

Recent improvements to Apache Hadoop’s native backup utility, which are now shipping in CDH, make that process much faster.
DistCp is a popular tool in Apache Hadoop for periodically backing up data across and within clusters. (Each run of DistCp in the backup process is referred to as a backup cycle.) Its popularity has grown in popularity despite relatively slow performance.
In this post, we’ll provide a quick introduction to DistCp. Then we’ll explain how HDFS-7535 improves DistCp performance by utilizing HDFS snapshots to avoid copying renamed files. Finally, we’ll describe how HDFS-8828 (shipping in CDH 5.5) improves performance further on top of HDFS-7535.
How DistCp Works (Default)
DistCp uses MapReduce jobs to copy files between clusters, or within the same cluster in parallel. It involves two steps:
- Building the list of files to copy (known as the copy list)
- Running a MapReduce job to copy files, with the copy list as input
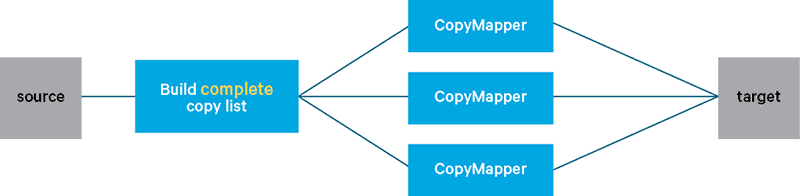
The MapReduce job that does the copying has only mappers—each mapper copies a subset of files in the copy list. By default, the copy list is a complete list of all files in the source directory parameters of DistCp. But as you might expect, that process can take a long time, particularly when a large directory and/or many subdirectories are involved.
The HDFS-7535 Improvement
HDFS-7535 improves DistCp performance by not copying renamed files. In other words, if a file was copied in previous backup cycle and then renamed, it doesn’t need to be copied again. HDFS-7535 utilizes the HDFS snapshot feature to achieve that goal.
HDFS snapshots are read-only point-in-time copies of HDFS. It takes O(1) time to create a snapshot and multiple simultaneous snapshots can be done. The feature also provides an RPC to get a snapshots difference (“diff”) report between two snapshots. A typical snapshots diff report includes all differences between two snapshots, and represents the differences with four types of operations, whose operands are either files or directories:
CREATE: newly created files/directoriesDELETE: files/directories deletedRENAME: files/directories renamedMODIFY: files/directories modified
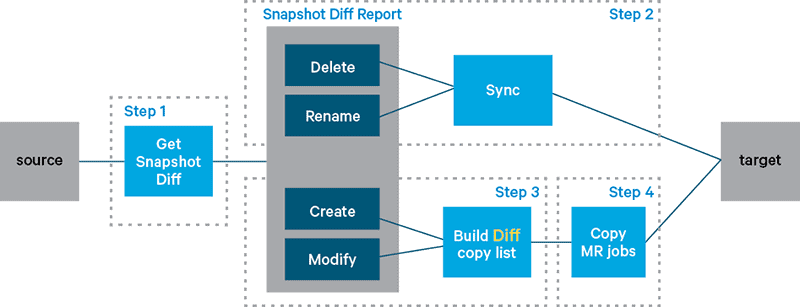
Here’s an example: Assume there are two snapshots in the source directory, s1 and s2, where s1 has been copied in the last backup cycle. You now try to copy s2. The HDFS-7535 solution runs the following steps as shown below:
- Generates a snapshot diff report between snapshot s1 and s2
- Applies the
RENAMEandDELETEoperations in the snapshot diff report to the target filesystem. This step is called the synchronization step. - Runs the default DistCp steps to copy from s2 to the target filesystem
After the synchronization step, the DistCp mappers in Step 3 find that the renamed files are the same between the source and the target, and does not copy them again.

