

Learn about the near real-time data ingest architecture for transforming and enriching data streams using Apache Flume, Apache Kafka, and RocksDB at Santander UK.
Cloudera Professional Services has been working with Santander UK to build a near real-time (NRT) transactional analytics system on Apache Hadoop. The objective is to capture, transform, enrich, count, and store a transaction within a few seconds of a card purchase taking place. The system receives the bank’s retail customer card transactions and calculates the associated trend information aggregated by account holder and over a number of dimensions and taxonomies. This information is then served securely to Santander’s “Spendlytics” app (see below) to enable customers to analyze their latest spending patterns.
Apache HBase was chosen as the underlying storage solution because of its ability to support high-throughput random writes, and low-latency random reads. However, the NRT requirement ruled out performing transformations and enrichment of the transactions in batch, so these have to be done while the transactions are streamed into HBase. This includes transforming messages from XML to Avro and enriching them with trend-able information, such as brand and merchant information.
This post describes how Santander use Apache Flume, Apache Kafka, and RocksDB to transform, enrich, and stream transactions into HBase. This is an implementation of the NRT Event Processing with External Context streaming pattern described by Ted Malaska in this post.
Flafka
The first decision Santander had to make was how best to stream data into HBase. Flume is almost always the best choice for streaming ingestion into Hadoop given its simplicity, reliability, rich array of sources and sinks, and inherent scalability.
Recently, excellent integration to Kafka has been added leading to the inevitably named Flafka. Flume can natively provide guaranteed event delivery through its file channel, but the ability to replay events and the added flexibility and future-proofing Kafka brings were key drivers for the integration.
In this architecture, Santander use Kafka channels to provide a reliable, self-balancing, and scalable ingestion buffer in which all transformations and processing is represented in chained Kafka topics. In particular, we make extensive use of Flafka’s source and sink, and Flume’s ability to perform in-flight processing using Interceptors. This prevented us from having to code our own Kafka producer and consumer, and allowed Santander to take full advantage of Cloudera Manager to configure, deploy, and monitor the agents and brokers.
Transformation
Transactions captured by the core banking systems are delivered to Flume as XML messages, having been read from the source database via log replication. (Tailing a database log into Kafka topics in this way is an increasingly common pattern and combined with log compaction, can give a “most-recent view” of the database for change data capture use cases.)
Flume stores these XML messages in a “raw” Kafka topic. From here, and as a precursor to all other processing, it was decided to transform the semi-structured XML into structured binary records to facilitate standardised downstream processing. This processing is performed by a custom Flume Interceptor that transforms the XML messages into a generic Avro representation, applying specific types where appropriate and falling back to a string representation where not. All subsequent NRT processing then stores derived results in Avro in dedicated Kafka topics, making it easy to tap into the stream and get an event feed at any point in the processing chain.
If more complex event processing were required–for example aggregations with Spark Streaming–it would be a trivial matter to consume one or more of these topics and publish to new derived topics. (Apache Avro is a natural choice for this format: it is a compact binary protocol supporting schema evolution, has a flexible schema definition, and is supported throughout the Hadoop stack. Avro is rapidly becoming a de facto standard for interim and general data storage in an enterprise data hub and is perfectly placed for transformation into Apache Parquet for analytics workloads.)
Enrichment
The inspiration for the design of the streaming enrichment solution came from an O’Reilly Radar post written by Jay Kreps. In his post, Jay describes the benefits of using a local store to enable a stream processor to query or modify a local state in response to its input, as opposed to making remote calls to a distributed database.
At Santander, we adapted this pattern to provide local reference stores that are used to query and enrich transactions as they stream through Flume. Why not just use HBase as the reference store? Well, a typical pattern for this type of problem is to simply store the state in HBase and have the enrichment mechanism query it directly. We decided against this approach for a couple of reasons. First, the reference data is relatively small and would fit into a single HBase region, probably causing a region hotspot. Second, HBase serves the customer-facing Spendlytics app and Santander did not want the additional load to affect app latency, or vice versa. This is also the reason why we decided not to use HBase to even bootstrap the local stores on startup.
So, by providing each Flume Agent with a fast local store to enrich in-flight events, Santander is able to give better performance guarantees for both in-flight enrichment and the Spendlytics app. We decided to use RocksDB to implement the local stores because it is able to provide fast access to large amounts of off-heap data (eliminating the burden on GC), and the fact that it has a Java API to make it easier to use from a custom Flume Interceptor. This approach saved us from having to code our own off-heap store. RocksDB can easily be swapped out for another local store implementation, but in this case it was a perfect fit for Santander’s use case.
The custom Flume enrichment Interceptor implementation processes events from the upstream “transformed” topic, queries its local store to enrich them, and writes the results to downstream Kafka topics depending on the outcome. This process is illustrated in more detail below.
