eye on places like the Bugtraq mailing list and other forums for the used CVE numbers, and brings the information into their database. They can also be pushed information about published vulnerabilities directly.
Once the vulnerability is fixed, that fix has to be added to a software release. For many classes of vulnerability we will actually will add it to more than one release to give it the broadest applicable coverage. In Cloudera, we have a fairly predictable release cycle; occasionally we accelerate release dates so that the fixes get to our customers more quickly.
Customer Notifications
Cloudera also has a special process for notifying customers of fixes for security vulnerabilities: We issue Technical Support Bulletins (TSBs) that are emailed to customers and also appear on our web site. These security bulletins contain information such as
- A general description of the vulnerability and the fix
- The releases affected
- The severity of the issue
- The CVE number
The interaction we have with MITRE can sometimes take awhile. While we make efforts to ensure that we report these vulnerabilities to the folks at MITRE in a timely fashion, as of the spring of 2016 they have experienced a huge backlog of vulnerabilities. A note on its web site reads:
The recent explosion of Internet-enabled devices—known as the Internet of Things—as well as the propagation of software-based functionality in systems has led to a huge increase in the number of CVE requests we have been receiving on a daily basis. We did not anticipate this rate of growth, and, as a result, were not as prepared for the latest surge in requests over the past 12 months as we had hoped. The result has been some of the delay in CVE assignments that the software security community has recently witnessed. We recognize the inconvenience that has resulted, and are working hard to come up with a solution.
For this reason, if you see us publish a fix to a security vulnerability, but can’t find the CVE number in the MITRE database, you’ll know that it’s working on the issue.
Conclusion
To conclude, fixing security vulnerabilities is taken quite seriously here at Cloudera. As you can see, there’s a lot more to the process than simply writing some code: not only does there have to be engineering agreement, there is also documentation and process to follow to make the experience as safe and predictable as possible
Editor's Choice