The command-line instruction to run DistCp with the HDFS-7535 solution is:
distcp -update -diff -delete
where snapshotName1 is s1 and snapshotName2 is s2 in the above example.
Below we cover the benefits, assumptions/requirements, and limitations of HDFS-7535.
The benefits:
- This approach is especially useful when a big directory is copied and then renamed in the primary cluster. Without HDFS-7535, DistCp cannot detect the rename opportunity and thus the rename leads to large amounts of real-data copy of files that were already copied previously.
- It avoids the inconsistency caused by content changes made while distcp-ing, since it copies files from the read-only snapshot directory instead of the actual directory.
The assumptions/requirements:
- A single source directory parameter is passed to the
distcpcommand. - Both the source and the target filesystem must be of class
DistributedFileSystemand both the source and target directory must be snapshot-able. - Two snapshots (e.g., s1 and s2) have been created on the source dir, and contents of the first snapshot have been copied during a previous backup cycle.
- Snapshot s1 has been created at the target and has the same content as snapshot s1 at the source. No changes have been made on the target since s1 was taken, and all the files/directories in the target are the same as snapshot s1 in the source.
The limitations:
- After synchronizing the
RENAMEandDELETEoperations, the command runs the default DistCp steps, which still build the complete copy list of the source directory. Thus, it can still take a lot of time to build the copy list if the source directory is large, especially if it contains many subdirectories.
A Further Improvement: HDFS-8828
As mentioned previously, one limitation of HDFS-7535 is that building the copy list can still take a long time. (For example, there may be many getFileStatus RPC calls involved in this step.) For use cases that involve periodic backups, it’s not necessary to include files already copied to the copy list of a new backup cycle. The HDFS-8828 solution does exactly that (on top of HDFS-7535) by building a copy list (the diff copy list) containing only newly created and modified files/directories since the previous backup cycle. This approach can significantly reduce the processing time required to build the copy list.
The same assumptions/requirements of HDFS-7535 solutions apply. Here’s how it works:
- Gets the snapshot diff report between s1 and s2
- Applies the
RENAMEandDELETEoperations in the snapshot diff report to the target filesystem - Builds the diff copy list based on
MODIFYandCREATEoperations - Runs MapReduce jobs to do the copying
There is a slight change of command-line parameters versus the example described for HDFS-7535:
distcp -update -diff
Specifically, the -delete option is dropped. The -delete option is required in HDFS-7535 because it tells DistCp to remove files that exist in the target directory but not in the source directory. (Recall that the copy list built using HDFS-7535 contain the complete listing of all files in the source directory; -delete means to delete all files that exist in target directory but not in the complete list.) However, with HDFS-8828, as you no longer build a complete list of all files in the source directory, the -delete option is no longer needed. In fact, if you pass that option, an error is reported and the command aborts.
The benefits of this improvement include:
- A smaller number of files to work on in each backup cycle
- Less time is needed to build copy list
- Each DistCp mapper task has less work to do
- Reduces risk of memory overflow caused by a large directory
- A guarantee of backup consistency by copying from the snapshot
How to Use This Feature
To use this feature, you should first make sure all assumptions are met. Typical steps are described as follows:
- Create snapshot s0 in the source directory.
- Issue a default
distcpcommand that copies everything from s0 to the target directory (command line is likedistcp -update <sourceDir>/.snapshot/s0 <targetDir>). - Create snapshot s0 in the target dir.
- Make some changes in the source dir.
- Create a new snapshot s1, and issue a
distcpcommand likedistcp -update -diff s0 s1 <sourceDir> <targetDir>to copy all changes between s0 and s1 to the target directory. - Create a snapshot with the same name s1 in the target dir.
- Repeat steps 4 to 6 with a new snapshot name—for example, s2.
Challenges
The main challenge with this approach is how to build the diff copy list from the snapshot diff report. Multiple operations can apply to one file/directory, and the snapshot diff report doesn’t maintain the ordering of the operations. The algorithm needs to be carefully designed so as to not miss any cases.
Multiple operations can apply to the same file/directory, and different actions need to be taken for different combinations of operations. Table 1 contains the list of combinations of two operations to a file/directory, the corresponding entries in the snapshot diff report, and what extra actions (in addition to the general rules described below) need to be taken for this combination for building the final diff copy list. With this table, the combination of more than two operations can be easily derived.

General rules to build the diff copy list:
- Add all
CREATEandMODIFYitems into the copy list. And modify the item paths in Cases 2, 12, 13, 28, and 29 shown in Table 1. - For a created dir, recursively traverse it while excluding some items described in Case 4 in Table 1.
(Note: Whereas RENAME and DELETE items in the snapshot diff report are handled by the synchronization step of he HDFS-7535 solution, the diff copy list building process focuses on CREATE and MODIFY items.)
Corner Cases
There are still a few cases that can be confusing, so we’ve listed them here with the corresponding contents in a snapshot diff report for your reference. The CREATE, MODIFY, RENAME, and DELETE operations are represented as as +, M, R, and -, respectively.
Case 1
Create a file/dir, then move it into a created dir.
mkdir ./c mkdir ./foo mv ./foo ./c
Snapshot diff report:
+ ./c
(Note: Only one CREATE item instead of two appears in the report.)
Case 2
Move an existing dir into a created dir, then delete it and create a new one with the same name under the created dir.
mkdir c mv ./foo ./c rm -r ./c/foo mkdir ./c/foo
Snapshot diff report:
+ ./c - ./foo< /pre>
(Note: Only one CREATE item and one DELETE item appear in the report.)
Case 3
Subdirectories are renamed on multiple levels.
Assume you have ./foo/bar/f1 in the source directory.
modify ./foo/bar/f1 mv ./foo/bar ./foo/bar1 mv ./foo ./foo1
Snapshot diff report:
R ./foo ./foo1 M ./foo R ./foo/bar ./foo1/bar1 M ./foo/bar/f1
(Note: There are two RENAME operations in the snapshot diff report. Both are consumed by HDFS-7535 solution when doing synchronization, but only the second one is consumed by the HDFS-8828 solution when modifying the target path of MODIFY for building the copy list.)
Performance and Experiments
This approach can improve DistCp performance twofold because building the copy list takes less time, and because each DistCp mapper task has less work to do.
For list building, although we don’t have general statistics about the lower percentage of file changes needed during a specific time, in one observed case only 1,000 files changed during a single backup cycle (12 hours) for a directory containing 1.6 million files. In that case, building the list took just 1 minute.
It is worth mentioning that HADOOP-11827 speeds up copy-list building by using multiple threads. And it can work with HDFS-8828 to make the copy list building even faster, by increasing the number of threads that build the copy list.
This solution makes MR jobs only process the changed files/directories between snapshots instead of all files, since comparing each file to check if it needs to be copied is time-consuming when there are a huge number of files in the source directory.
Conclusion
At this point, we hope you now understand how DistCp works, the source of some of its performance issues, and how the community has tried to address them via HDFS-7535 and HDFS-8828. For more complete information, see the DistCp docs for CDH.
Yufei Gu is a Research Assistant at the University of Texas at Dallas, and was a Software Engineering Intern at Cloudera during Summer 2015.
Yongjun Zhang is a Software Engineer at Cloudera, and an Apache Hadoop committer.
Editor's Choice


why do we need snapshot on target cluster? Isn’t source snapshot s1,s2 sufficient to generate copy list.