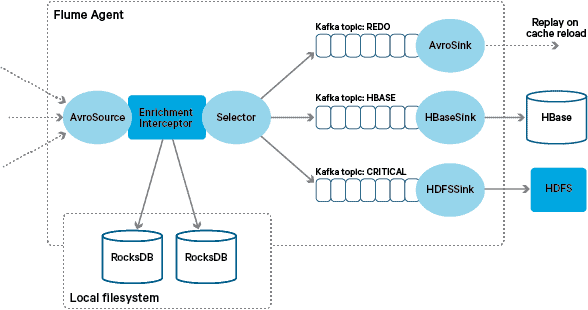
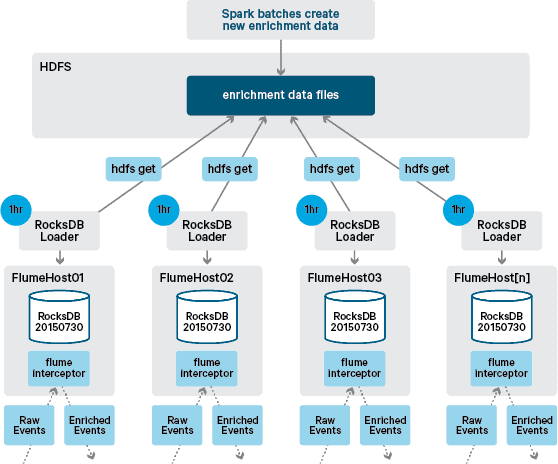
At this point you may be wondering: With no HBase-provided persistence, how are local stores generated?The reference data comprises a number of different datasets that need to be joined together. These datasets are refreshed in HDFS on a daily basis and form the input to a scheduled Apache Spark application, which generates the RocksDB stores. Newly generated RocksDB stores are staged in HDFS until they are downloaded by the Flume Agents to ensure that the event stream is being enriched with the latest information.
Ideally, we wouldn’t have to wait for these datasets to all be available in HDFS before they could be processed. If this were the case, then reference data updates could be streamed through the Flafka pipeline to continuously maintain the local reference data state.
In our initial design we had planned to write and schedule via cron a script to poll HDFS to check for new versions of the RocksDB stores, downloading them from HDFS when available. Although due to the internal controls and governance of Santander’s production environments, this mechanism had to be incorporated into the same Flume Interceptor that is used to perform the enrichment (it checks for updates once per hour, so its not an expensive operation). When a new version of the store is available, a task is dispatched to a worker thread to download the new store from HDFS and load it into RocksDB. This process happens in the background while the enrichment Interceptor continues to process the stream. Once the new version of the store is loaded into RocksDB, the Interceptor switches to the latest version, and the expired store is deleted. The same mechanism is used to bootstrap the RocksDB stores from a cold startup before the Interceptor starts attempting to enrich events.
Successfully enriched messages are written to a Kafka topic to be idempotently written to HBase using the HBaseEventSerializer.
While the event stream is processed on a continuous basis, new versions of the local store can only be generated daily. Immediately after a new version of the local store has been loaded by Flume it is considered fresh,” although it becomes increasingly stale prior to the availability of a new version. Consequently, the number of “cache misses” increase until a newer version of the local store is available. For example, new and updated brand and merchant information can be added to the reference data, but until it is made available to Flume’s enrichment Interceptor transactions can fail to be enriched, or be enriched with out-of-date information that later has to be reconciled after it has been persisted in HBase.
To handle this case, cache misses (events that fail to be enriched) are written to a “redo” Kafka topic using a Flume Selector. The redo topic is then replayed back into the enrichment Interceptor’s source topic when a new local store is available.
In order to prevent “poison messages” (events that continuously fail enrichment), we decided to add a counter to an event’s header before adding it to the redo topic. Events that repeatedly appear on that topic are eventually redirected to a “critical” topic, which is written to HDFS for later inspection and remediation. This approach is illustrated in the first diagram.
Conclusion
To summarize the main take-away points from this post:
- Using a chain of Kafka topics to store intermediate shared data as part of your ingest pipeline is an effective pattern.
- You have multiple options for persisting and querying state or reference data in your NRT ingest pipeline. Favor HBase for this purpose as the common pattern when the supplementary data is large, but consider the use of embedded local stores (such as RocksDB) or JVM memory for when using HBase is not practical.
- Failure handling is important. (See #1 for help on that.)
In a follow-up post, we will describe how we make use of HBase coprocessors to provide per-customer aggregations of historical purchasing trends, and how offline transactions are processed in batch using (Cloudera Labs project) SparkOnHBase (which was recently committed into the HBase trunk). We will also describe how the solution was designed to meet the customer’s cross-datacenter, high-availability requirements.
James Kinley, Ian Buss, and Rob Siwicki are Solution Architects at Cloudera.
Editor's Choice

