

In this first installment of a multi-part series about Cloudera’s multi-step QA process for CDH releases, learn about the role of static source-code analysis in this strategy.
There are many different ways to examine software for quality and security in software development. Design reviews; code reviews; unit tests; fault injection; system, scale, and endurance tests; and validation on real workloads all play a part in ensuring that code is of high quality, works as intended, and is secure, before any release is done.
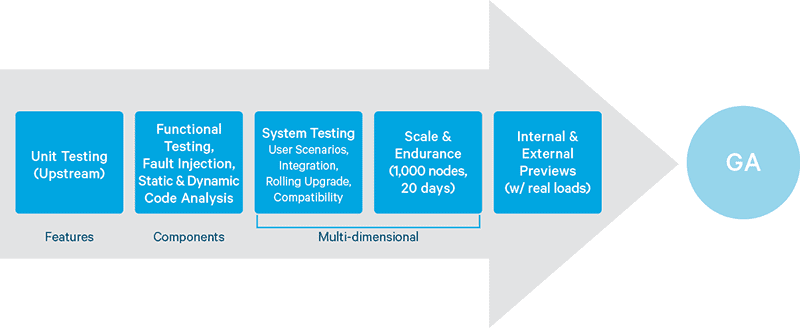
At Cloudera, another complementary way we evaluate code is to subject it to static source-code analysis, in which source code is inspected by a program that looks for common coding errors, defects, security vulnerabilities, and the like. It’s called “static” because the non-running code itself is under inspection (as opposed to dynamic analysis, which analyzes a running program).
In this post, I will describe how Cloudera conducts static source-code analysis, and the results you should expect to see in upstream repositories. Future posts will cover other steps, including fault-injection analysis and validation of real workloads on our internal enterprise data hub.
Static Code Analysis Basics
There are many well known static code analyzers out there. One of the earliest is lint, which was designed to find programming errors in C code: code that compiles, but is either obviously wrong or dangerous. In the Java world, one of the most popular is FindBugs. FindBugs is used in many open source Apache projects; in many cases, it’s impossible to submit code to the project unless it passes a FindBugs check first.
At Cloudera, however, we identified a need for more aggressive use of static code-analysis tools. In particular, we wanted to improve the security of the ecosystem by applying software that scans source code for potential security issues. After analyzing several tools in this space, we chose HPE Fortify.
One of Fortify’s tactics is to analyze the flow of data through a program. For example, if data comes into a web page from an untrusted source, is never appropriately “sanitized”, and is output back to a web page, that’s a recipe for a cross-site scripting attack. Other examples are when a user submits data that might affect files on the filesystem, when a program prints or logs sensitive internal data, and insecure use of cryptography.
Some of these issues are not typically discovered during tests, and aren’t easily visible externally until an attacker discovers them. Some of them can also easily be missed by human code reviewers. So, catching such issues early in the software-development lifecycle benefits everyone.
How Triage is Done
Cloudera installed Fortify in late 2015. We have recently completed scans of all the Apache Hadoop ecosystem components for which we provide support—including Apache Spark, Apache Kafka, and Apache HBase in addition to core Hadoop. We are in the process of analyzing the results and determining which ones are real issues, and which ones are false positives (more on those later).
Fortify ranks issues on a severity scale: Critical, High, Medium, and Low. Critical issues are both immediately exploitable and have serious consequences. High issues are serious, but are either more difficult to exploit or don’t have consequences as serious as Critical issues. Medium and Low issues are areas of concern, but are of less consequence. We plan on a phased approach to examining the reported issues: Critical severity issues first, then High severity, and so on.
Fortify also recognizes that its capabilities are fallible; it only “knows” what’s immediately visible in the code, and as a result it can report issues that aren’t actually a problem. These are called false positives. For example, Fortify will flag a “path manipulation” issue when untrusted user input will modify files on a filesystem. This is a bad thing for a web-based program, which should provide clean separation between the web pages and the contents of the filesystem on the machine on which it’s running. But for Hadoop, it’s often the job of the program to manipulate the filesystem, and as a result, this class of errors may be safe to ignore. Fortify has built a web UI for developers to evaluate and triage issues to easily deal with this false-positive problem.
Conclusion
Addressing false positives is the first step in this process; as real issues are discovered, you should expect us to file and fix bugs in the affected Apache open source projects. Some of these issues may be subject to the Apache security vulnerability process, and so won’t be public until the end of that process.
We hope that our use of Fortify in the overall QA process will make the Apache Hadoop ecosystem safer for everyone! In the next installment in this series, you’ll learn details about how and why fault-injection testing and elastic partitioning are part of the QA process at Cloudera.
Editor's Choice

